Время на прочтение
4 мин
Количество просмотров 247K
Привет всем!
Сразу хочется отметить, что данная статья написана исключительно для людей, начинающих свой путь в изучении SQL и оконных функций. Здесь могут быть не разобраны сложные применения функций и могут не использоваться сложные формулировки определений — все написано максимально простым языком для базового понимания.
P.S. Если автор что-то не разобрал и не написал, значит он посчитал это не обязательным в рамках этой статьи)))
Для примеров будем использовать небольшую таблицу, которая показывает оценки учеников по разным предметам. В БД табличка выглядит следующим образом
--создание таблицы
create table student_grades (
name varchar,
subject varchar,
grade int);
-- наполнение таблицы данными
insert into student_grades (
values
('Петя', 'русский', 4),
('Петя', 'физика', 5),
('Петя', 'история', 4),
('Маша', 'математика', 4),
('Маша', 'русский', 3),
('Маша', 'физика', 5),
('Маша', 'история', 3));
--запрос всех данных из таблицы
select *
from student_grades;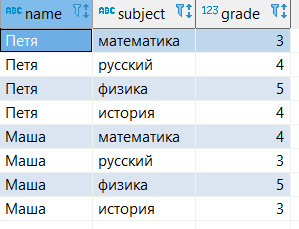
SQL часто используется для вычислений в данных различных метрик или агрегаций значений по измерениям. Помимо функций агрегации для этого широко используются оконные функции.
Оконная функция в SQL — функция, которая работает с выделенным набором строк (окном, партицией) и выполняет вычисление для этого набора строк в отдельном столбце.
Партиции (окна из набора строк) — это набор строк, указанный для оконной функции по одному из столбцов или группе столбцов таблицы. Партиции для каждой оконной функции в запросе могут быть разделены по различным колонкам таблицы.

В чем заключается главное отличие оконных функций от функций агрегации с группировкой?
При использовании агрегирующих функций предложение GROUP BY сокращает количество строк в запросе с помощью их группировки.
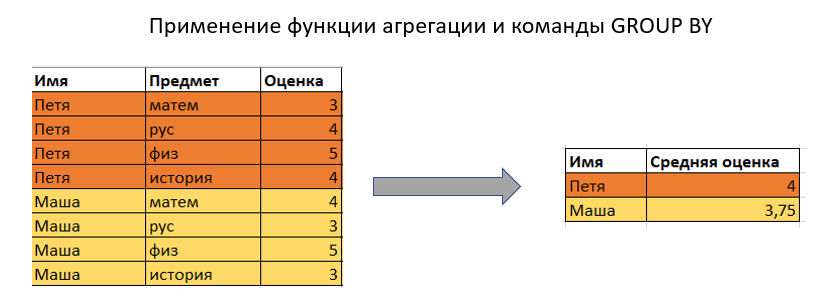
При использовании оконных функций количество строк в запросе не уменьшается по сравнении с исходной таблицей.

Порядок расчета оконных функций в SQL запросе
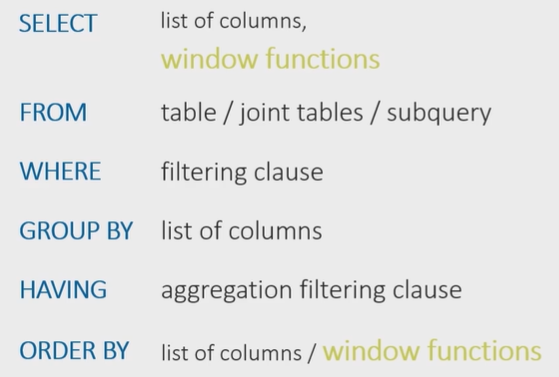
Сначала выполняется команда выборки таблиц, их объединения и возможные подзапросы под командой FROM.
Далее выполняются условия фильтрации WHERE, группировки GROUP BY и возможная фильтрация c HAVING
Только потом применяется команда выборки столбцов SELECT и расчет оконных функций под выборкой.
После этого идет условие сортировки ORDER BY, где тоже можно указать столбец расчета оконной функции для сортировки.
Здесь важно уточнить, что партиции или окна оконных функций создаются после разделения таблицы на группы с помощью команды GROUP BY, если эта команда используется в запросе.
Синтаксис оконных функций
Синтаксис оконных функций вне зависимости от их класса будет так или иначе состоять из идентичных команд.
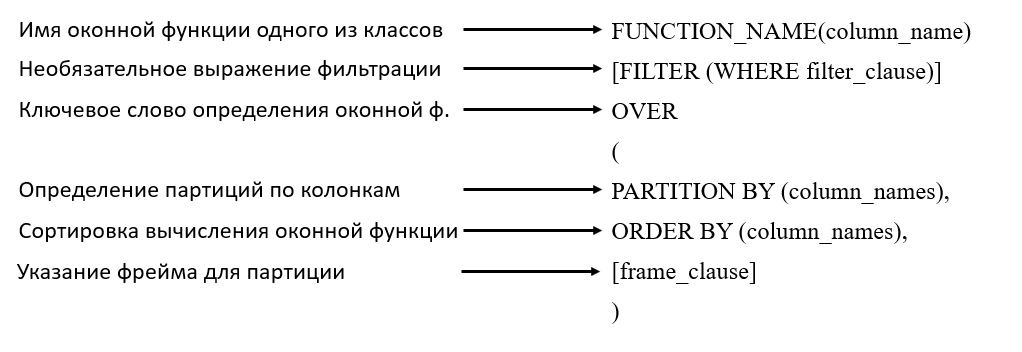
Оконные функции можно прописывать как под командой SELECT, так и в отдельном ключевом слове WINDOW, где окну дается алиас (псевдоним), к которому можно обращаться в SELECT выборке.

Классы Оконных функций
Множество оконных функций можно разделять на 3 класса:
-
Агрегирующие (Aggregate)
-
Ранжирующие (Ranking)
-
Функции смещения (Value)

Агрегирующие:
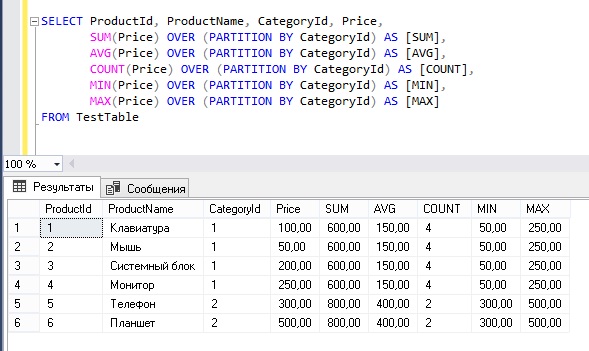
Можно применять любую из агрегирующих функций — SUM, AVG, COUNT, MIN, MAX
select name, subject, grade,
sum(grade) over (partition by name) as sum_grade,
avg(grade) over (partition by name) as avg_grade,
count(grade) over (partition by name) as count_grade,
min(grade) over (partition by name) as min_grade,
max(grade) over (partition by name) as max_grade
from student_grades;
Ранжирующие:
В ранжирующих функция под ключевым словом OVER обязательным идет указание условия ORDER BY, по которому будет происходить сортировка ранжирования.
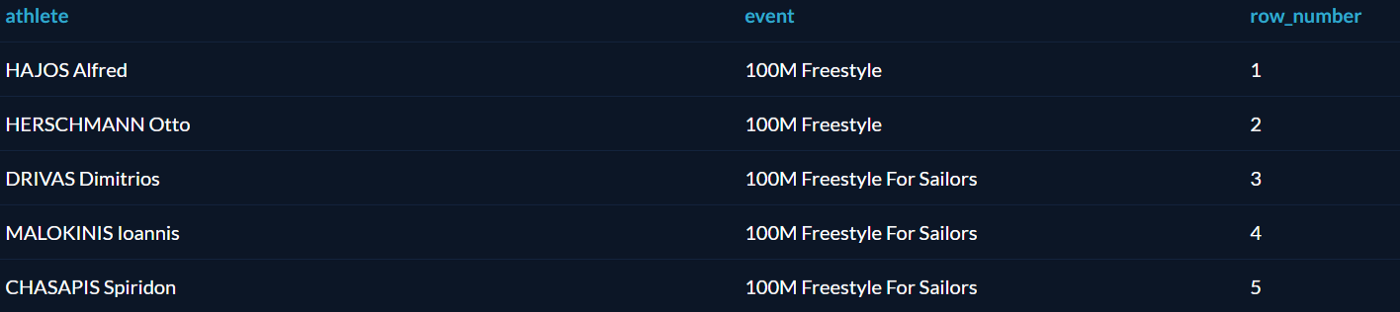
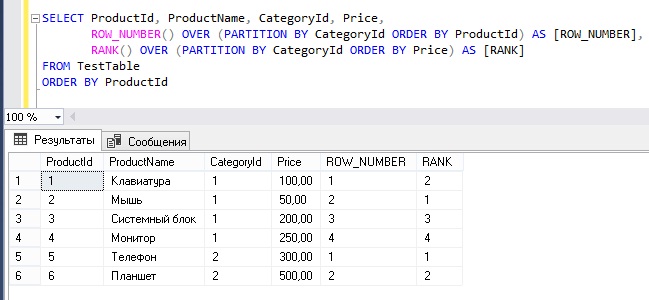
ROW_NUMBER() — функция вычисляет последовательность ранг (порядковый номер) строк внутри партиции, НЕЗАВИСИМО от того, есть ли в строках повторяющиеся значения или нет.
RANK() — функция вычисляет ранг каждой строки внутри партиции. Если есть повторяющиеся значения, функция возвращает одинаковый ранг для таких строчек, пропуская при этом следующий числовой ранг.
DENSE_RANK() — то же самое что и RANK, только в случае одинаковых значений DENSE_RANK не пропускает следующий числовой ранг, а идет последовательно.
select name, subject, grade,
row_number() over (partition by name order by grade desc),
rank() over (partition by name order by grade desc),
dense_rank() over (partition by name order by grade desc)
from student_grades;
Про NULL в случае ранжирования:
Для SQL пустые NULL значения будут определяться одинаковым рангом
Функции смещения:
Это функции, которые позволяют перемещаясь по выделенной партиции таблицы обращаться к предыдущему значению строки или крайним значениям строк в партиции.
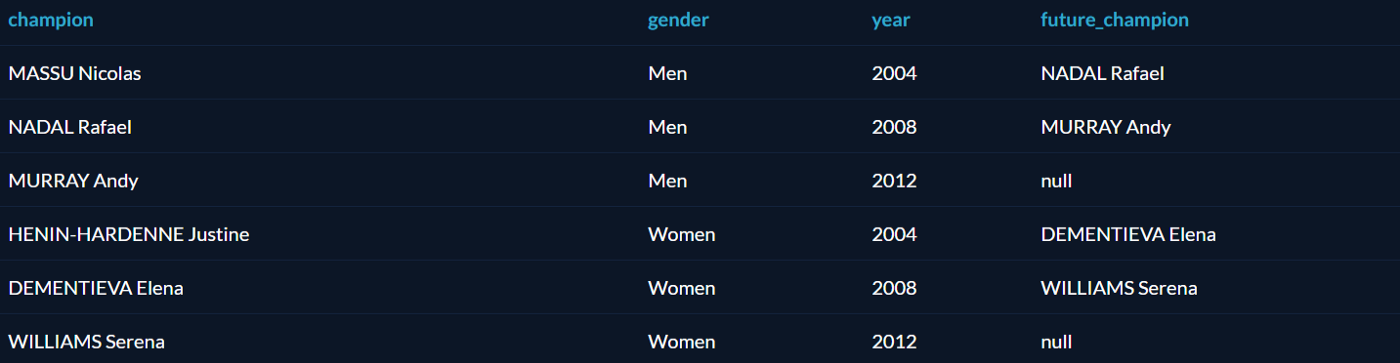
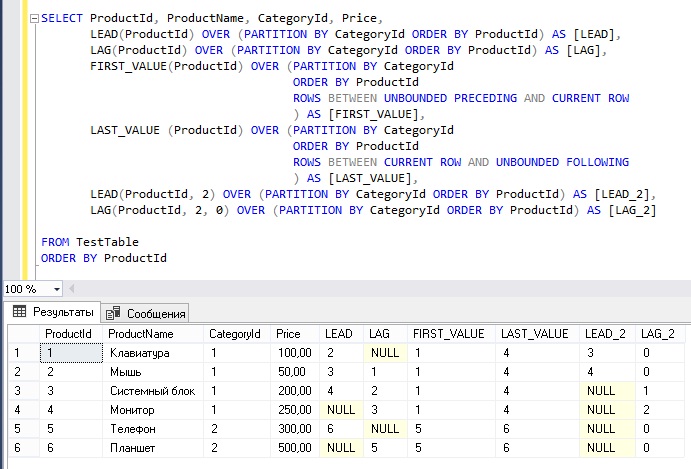
LAG() — функция, возвращающая предыдущее значение столбца по порядку сортировки.
LEAD() — функция, возвращающая следующее значение столбца по порядку сортировки.
На простом примере видно, как можно в одной строке получить текущую оценку, предыдущую и следующую оценки Пети в четвертях.
--создание таблицы
create table grades_quartal (
name varchar,
quartal varchar,
subject varchar,
grade int);
--наполнение таблицы данными
insert into grades_quartal (
values
('Петя', '1 четверть', 'физика', 4),
('Петя', '2 четверть', 'физика', 3),
('Петя', '3 четверть', 'физика', 4),
('Петя', '4 четверть', 'физика', 5)
);
--запрос всех данных из таблицы
select *
from grades_quartal;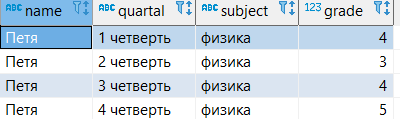
select name, quartal, subject, grade,
lag(grade) over (order by quartal) as previous_grade,
lead(grade) over (order by quartal) as next_grade
from grades_quartal;
FIRST_VALUE()/LAST_VALUE() — функции возвращающие первое или последнее значение столбца в указанной партиции. В качестве аргумента указывает столбец, значение которого нужно вернуть. В оконной функции под словом OVER обязательное указание ORDER BY условия.
В следующей версии статьи разберем отдельно такое понятие как фрейм окна функции или window frame и рассмотрим на простых примерах как он используется.
Telegram канал про аналитику данных и бизнес-анализ
Оконные функции — это мощнейший инструмент аналитика, который с легкостью помогает решать множество задач.
Если вам нужно произвести вычисление над заданным набором строк, объединенных каким-то одним признаком, например идентификатором клиента, вам на помощь придут именно они.
Можно сравнить их с агрегатными функциями, но, в отличие от обычной агрегатной функции, при использовании оконной функции несколько строк не группируются в одну, а продолжают существовать отдельно. При этом результаты работы оконных функций просто добавляются к результирующей выборке как еще одно поле. Этот функционал очень полезен для построения аналитических отчетов, расчета скользящего среднего и нарастающих итогов, а также для расчетов различных моделей атрибуции.
Принцип работы
У вас может возникнуть вопрос – «Что значит оконные?»
При обычном запросе, все множество строк обрабатывается как бы единым «цельным куском», для которого считаются агрегаты. А при использовании оконных функций, запрос делится на части (окна) и уже для каждой из отдельных частей считаются свои агрегаты.

Синтаксис
Окно определяется с помощью обязательной инструкции OVER(). Давайте рассмотрим синтаксис этой инструкции:
SELECT Название функции (столбец для вычислений) OVER ( PARTITION BY столбец для группировки ORDER BY столбец для сортировки ROWS или RANGE выражение для ограничения строк в пределах группы )
Теперь разберем как поведет себя множество строк при использовании того или иного ключевого слова функции. А тренироваться будем на простой табличке содержащей дату, канал с которого пришел пользователь и количество конверсий:

OVER()
Откроем окно при помощи OVER() и просуммируем столбец «Conversions»:
SELECT Date , Medium , Conversions , SUM(Conversions) OVER() AS 'Sum' FROM Orders

Мы использовали инструкцию OVER() без предложений. В таком варианте окном будет весь набор данных и никакая сортировка не применяется. Появился новый столбец «Sum» и для каждой строки выводится одно и то же значение 14. Это сквозная сумма всех значений колонки «Conversions».
PARTITION BY
Теперь применим инструкцию PARTITION BY, которая определяет столбец, по которому будет производиться группировка и является ключевой в разделении набора строк на окна:
SELECT Date , Medium , Conversions , SUM(Conversions) OVER(PARTITION BY Date) AS 'Sum' FROM Orders

Инструкция PARTITION BY сгруппировала строки по полю «Date». Теперь для каждой группы рассчитывается своя сумма значений столбца «Conversions».
ORDER BY
Попробуем отсортировать значения внутри окна при помощи ORDER BY:
SELECT Date , Medium , Conversions , SUM(Conversions) OVER(PARTITION BY Date ORDER BY Medium) AS 'Sum' FROM Orders

К предложению PARTITION BY добавилось ORDER BY по полю «Medium». Таким образом мы указали, что хотим видеть сумму не всех значений в окне, а для каждого значения «Conversions» сумму со всеми предыдущими. То есть мы посчитали нарастающий итог.
ROWS или RANGE
Инструкция ROWS позволяет ограничить строки в окне, указывая фиксированное количество строк, предшествующих или следующих за текущей.
Инструкция RANGE, в отличие от ROWS, работает не со строками, а с диапазоном строк в инструкции ORDER BY. То есть под одной строкой для RANGE могут пониматься несколько физических строк одинаковых по рангу.
Обе инструкции ROWS и RANGE всегда используются вместе с ORDER BY.
В выражении для ограничения строк ROWS или RANGE также можно использовать следующие ключевые слова:
- UNBOUNDED PRECEDING — указывает, что окно начинается с первой строки группы;
- UNBOUNDED FOLLOWING – с помощью данной инструкции можно указать, что окно заканчивается на последней строке группы;
- CURRENT ROW – инструкция указывает, что окно начинается или заканчивается на текущей строке;
- BETWEEN «граница окна» AND «граница окна» — указывает нижнюю и верхнюю границу окна;
- «Значение» PRECEDING – определяет число строк перед текущей строкой (не допускается в предложении RANGE).;
- «Значение» FOLLOWING — определяет число строк после текущей строки (не допускается в предложении RANGE).
Разберем на примере:
SELECT Date , Medium , Conversions , SUM(Conversions) OVER(PARTITION BY Date ORDER BY Conversions ROWS BETWEEN CURRENT ROW AND 1 FOLLOWING) AS 'Sum' FROM Orders

В данном случае сумма рассчитывается по текущей и следующей ячейке в окне. А последняя строка в окне имеет то же значение, что и столбец «Conversions», потому что больше не с чем складывать.
Комбинируя ключевые слова, вы можете подогнать диапазон работы оконной функции под вашу специфическую задачу.
Виды функций
Оконные функции можно подразделить на следующие группы:
- Агрегатные функции;
- Ранжирующие функции;
- Функции смещения;
- Аналитические функции.
В одной инструкции SELECT с одним предложением FROM можно использовать сразу несколько оконных функций. Давайте подробно разберем каждую группу и пройдемся по основным функциям.
Агрегатные функции
Агрегатные функции – это функции, которые выполняют на наборе данных арифметические вычисления и возвращают итоговое значение.
- SUM – возвращает сумму значений в столбце;
- COUNT — вычисляет количество значений в столбце (значения NULL не учитываются);
- AVG — определяет среднее значение в столбце;
- MAX — определяет максимальное значение в столбце;
- MIN — определяет минимальное значение в столбце.
Пример использования агрегатных функций с оконной инструкцией OVER:
SELECT Date , Medium , Conversions , SUM(Conversions) OVER(PARTITION BY Date) AS 'Sum' , COUNT(Conversions) OVER(PARTITION BY Date) AS 'Count' , AVG(Conversions) OVER(PARTITION BY Date) AS 'Avg' , MAX(Conversions) OVER(PARTITION BY Date) AS 'Max' , MIN(Conversions) OVER(PARTITION BY Date) AS 'Min' FROM Orders

Ранжирующие функции
Ранжирующие функции – это функции, которые ранжируют значение для каждой строки в окне. Например, их можно использовать для того, чтобы присвоить порядковый номер строке или составить рейтинг.
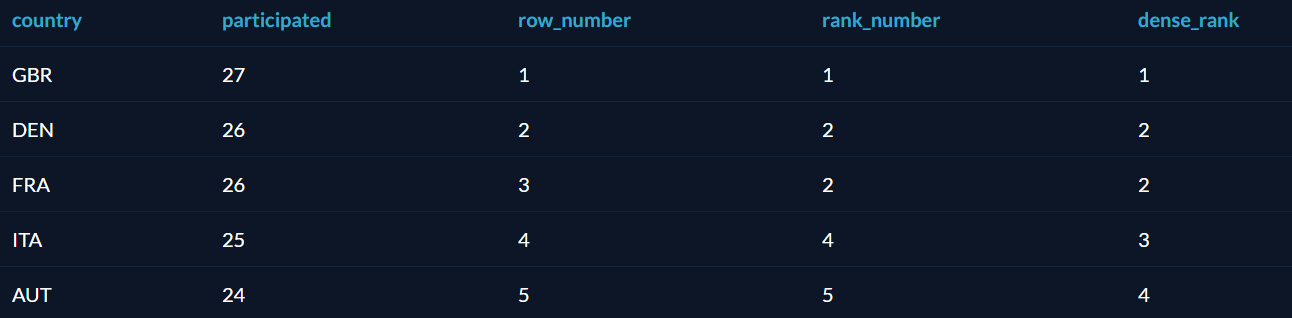
- ROW_NUMBER – функция возвращает номер строки и используется для нумерации;
- RANK — функция возвращает ранг каждой строки. В данном случае значения уже анализируются и, в случае нахождения одинаковых, возвращает одинаковый ранг с пропуском следующего значения;
- DENSE_RANK — функция возвращает ранг каждой строки. Но в отличие от функции RANK, она для одинаковых значений возвращает ранг, не пропуская следующий;
- NTILE – это функция, которая позволяет определить к какой группе относится текущая строка. Количество групп задается в скобках.
SELECT Date , Medium , Conversions , ROW_NUMBER() OVER(PARTITION BY Date ORDER BY Conversions) AS 'Row_number' , RANK() OVER(PARTITION BY Date ORDER BY Conversions) AS 'Rank' , DENSE_RANK() OVER(PARTITION BY Date ORDER BY Conversions) AS 'Dense_Rank' , NTILE(3) OVER(PARTITION BY Date ORDER BY Conversions) AS 'Ntile' FROM Orders

Функции смещения
Функции смещения – это функции, которые позволяют перемещаться и обращаться к разным строкам в окне, относительно текущей строки, а также обращаться к значениям в начале или в конце окна.
- LAG или LEAD – функция LAG обращается к данным из предыдущей строки окна, а LEAD к данным из следующей строки. Функцию можно использовать для того, чтобы сравнивать текущее значение строки с предыдущим или следующим. Имеет три параметра: столбец, значение которого необходимо вернуть, количество строк для смещения (по умолчанию 1), значение, которое необходимо вернуть если после смещения возвращается значение NULL;
- FIRST_VALUE или LAST_VALUE — с помощью функции можно получить первое и последнее значение в окне. В качестве параметра принимает столбец, значение которого необходимо вернуть.
SELECT Date , Medium , Conversions , LAG(Conversions) OVER(PARTITION BY Date ORDER BY Date) AS 'Lag' , LEAD(Conversions) OVER(PARTITION BY Date ORDER BY Date) AS 'Lead' , FIRST_VALUE(Conversions) OVER(PARTITION BY Date ORDER BY Date) AS 'First_Value' , LAST_VALUE(Conversions) OVER(PARTITION BY Date ORDER BY Date) AS 'Last_Value' FROM Orders

Аналитические функции
Аналитические функции — это функции которые возвращают информацию о распределении данных и используются для статистического анализа.
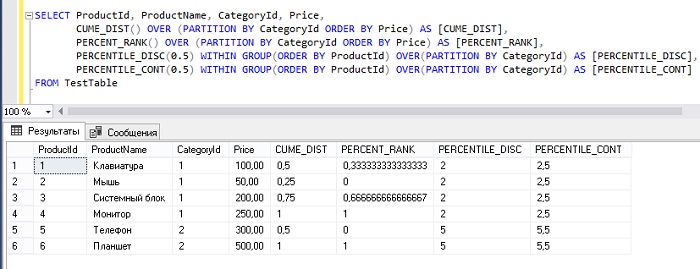
- CUME_DIST — вычисляет интегральное распределение (относительное положение) значений в окне;
- PERCENT_RANK — вычисляет относительный ранг строки в окне;
- PERCENTILE_CONT — вычисляет процентиль на основе постоянного распределения значения столбца. В качестве параметра принимает процентиль, который необходимо вычислить (в этой статье я рассказываю как посчитать медиану, благодаря этой функции);
- PERCENTILE_DISC — вычисляет определенный процентиль для отсортированных значений в наборе данных. В качестве параметра принимает процентиль, который необходимо вычислить.
Важно! У функций PERCENTILE_CONT и PERCENTILE_DISC, столбец, по которому будет происходить сортировка, указывается с помощью ключевого слова WITHIN GROUP.
SELECT Date , Medium , Conversions , CUME_DIST() OVER(PARTITION BY Date ORDER BY Conversions) AS 'Cume_Dist' , PERCENT_RANK() OVER(PARTITION BY Date ORDER BY Conversions) AS 'Percent_Rank' , PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY Conversions) OVER(PARTITION BY Date) AS 'Percentile_Cont' , PERCENTILE_DISC(0.5) WITHIN GROUP (ORDER BY Conversions) OVER(PARTITION BY Date) AS 'Percentile_Disc' FROM Orders

Кейс. Модели атрибуции
Благодаря модели атрибуции можно обоснованно оценить вклад каждого канала в достижение конверсии. Давайте попробуем посчитать две разных модели атрибуции с помощью оконных функций.
У нас есть таблица с id посетителя (им может быть Client ID, номер телефона и тп.), датами и количеством посещений сайта, а также с информацией о достигнутых конверсиях.

Первый клик
В Google Analytics стандартной моделью атрибуции является последний непрямой клик. И в данном случае 100% ценности конверсии присваивается последнему каналу в цепочке взаимодействий.
Попробуем посчитать модель по первому взаимодействию, когда 100% ценности конверсии присваивается первому каналу в цепочке при помощи функции FIRST_VALUE.
SELECT Date , Client_ID , Medium , FIRST_VALUE(Medium) OVER(PARTITION BY Client_ID ORDER BY Date) AS 'First_Click' , Sessions , Conversions FROM Orders

Рядом со столбцом «Medium» появился новый столбец «First_Click», в котором указан канал в первый раз приведший посетителя к нам на сайт и вся ценность зачтена данному каналу.
Произведем агрегацию и получим отчет.
WITH First AS ( SELECT Date , Client_ID , Medium , FIRST_VALUE(Medium) OVER(PARTITION BY Client_ID ORDER BY Date) AS 'First_Click' , Sessions , Conversions FROM Orders ) SELECT First_Click , SUM(Conversions) AS 'Conversions' FROM First GROUP BY First_Click

С учетом давности взаимодействий
В этом случае работает правило: чем ближе к конверсии находится точка взаимодействия, тем более ценной она считается. Попробуем рассчитать эту модель при помощи функции DENSE_RANK.
SELECT Date , Client_ID , Medium -- Присваиваем ранг в зависимости от близости к дате конверсии , DENSE_RANK() OVER(PARTITION BY Client_ID ORDER BY Date) AS 'Ranks' , Sessions , Conversions FROM Orders

Рядом со столбцом «Medium» появился новый столбец «Ranks», в котором указан ранг каждой строки в зависимости от близости к дате конверсии.
Теперь используем этот запрос для того, чтобы распределить ценность равную 1 (100%) по всем точкам на пути к конверсии.
SELECT
Date
, Client_ID
, Medium
-- Делим ранг определенной строки на сумму рангов по пользователю
, ROUND(CAST(DENSE_RANK() OVER(PARTITION BY Client_ID ORDER BY Date) AS FLOAT) / CAST(SUM(ranks) OVER(PARTITION BY Client_ID) AS FLOAT), 2) AS 'Time_Decay'
, Sessions
, Conversions
FROM (
SELECT
Date
, Client_ID
, Medium
-- Присваиваем ранг в зависимости от близости к дате конверсии
, DENSE_RANK() OVER(PARTITION BY Client_ID ORDER BY Date) AS 'Ranks'
, Sessions
, Conversions
FROM Orders
) rank_table

Рядом со столбцом «Medium» появился новый столбец «Time_Decay» с распределенной ценностью.
И теперь, если сделать агрегацию, можно увидеть как распределилась ценность по каналам.
WITH Ranks AS (
SELECT
Date
, Client_ID
, Medium
-- Делим ранг определенной строки на сумму рангов по пользователю
, ROUND(CAST(DENSE_RANK() OVER(PARTITION BY Client_ID ORDER BY Date) AS FLOAT) / CAST(SUM(ranks) OVER(PARTITION BY Client_ID) AS FLOAT), 2) AS 'Time_Decay'
, Sessions
, Conversions
FROM (
SELECT
Date
, Client_ID
, Medium
-- Присваиваем ранг в зависимости от близости к дате конверсии
, DENSE_RANK() OVER(PARTITION BY Client_ID ORDER BY Date) AS 'Ranks'
, Sessions
, Conversions
FROM Orders
) rank_table
)
SELECT
Medium
, SUM(Time_Decay) AS 'Value'
, SUM(Conversions) AS 'Conversions'
FROM Ranks
GROUP BY Medium
ORDER BY Value DESC

Из получившегося отчета видно, что самым весомым каналом является канал «cpc», а канал «cpa», который был бы исключен при применении стандартной модели атрибуции, тоже получил свою долю при распределении ценности.
Полезные ссылки:
- SELECT — предложение OVER (Transact-SQL)
- Как работать с оконными функциями в Google BigQuery — подробное руководство
- Модель атрибуции на основе онлайн/офлайн данных в Google BigQuery
- Об авторе
- Свежие записи

Многие разработчики, даже давно знакомые с SQL, не понимают оконные функции, считая их какой-то особой магией для избранных. И, хотя реализация оконных функций поддерживается с SQL Server 2005, кто-то до сих пор «копипастит» их со StackOverflow, не вдаваясь в детали. Этой статьёй мы попытаемся развенчать миф о неприступности этой функциональности SQL и покажем несколько примеров работы оконных функций на реальном датасете.
Почему не GROUP BY и не JOIN
Сразу проясним, что оконные функции — это не то же самое, что GROUP BY. Они не уменьшают количество строк, а возвращают столько же значений, сколько получили на вход. Во-вторых, в отличие от GROUP BY, OVER может обращаться к другим строкам. И в-третьих, они могут считать скользящие средние и кумулятивные суммы.
[badge style=»blue»]Примечание[/badge] Оконные функции не изменяют выборку, а только добавляют некоторую дополнительную информацию о ней. Для простоты понимания можно считать, что SQL сначала выполняет весь запрос (кроме сортировки и limit), а уже потом считает значения окна.
Окей, с GROUP BY разобрались. Но в SQL практически всегда можно пойти несколькими путями. К примеру, может возникнуть желание использовать подзапросы или JOIN. Конечно, JOIN по производительности предпочтительнее подзапросов, а производительность конструкций JOIN и OVER окажется одинаковой. Но OVER даёт больше свободы, чем жёсткий JOIN. Да и объём кода в итоге окажется гораздо меньше.
Для начала
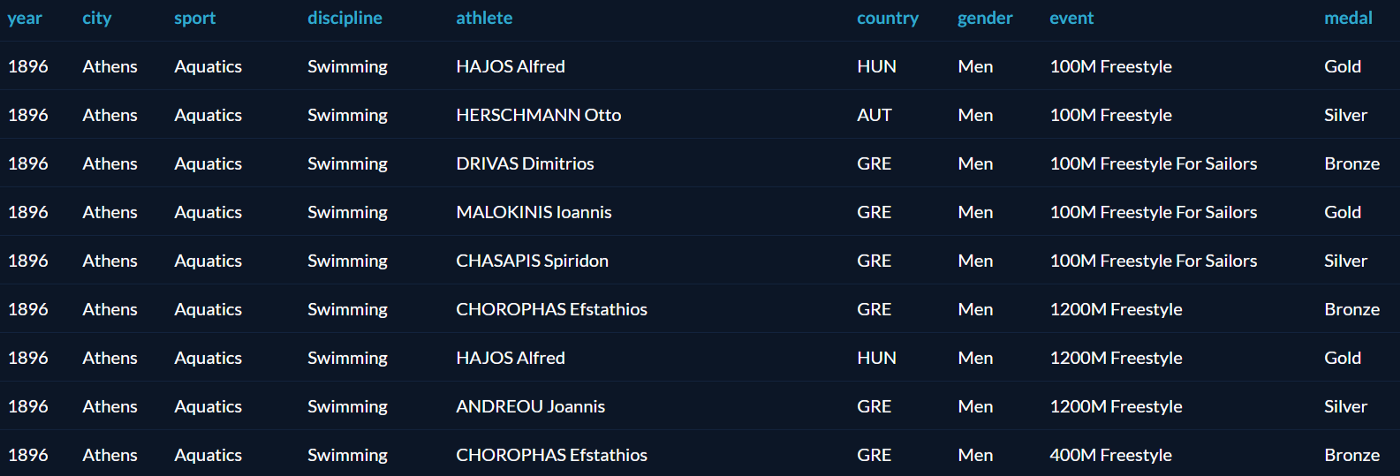
Оконные функции начинаются с оператора OVER и настраиваются с помощью трёх других операторов: PARTITION BY, ORDER BY и ROWS. Про ORDER BY, PARTITION BY и его вспомогательные операторы LAG, LEAD, RANK мы расскажем подробнее.
Все примеры будут основаны на датасете олимпийских медалистов от Datacamp. Таблица называется summer_medals и содержит результаты Олимпиад с 1896 по 2010: