MapReduce – Введение
MapReduce – это модель программирования для написания приложений, которые могут обрабатывать большие данные параллельно на нескольких узлах. MapReduce предоставляет аналитические возможности для анализа огромных объемов сложных данных.
Что такое большие данные?
Большие данные – это набор больших наборов данных, которые не могут быть обработаны с использованием традиционных вычислительных технологий. Например, объем данных, которые Facebook или Youtube должны требовать для ежедневного сбора и обработки, может подпадать под категорию больших данных. Однако большие данные касаются не только масштаба и объема, но и одного или нескольких из следующих аспектов – скорость, разнообразие, объем и сложность.
Почему MapReduce?
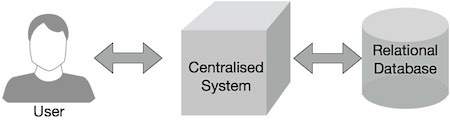
Традиционные корпоративные системы обычно имеют централизованный сервер для хранения и обработки данных. Следующая иллюстрация изображает схематическое представление традиционной системы предприятия. Традиционная модель, безусловно, не подходит для обработки огромных объемов масштабируемых данных и не может быть размещена на стандартных серверах баз данных. Более того, централизованная система создает слишком много узких мест при одновременной обработке нескольких файлов.
Google решил эту проблему, используя алгоритм MapReduce. MapReduce делит задачу на маленькие части и назначает их многим компьютерам. Позже результаты собираются в одном месте и объединяются для формирования результирующего набора данных.
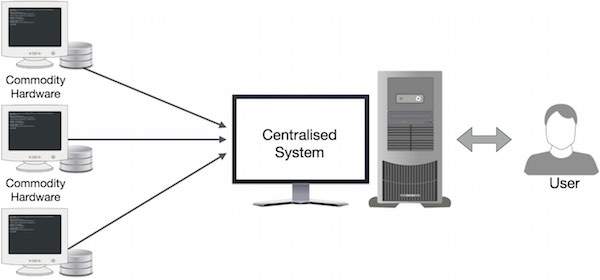
Как работает MapReduce?
Алгоритм MapReduce содержит две важные задачи, а именно Map и Reduce.
-
Задача «Карта» берет набор данных и преобразует его в другой набор данных, где отдельные элементы разбиваются на кортежи (пары ключ-значение).
-
Задача Reduce принимает выходные данные из карты в качестве входных данных и объединяет эти кортежи данных (пары ключ-значение) в меньший набор кортежей.
Задача «Карта» берет набор данных и преобразует его в другой набор данных, где отдельные элементы разбиваются на кортежи (пары ключ-значение).
Задача Reduce принимает выходные данные из карты в качестве входных данных и объединяет эти кортежи данных (пары ключ-значение) в меньший набор кортежей.
Задача уменьшения всегда выполняется после задания карты.
Давайте теперь внимательно рассмотрим каждый из этапов и попытаемся понять их значение.
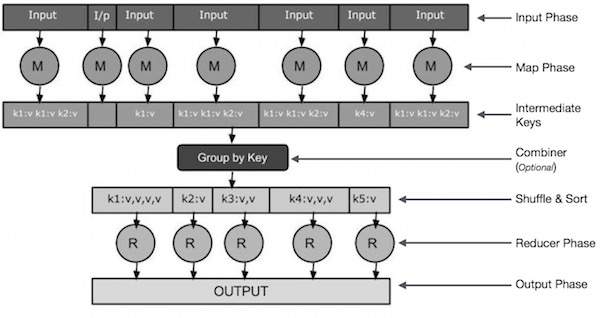
-
Фаза ввода – Здесь у нас есть Record Reader, который переводит каждую запись во входной файл и отправляет проанализированные данные в маппер в виде пар ключ-значение.
-
Карта – Карта – это пользовательская функция, которая принимает серию пар ключ-значение и обрабатывает каждую из них, чтобы сгенерировать ноль или более пар ключ-значение.
-
Промежуточные ключи – пары «ключ-значение», генерируемые картографом, называются промежуточными ключами.
-
Объединитель – объединитель – это тип локального редуктора, который группирует аналогичные данные из фазы карты в идентифицируемые наборы. Он принимает промежуточные ключи от преобразователя в качестве входных данных и применяет пользовательский код для агрегирования значений в небольшой области одного преобразователя. Он не является частью основного алгоритма MapReduce; это необязательно.
-
Перемешать и отсортировать – задача «Восстановитель» начинается с шага «Перемешать и сортировать». Он загружает сгруппированные пары ключ-значение на локальный компьютер, на котором работает редуктор. Отдельные пары ключ-значение сортируются по ключу в больший список данных. Список данных группирует эквивалентные ключи вместе, так что их значения могут быть легко повторены в задаче Reducer.
-
Редуктор – Редуктор принимает сгруппированные парные данные ключ-значение в качестве входных данных и запускает функцию Редуктор для каждого из них. Здесь данные могут быть агрегированы, отфильтрованы и объединены различными способами, что требует широкого спектра обработки. Как только выполнение закончено, он дает ноль или более пар ключ-значение для последнего шага.
-
Фаза вывода. На этапе вывода у нас есть выходной форматер, который переводит конечные пары ключ-значение из функции Reducer и записывает их в файл с помощью средства записи.
Фаза ввода – Здесь у нас есть Record Reader, который переводит каждую запись во входной файл и отправляет проанализированные данные в маппер в виде пар ключ-значение.
Карта – Карта – это пользовательская функция, которая принимает серию пар ключ-значение и обрабатывает каждую из них, чтобы сгенерировать ноль или более пар ключ-значение.
Промежуточные ключи – пары «ключ-значение», генерируемые картографом, называются промежуточными ключами.
Объединитель – объединитель – это тип локального редуктора, который группирует аналогичные данные из фазы карты в идентифицируемые наборы. Он принимает промежуточные ключи от преобразователя в качестве входных данных и применяет пользовательский код для агрегирования значений в небольшой области одного преобразователя. Он не является частью основного алгоритма MapReduce; это необязательно.
Перемешать и отсортировать – задача «Восстановитель» начинается с шага «Перемешать и сортировать». Он загружает сгруппированные пары ключ-значение на локальный компьютер, на котором работает редуктор. Отдельные пары ключ-значение сортируются по ключу в больший список данных. Список данных группирует эквивалентные ключи вместе, так что их значения могут быть легко повторены в задаче Reducer.
Редуктор – Редуктор принимает сгруппированные парные данные ключ-значение в качестве входных данных и запускает функцию Редуктор для каждого из них. Здесь данные могут быть агрегированы, отфильтрованы и объединены различными способами, что требует широкого спектра обработки. Как только выполнение закончено, он дает ноль или более пар ключ-значение для последнего шага.
Фаза вывода. На этапе вывода у нас есть выходной форматер, который переводит конечные пары ключ-значение из функции Reducer и записывает их в файл с помощью средства записи.
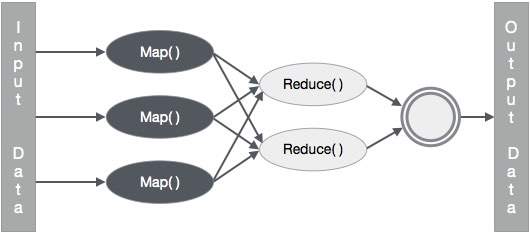
Давайте попробуем понять две задачи Map & f Reduce с помощью небольшой диаграммы –
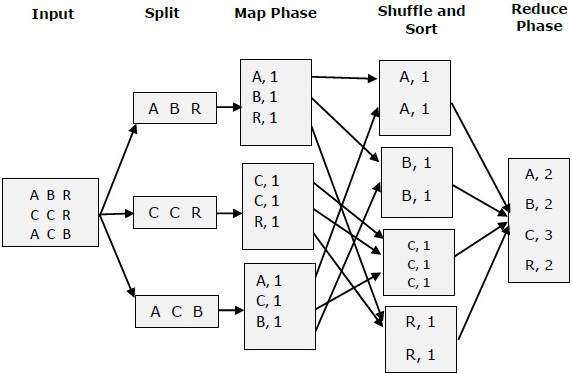
MapReduce-пример
Давайте возьмем пример из реальной жизни, чтобы понять мощь MapReduce. Twitter получает около 500 миллионов твитов в день, то есть почти 3000 твитов в секунду. На следующем рисунке показано, как Tweeter управляет своими твитами с помощью MapReduce.
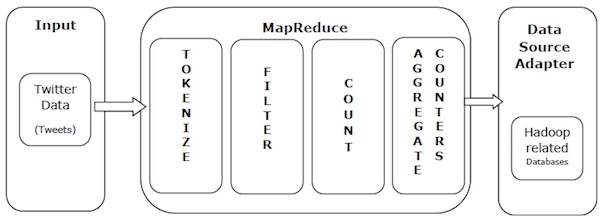
Как показано на рисунке, алгоритм MapReduce выполняет следующие действия:
-
Tokenize – токенизирует твиты в карты токенов и записывает их в виде пар ключ-значение.
-
Фильтр – Фильтрует нежелательные слова из карт токенов и записывает отфильтрованные карты в виде пар ключ-значение.
-
Count – генерирует счетчик токенов на слово.
-
Сводные счетчики – готовит совокупность аналогичных значений счетчиков в небольшие управляемые единицы.
Tokenize – токенизирует твиты в карты токенов и записывает их в виде пар ключ-значение.
Фильтр – Фильтрует нежелательные слова из карт токенов и записывает отфильтрованные карты в виде пар ключ-значение.
Count – генерирует счетчик токенов на слово.
Сводные счетчики – готовит совокупность аналогичных значений счетчиков в небольшие управляемые единицы.
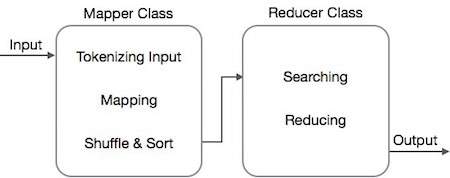
MapReduce – Алгоритм
Алгоритм MapReduce содержит две важные задачи, а именно Map и Reduce.
- Задача карты выполняется с помощью Mapper Class
- Задача уменьшения выполняется с помощью класса редуктора.
Класс Mapper принимает входные данные, маркирует их, отображает и сортирует их. Выходные данные класса Mapper используются в качестве входных данных классом Reducer, который, в свою очередь, ищет совпадающие пары и сокращает их.
MapReduce реализует различные математические алгоритмы, чтобы разделить задачу на маленькие части и назначить их нескольким системам. С технической точки зрения алгоритм MapReduce помогает отправлять задачи Map & Reduce на соответствующие серверы в кластере.
Эти математические алгоритмы могут включать в себя следующее:
- Сортировка
- поиск
- индексирование
- TF-IDF
Сортировка
Сортировка является одним из основных алгоритмов MapReduce для обработки и анализа данных. MapReduce реализует алгоритм сортировки для автоматической сортировки выходных пар ключ-значение из преобразователя по их ключам.
-
Методы сортировки реализованы в самом классе mapper.
-
На этапе перемешивания и сортировки после токенизации значений в классе сопоставления класс Context (определенный пользователем класс) собирает совпадающие значения ключей в виде коллекции.
-
Чтобы собрать похожие пары ключ-значение (промежуточные ключи), класс Mapper использует класс RawComparator для сортировки пар ключ-значение.
-
Набор промежуточных пар ключ-значение для данного редуктора автоматически сортируется Hadoop для формирования значений ключа (K2, {V2, V2,…}) до их представления редуктору.
Методы сортировки реализованы в самом классе mapper.
На этапе перемешивания и сортировки после токенизации значений в классе сопоставления класс Context (определенный пользователем класс) собирает совпадающие значения ключей в виде коллекции.
Чтобы собрать похожие пары ключ-значение (промежуточные ключи), класс Mapper использует класс RawComparator для сортировки пар ключ-значение.
Набор промежуточных пар ключ-значение для данного редуктора автоматически сортируется Hadoop для формирования значений ключа (K2, {V2, V2,…}) до их представления редуктору.
поиск
Поиск играет важную роль в алгоритме MapReduce. Это помогает в фазе объединителя (опция) и в фазе редуктора. Давайте попробуем понять, как поиск работает на примере.
пример
В следующем примере показано, как MapReduce использует алгоритм поиска, чтобы узнать подробности о сотруднике, который получает самую высокую зарплату в данном наборе данных сотрудников.
-
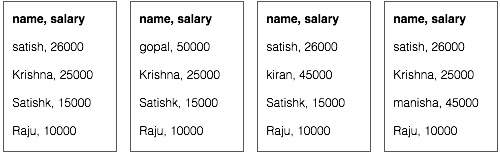
Предположим, у нас есть данные о сотрудниках в четырех разных файлах – A, B, C и D. Предположим также, что во всех четырех файлах есть дубликаты записей о сотрудниках из-за повторного импорта данных о сотрудниках из всех таблиц базы данных. Смотрите следующую иллюстрацию.
Предположим, у нас есть данные о сотрудниках в четырех разных файлах – A, B, C и D. Предположим также, что во всех четырех файлах есть дубликаты записей о сотрудниках из-за повторного импорта данных о сотрудниках из всех таблиц базы данных. Смотрите следующую иллюстрацию.
-
Фаза Map обрабатывает каждый входной файл и предоставляет данные о сотруднике в парах ключ-значение (<k, v>: <emp name, salary>). Смотрите следующую иллюстрацию.
Фаза Map обрабатывает каждый входной файл и предоставляет данные о сотруднике в парах ключ-значение (<k, v>: <emp name, salary>). Смотрите следующую иллюстрацию.

-
Фаза объединителя (метод поиска) будет принимать входные данные из фазы карты в виде пары ключ-значение с именем сотрудника и зарплатой. Используя технику поиска, комбинатор проверит всю зарплату сотрудника, чтобы найти сотрудника с наибольшим окладом в каждом файле. Смотрите следующий фрагмент.
Фаза объединителя (метод поиска) будет принимать входные данные из фазы карты в виде пары ключ-значение с именем сотрудника и зарплатой. Используя технику поиска, комбинатор проверит всю зарплату сотрудника, чтобы найти сотрудника с наибольшим окладом в каждом файле. Смотрите следующий фрагмент.
<k: employee name, v: salary> Max= the salary of an first employee. Treated as max salary if(v(second employee).salary > Max){ Max = v(salary); } else{ Continue checking; }
Ожидаемый результат заключается в следующем –
<сатиш, 26000>
<гопал, 50000>
<Киран, 45000>
<Маниша, 45000>
-
Этап сокращения – Сформируйте каждый файл, вы найдете самый высокооплачиваемый сотрудник. Чтобы избежать избыточности, проверьте все пары <k, v> и удалите дублирующиеся записи, если таковые имеются. Тот же алгоритм используется между четырьмя парами <k, v>, которые поступают из четырех входных файлов. Окончательный результат должен быть следующим:
Этап сокращения – Сформируйте каждый файл, вы найдете самый высокооплачиваемый сотрудник. Чтобы избежать избыточности, проверьте все пары <k, v> и удалите дублирующиеся записи, если таковые имеются. Тот же алгоритм используется между четырьмя парами <k, v>, которые поступают из четырех входных файлов. Окончательный результат должен быть следующим:
<gopal, 50000>
индексирование
Обычно индексация используется для указания на конкретные данные и их адрес. Он выполняет пакетную индексацию входных файлов для определенного Mapper.
Техника индексирования, которая обычно используется в MapReduce, называется инвертированным индексом. Поисковые системы, такие как Google и Bing, используют метод перевернутой индексации. Давайте попробуем понять, как работает индексирование, на простом примере.
пример
Следующий текст является вводом для инвертированной индексации. Здесь T [0], T [1] и t [2] – имена файлов, а их содержимое заключено в двойные кавычки.
T[0] = "it is what it is" T[1] = "what is it" T[2] = "it is a banana"
После применения алгоритма индексирования мы получаем следующий вывод:
"a": {2}
"banana": {2}
"is": {0, 1, 2}
"it": {0, 1, 2}
"what": {0, 1}
Здесь «a»: {2} подразумевает, что термин «a» появляется в файле T [2]. Аналогично, «is»: {0, 1, 2} подразумевает, что термин «is» появляется в файлах T [0], T [1] и T [2].
TF-IDF
TF-IDF – это алгоритм обработки текста, сокращенный от Term Frequency – Inverse Document Frequency. Это один из распространенных алгоритмов веб-анализа. Здесь термин «частота» относится к числу раз, когда термин появляется в документе.
Термин частота (TF)
Он измеряет, как часто конкретный термин встречается в документе. Он рассчитывается по количеству появлений слова в документе, деленному на общее количество слов в этом документе.
TF(the) = (Number of times term the ‘the’ appears in a document) / (Total number of terms in the document)
Частота обратных документов (IDF)
Он измеряет важность термина. Он рассчитывается по количеству документов в текстовой базе данных, деленному на количество документов, в которых появляется конкретный термин.
При вычислении TF все термины считаются одинаково важными. Это означает, что TF подсчитывает частоту термина для обычных слов, таких как «есть», «а», «что» и т. Д. Таким образом, нам нужно знать частые термины при увеличении количества редких, вычисляя следующее:
IDF(the) = log_e(Total number of documents / Number of documents with term ‘the’ in it).
Алгоритм объяснен ниже с помощью небольшого примера.
пример
Рассмотрим документ, содержащий 1000 слов, в котором слово улей появляется 50 раз. Тогда TF для улья (50/1000) = 0,05.
Теперь предположим, что у нас есть 10 миллионов документов и слово « куст» появляется в 1000 из них. Затем IDF рассчитывается как log (10 000 000/1000) = 4.
Вес TF-IDF является произведением этих количеств – 0,05 × 4 = 0,20.
MapReduce – Установка
MapReduce работает только в операционных системах со вкусом Linux и поставляется с Hadoop Framework. Нам нужно выполнить следующие шаги для установки фреймворка Hadoop.
Проверка установки JAVA
Java должна быть установлена в вашей системе перед установкой Hadoop. Используйте следующую команду, чтобы проверить, установлена ли у вас Java в вашей системе.
$ java –version
Если Java уже установлена в вашей системе, вы увидите следующий ответ:
java version "1.7.0_71" Java(TM) SE Runtime Environment (build 1.7.0_71-b13) Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)
Если в вашей системе не установлена Java, выполните следующие действия.
Установка Java
Шаг 1
Скачать последнюю версию Java можно по следующей ссылке – этой ссылке .
После загрузки вы можете найти файл jdk-7u71-linux-x64.tar.gz в папке «Загрузки».
Шаг 2
Используйте следующие команды для извлечения содержимого jdk-7u71-linux-x64.gz.
$ cd Downloads/ $ ls jdk-7u71-linux-x64.gz $ tar zxf jdk-7u71-linux-x64.gz $ ls jdk1.7.0_71 jdk-7u71-linux-x64.gz
Шаг 3
Чтобы сделать Java доступным для всех пользователей, вы должны переместить его в папку «/ usr / local /». Зайдите в root и введите следующие команды –
$ su password: # mv jdk1.7.0_71 /usr/local/java # exit
Шаг 4
Для настройки переменных PATH и JAVA_HOME добавьте следующие команды в файл ~ / .bashrc.
export JAVA_HOME=/usr/local/java export PATH=$PATH:$JAVA_HOME/bin
Примените все изменения к текущей работающей системе.
$ source ~/.bashrc
Шаг 5
Используйте следующие команды для настройки альтернатив Java –
# alternatives --install /usr/bin/java java usr/local/java/bin/java 2 # alternatives --install /usr/bin/javac javac usr/local/java/bin/javac 2 # alternatives --install /usr/bin/jar jar usr/local/java/bin/jar 2 # alternatives --set java usr/local/java/bin/java # alternatives --set javac usr/local/java/bin/javac # alternatives --set jar usr/local/java/bin/jar
Теперь проверьте установку с помощью команды java -version из терминала.
Проверка правильности установки Hadoop
Hadoop должен быть установлен в вашей системе перед установкой MapReduce. Давайте проверим установку Hadoop с помощью следующей команды –
$ hadoop version
Если Hadoop уже установлен в вашей системе, вы получите следующий ответ:
Hadoop 2.4.1 -- Subversion https://svn.apache.org/repos/asf/hadoop/common -r 1529768 Compiled by hortonmu on 2013-10-07T06:28Z Compiled with protoc 2.5.0 From source with checksum 79e53ce7994d1628b240f09af91e1af4
Если Hadoop не установлен в вашей системе, выполните следующие действия.
Загрузка Hadoop
Загрузите Hadoop 2.4.1 с Apache Software Foundation и извлеките его содержимое с помощью следующих команд.
$ su password: # cd /usr/local # wget http://apache.claz.org/hadoop/common/hadoop-2.4.1/ hadoop-2.4.1.tar.gz # tar xzf hadoop-2.4.1.tar.gz # mv hadoop-2.4.1/* to hadoop/ # exit
Установка Hadoop в псевдо-распределенном режиме
Следующие шаги используются для установки Hadoop 2.4.1 в псевдораспределенном режиме.
Шаг 1 – Настройка Hadoop
Вы можете установить переменные среды Hadoop, добавив следующие команды в файл ~ / .bashrc.
export HADOOP_HOME=/usr/local/hadoop export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
Примените все изменения к текущей работающей системе.
$ source ~/.bashrc
Шаг 2 – Настройка Hadoop
Вы можете найти все файлы конфигурации Hadoop в папке «$ HADOOP_HOME / etc / hadoop». Вам необходимо внести соответствующие изменения в эти файлы конфигурации в соответствии с вашей инфраструктурой Hadoop.
$ cd $HADOOP_HOME/etc/hadoop
Для разработки программ Hadoop с использованием Java вам необходимо сбросить переменные среды Java в файле hadoop-env.sh , заменив значение JAVA_HOME местоположением Java в вашей системе.
export JAVA_HOME=/usr/local/java
Вы должны отредактировать следующие файлы для настройки Hadoop –
- ядро-site.xml
- HDFS-site.xml
- Пряжа-site.xml
- mapred-site.xml
ядро-site.xml
core-site.xml содержит следующую информацию:
- Номер порта, используемый для экземпляра Hadoop
- Память, выделенная для файловой системы
- Ограничение памяти для хранения данных
- Размер буферов чтения / записи
Откройте файл core-site.xml и добавьте следующие свойства между тегами <configuration> и </ configuration>.
<configuration> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000 </value> </property> </configuration>
HDFS-site.xml
hdfs-site.xml содержит следующую информацию –
- Значение данных репликации
- Наменодская дорожка
- Путь к датоде ваших локальных файловых систем (место, где вы хотите хранить инфраструктуру Hadoop)
Допустим, следующие данные.
dfs.replication (data replication value) = 1 (In the following path /hadoop/ is the user name. hadoopinfra/hdfs/namenode is the directory created by hdfs file system.) namenode path = //home/hadoop/hadoopinfra/hdfs/namenode (hadoopinfra/hdfs/datanode is the directory created by hdfs file system.) datanode path = //home/hadoop/hadoopinfra/hdfs/datanode
Откройте этот файл и добавьте следующие свойства между тегами <configuration>, </ configuration>.
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.name.dir</name> <value>file:///home/hadoop/hadoopinfra/hdfs/namenode</value> </property> <property> <name>dfs.data.dir</name> <value>file:///home/hadoop/hadoopinfra/hdfs/datanode </value> </property> </configuration>
Примечание. В приведенном выше файле все значения свойств определяются пользователем, и вы можете вносить изменения в соответствии с инфраструктурой Hadoop.
Пряжа-site.xml
Этот файл используется для настройки пряжи в Hadoop. Откройте файл yarn-site.xml и добавьте следующие свойства между тегами <configuration>, </ configuration>.
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
mapred-site.xml
Этот файл используется для указания используемой нами структуры MapReduce. По умолчанию Hadoop содержит шаблон yarn-site.xml. Прежде всего вам необходимо скопировать файл из mapred-site.xml.template в файл mapred-site.xml с помощью следующей команды.
$ cp mapred-site.xml.template mapred-site.xml
Откройте файл mapred-site.xml и добавьте следующие свойства между тегами <configuration>, </ configuration>.
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
Проверка правильности установки Hadoop
Следующие шаги используются для проверки установки Hadoop.
Шаг 1 – Настройка узла имени
Настройте namenode с помощью команды «hdfs namenode -format» следующим образом:
$ cd ~ $ hdfs namenode -format
Ожидаемый результат заключается в следующем –
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = localhost/192.168.1.11 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.4.1 ... ... 10/24/14 21:30:56 INFO common.Storage: Storage directory /home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted. 10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0 10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11 ************************************************************/
Шаг 2 – Проверка Hadoop dfs
Выполните следующую команду, чтобы запустить файловую систему Hadoop.
$ start-dfs.sh
Ожидаемый результат следующий:
10/24/14 21:37:56 Starting namenodes on [localhost] localhost: starting namenode, logging to /home/hadoop/hadoop- 2.4.1/logs/hadoop-hadoop-namenode-localhost.out localhost: starting datanode, logging to /home/hadoop/hadoop- 2.4.1/logs/hadoop-hadoop-datanode-localhost.out Starting secondary namenodes [0.0.0.0]
Шаг 3 – Проверка скрипта пряжи
Следующая команда используется для запуска скрипта пряжи. Выполнение этой команды запустит ваши демоны пряжи.
$ start-yarn.sh
Ожидаемый результат следующий:
starting yarn daemons starting resourcemanager, logging to /home/hadoop/hadoop- 2.4.1/logs/yarn-hadoop-resourcemanager-localhost.out localhost: starting node manager, logging to /home/hadoop/hadoop- 2.4.1/logs/yarn-hadoop-nodemanager-localhost.out
Шаг 4 – Доступ к Hadoop в браузере
Номер порта по умолчанию для доступа к Hadoop – 50070. Используйте следующий URL-адрес, чтобы получить службы Hadoop в своем браузере.
http://localhost:50070/
На следующем снимке экрана показан браузер Hadoop.
Шаг 5 – Проверьте все приложения кластера
Номер порта по умолчанию для доступа ко всем приложениям кластера – 8088. Используйте следующий URL для использования этой службы.
http://localhost:8088/
На следующем снимке экрана показан кластерный браузер Hadoop.
MapReduce – API
В этой главе мы подробно рассмотрим классы и их методы, которые участвуют в операциях программирования MapReduce. В первую очередь мы сосредоточимся на следующем:
- Интерфейс JobContext
- Класс работы
- Mapper Class
- Класс редуктора
Интерфейс JobContext
Интерфейс JobContext – это суперинтерфейс для всех классов, который определяет различные задания в MapReduce. Это дает вам доступ только для чтения к заданию, которое предоставляется задачам во время их выполнения.
Ниже приведены подинтерфейсы интерфейса JobContext.
| S.No. | Подинтерфейс Описание |
|---|---|
| 1. | MapContext <KEYIN, VALUEIN, KEYOUT, VALUEOUT>
Определяет контекст, который предоставляется Mapper. |
| 2. | ReduceContext <KEYIN, VALUEIN, KEYOUT, VALUEOUT>
Определяет контекст, который передается редуктору. |
Определяет контекст, который предоставляется Mapper.
Определяет контекст, который передается редуктору.
Класс Job – это основной класс, который реализует интерфейс JobContext.
Класс работы
Класс Job является наиболее важным классом в API MapReduce. Это позволяет пользователю настраивать задание, отправлять его, контролировать его выполнение и запрашивать состояние. Методы set работают только до отправки задания, после чего они генерируют исключение IllegalStateException.
Обычно пользователь создает приложение, описывает различные аспекты задания, а затем отправляет задание и отслеживает его выполнение.
Вот пример того, как подать заявку –
// Create a new Job
Job job = new Job(new Configuration());
job.setJarByClass(MyJob.class);
// Specify various job-specific parameters
job.setJobName("myjob");
job.setInputPath(new Path("in"));
job.setOutputPath(new Path("out"));
job.setMapperClass(MyJob.MyMapper.class);
job.setReducerClass(MyJob.MyReducer.class);
// Submit the job, then poll for progress until the job is complete
job.waitForCompletion(true);
Конструкторы
Ниже приводится краткое описание конструктора класса Job.
| S.No | Сводка конструктора |
|---|---|
| 1 | Работа () |
| 2 | Job (Конфиг конфигурации) |
| 3 | Job (Конфигурация conf, String jobName) |
методы
Вот некоторые из важных методов класса Job:
| S.No | Описание метода |
|---|---|
| 1 | getJobName ()
Заданное пользователем имя задания. |
| 2 | getJobState ()
Возвращает текущее состояние задания. |
| 3 | завершено()
Проверяет, закончена ли работа или нет. |
| 4 | setInputFormatClass ()
Устанавливает InputFormat для работы. |
| 5 | setJobName (имя строки)
Устанавливает заданное пользователем имя задания. |
| 6 | setOutputFormatClass ()
Устанавливает формат вывода для работы. |
| 7 | setMapperClass (класс)
Устанавливает Mapper для работы. |
| 8 | setReducerClass (класс)
Устанавливает Редуктор для работы. |
| 9 | setPartitionerClass (класс)
Устанавливает Partitioner для работы. |
| 10 | setCombinerClass (класс)
Устанавливает Combiner для работы. |
Заданное пользователем имя задания.
Возвращает текущее состояние задания.
Проверяет, закончена ли работа или нет.
Устанавливает InputFormat для работы.
Устанавливает заданное пользователем имя задания.
Устанавливает формат вывода для работы.
Устанавливает Mapper для работы.
Устанавливает Редуктор для работы.
Устанавливает Partitioner для работы.
Устанавливает Combiner для работы.
Mapper Class
Класс Mapper определяет задание Map. Сопоставляет входные пары ключ-значение с набором промежуточных пар ключ-значение. Карты – это отдельные задачи, которые преобразуют входные записи в промежуточные записи. Преобразованные промежуточные записи не обязательно должны быть того же типа, что и входные записи. Заданная входная пара может отображаться на ноль или на множество выходных пар.
метод
карта является наиболее известным методом класса Mapper. Синтаксис определен ниже –
map(KEYIN key, VALUEIN value, org.apache.hadoop.mapreduce.Mapper.Context context)
Этот метод вызывается один раз для каждой пары ключ-значение во входном разбиении.
Класс редуктора
Класс Reducer определяет задание Reduce в MapReduce. Это уменьшает набор промежуточных значений, которые разделяют ключ, до меньшего набора значений. Реализации редуктора могут получить доступ к Конфигурации для задания через метод JobContext.getConfiguration (). Редуктор имеет три основных этапа – перемешивание, сортировка и уменьшение.
-
Перемешать – Редуктор копирует отсортированный вывод из каждого Mapper, используя HTTP по всей сети.
-
Сортировать – платформа объединяет сортировку входов Редуктора по ключам (поскольку разные Mappers могут выводить один и тот же ключ). Фазы тасования и сортировки происходят одновременно, т. Е. Во время выборки выходов они объединяются.
-
Сокращение – На этом этапе метод Redu (Object, Iterable, Context) вызывается для каждого <ключа, (набора значений)> в отсортированных входных данных.
Перемешать – Редуктор копирует отсортированный вывод из каждого Mapper, используя HTTP по всей сети.
Сортировать – платформа объединяет сортировку входов Редуктора по ключам (поскольку разные Mappers могут выводить один и тот же ключ). Фазы тасования и сортировки происходят одновременно, т. Е. Во время выборки выходов они объединяются.
Сокращение – На этом этапе метод Redu (Object, Iterable, Context) вызывается для каждого <ключа, (набора значений)> в отсортированных входных данных.
метод
Редукция – самый известный метод класса Редукторов. Синтаксис определен ниже –
reduce (KEYIN key, Iterable<VALUEIN> values, org.apache.hadoop.mapreduce.Reducer.Context context)
Этот метод вызывается один раз для каждого ключа в коллекции пар ключ-значение.
MapReduce – реализация Hadoop
MapReduce – это инфраструктура, которая используется для написания приложений для надежной обработки огромных объемов данных на больших кластерах аппаратного оборудования. В этой главе рассказывается о работе MapReduce в среде Hadoop с использованием Java.
Алгоритм MapReduce
Обычно парадигма MapReduce основана на отправке программ сокращения карт на компьютеры, где хранятся фактические данные.
-
Во время задания MapReduce Hadoop отправляет задачи Map и Reduce на соответствующие серверы в кластере.
-
Каркас управляет всеми деталями передачи данных, такими как выдача задач, проверка выполнения задач и копирование данных вокруг кластера между узлами.
-
Большая часть вычислений происходит на узлах с данными на локальных дисках, что снижает сетевой трафик.
-
После выполнения заданной задачи кластер собирает и сокращает данные, чтобы сформировать соответствующий результат, и отправляет их обратно на сервер Hadoop.
Во время задания MapReduce Hadoop отправляет задачи Map и Reduce на соответствующие серверы в кластере.
Каркас управляет всеми деталями передачи данных, такими как выдача задач, проверка выполнения задач и копирование данных вокруг кластера между узлами.
Большая часть вычислений происходит на узлах с данными на локальных дисках, что снижает сетевой трафик.
После выполнения заданной задачи кластер собирает и сокращает данные, чтобы сформировать соответствующий результат, и отправляет их обратно на сервер Hadoop.
Входы и выходы (перспектива Java)
Каркас MapReduce работает с парами ключ-значение, то есть каркас рассматривает входные данные для задания в виде набора пар ключ-значение и создает набор пар ключ-значение в качестве выходных данных задания, предположительно различных типов.
Классы ключа и значения должны быть сериализуемы платформой, и, следовательно, необходимо реализовать интерфейс Writable. Кроме того, ключевые классы должны реализовывать интерфейс WritableComparable для облегчения сортировки в рамках.
Оба формата ввода и вывода задания MapReduce представлены в виде пар ключ-значение –
(Вход) <k1, v1> -> карта -> <k2, v2> -> уменьшить -> <k3, v3> (вывод).
| вход | Выход | |
|---|---|---|
| карта | <k1, v1> | список (<k2, v2>) |
| уменьшить | <k2, список (v2)> | список (<k3, v3>) |
Реализация MapReduce
В следующей таблице приведены данные, касающиеся потребления электроэнергии в организации. Таблица включает ежемесячное потребление электроэнергии и среднегодовое значение за пять лет подряд.
| январь | февраль | март | апрель | май | июнь | июль | август | сентябрь | октябрь | ноябрь | декабрь | в среднем | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1979 | 23 | 23 | 2 | 43 | 24 | 25 | 26 | 26 | 26 | 26 | 25 | 26 | 25 |
| 1980 | 26 | 27 | 28 | 28 | 28 | 30 | 31 | 31 | 31 | 30 | 30 | 30 | 29 |
| 1981 | 31 | 32 | 32 | 32 | 33 | 34 | 35 | 36 | 36 | 34 | 34 | 34 | 34 |
| 1984 | 39 | 38 | 39 | 39 | 39 | 41 | 42 | 43 | 40 | 39 | 38 | 38 | 40 |
| 1985 | 38 | 39 | 39 | 39 | 39 | 41 | 41 | 41 | 00 | 40 | 39 | 39 | 45 |
Нам нужно написать приложения для обработки входных данных в данной таблице, чтобы найти год максимального использования, год минимального использования и так далее. Эта задача проста для программистов с конечным количеством записей, поскольку они просто напишут логику для получения требуемого вывода и передадут данные в написанное приложение.
Давайте теперь поднимем масштаб входных данных. Предположим, мы должны проанализировать потребление электроэнергии всеми крупными отраслями конкретного государства. Когда мы пишем приложения для обработки таких массовых данных,
-
Они займут много времени, чтобы выполнить.
-
При переносе данных из источника на сетевой сервер будет большой сетевой трафик.
Они займут много времени, чтобы выполнить.
При переносе данных из источника на сетевой сервер будет большой сетевой трафик.
Для решения этих проблем у нас есть инфраструктура MapReduce.
Входные данные
Приведенные выше данные сохраняются как sample.txt и передаются в качестве входных данных. Входной файл выглядит так, как показано ниже.
| 1979 | 23 | 23 | 2 | 43 | 24 | 25 | 26 | 26 | 26 | 26 | 25 | 26 | 25 |
| 1980 | 26 | 27 | 28 | 28 | 28 | 30 | 31 | 31 | 31 | 30 | 30 | 30 | 29 |
| 1981 | 31 | 32 | 32 | 32 | 33 | 34 | 35 | 36 | 36 | 34 | 34 | 34 | 34 |
| 1984 | 39 | 38 | 39 | 39 | 39 | 41 | 42 | 43 | 40 | 39 | 38 | 38 | 40 |
| 1985 | 38 | 39 | 39 | 39 | 39 | 41 | 41 | 41 | 00 | 40 | 39 | 39 | 45 |
Пример программы
Следующая программа для примера данных использует каркас MapReduce.
package hadoop; import java.util.*; import java.io.IOException; import java.io.IOException; import org.apache.hadoop.fs.Path; import org.apache.hadoop.conf.*; import org.apache.hadoop.io.*; import org.apache.hadoop.mapred.*; import org.apache.hadoop.util.*; public class ProcessUnits { //Mapper class public static class E_EMapper extends MapReduceBase implements Mapper<LongWritable, /*Input key Type */ Text, /*Input value Type*/ Text, /*Output key Type*/ IntWritable> /*Output value Type*/ { //Map function public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { String line = value.toString(); String lasttoken = null; StringTokenizer s = new StringTokenizer(line,"t"); String year = s.nextToken(); while(s.hasMoreTokens()){ lasttoken=s.nextToken(); } int avgprice = Integer.parseInt(lasttoken); output.collect(new Text(year), new IntWritable(avgprice)); } } //Reducer class public static class E_EReduce extends MapReduceBase implements Reducer< Text, IntWritable, Text, IntWritable > { //Reduce function public void reduce(Text key, Iterator <IntWritable> values, OutputCollector>Text, IntWritable> output, Reporter reporter) throws IOException { int maxavg=30; int val=Integer.MIN_VALUE; while (values.hasNext()) { if((val=values.next().get())>maxavg) { output.collect(key, new IntWritable(val)); } } } } //Main function public static void main(String args[])throws Exception { JobConf conf = new JobConf(Eleunits.class); conf.setJobName("max_eletricityunits"); conf.setOutputKeyClass(Text.class); conf.setOutputValueClass(IntWritable.class); conf.setMapperClass(E_EMapper.class); conf.setCombinerClass(E_EReduce.class); conf.setReducerClass(E_EReduce.class); conf.setInputFormat(TextInputFormat.class); conf.setOutputFormat(TextOutputFormat.class); FileInputFormat.setInputPaths(conf, new Path(args[0])); FileOutputFormat.setOutputPath(conf, new Path(args[1])); JobClient.runJob(conf); } }
Сохраните вышеуказанную программу в ProcessUnits.java . Компиляция и выполнение программы приведены ниже.
Компиляция и выполнение программы ProcessUnits
Предположим, мы находимся в домашнем каталоге пользователя Hadoop (например, / home / hadoop).
Следуйте инструкциям ниже, чтобы скомпилировать и выполнить вышеуказанную программу.
Шаг 1 – Используйте следующую команду, чтобы создать каталог для хранения скомпилированных классов Java.
$ mkdir units
Шаг 2 – Загрузите Hadoop-core-1.2.1.jar, который используется для компиляции и выполнения программы MapReduce. Загрузите банку с mvnrepository.com . Предположим, что папка для загрузки – / home / hadoop /.
Шаг 3 – Следующие команды используются для компиляции программы ProcessUnits.java и для создания jar для программы.
$ javac -classpath hadoop-core-1.2.1.jar -d units ProcessUnits.java $ jar -cvf units.jar -C units/ .
Шаг 4 – Следующая команда используется для создания входного каталога в HDFS.
$HADOOP_HOME/bin/hadoop fs -mkdir input_dir
Шаг 5 – Следующая команда используется для копирования входного файла с именем sample.txt во входной каталог HDFS.
$HADOOP_HOME/bin/hadoop fs -put /home/hadoop/sample.txt input_dir
Шаг 6 – Следующая команда используется для проверки файлов во входном каталоге
$HADOOP_HOME/bin/hadoop fs -ls input_dir/
Шаг 7 – Следующая команда используется для запуска приложения Eleunit_max путем извлечения входных файлов из входного каталога.
$HADOOP_HOME/bin/hadoop jar units.jar hadoop.ProcessUnits input_dir output_dir
Подождите некоторое время, пока файл не запустится. После выполнения выходные данные содержат несколько входных разбиений, задачи Map, задачи Reducer и т. Д.
INFO mapreduce.Job: Job job_1414748220717_0002 completed successfully 14/10/31 06:02:52 INFO mapreduce.Job: Counters: 49 File System Counters FILE: Number of bytes read=61 FILE: Number of bytes written=279400 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=546 HDFS: Number of bytes written=40 HDFS: Number of read operations=9 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Launched map tasks=2 Launched reduce tasks=1 Data-local map tasks=2 Total time spent by all maps in occupied slots (ms)=146137 Total time spent by all reduces in occupied slots (ms)=441 Total time spent by all map tasks (ms)=14613 Total time spent by all reduce tasks (ms)=44120 Total vcore-seconds taken by all map tasks=146137 Total vcore-seconds taken by all reduce tasks=44120 Total megabyte-seconds taken by all map tasks=149644288 Total megabyte-seconds taken by all reduce tasks=45178880 Map-Reduce Framework Map input records=5 Map output records=5 Map output bytes=45 Map output materialized bytes=67 Input split bytes=208 Combine input records=5 Combine output records=5 Reduce input groups=5 Reduce shuffle bytes=6 Reduce input records=5 Reduce output records=5 Spilled Records=10 Shuffled Maps =2 Failed Shuffles=0 Merged Map outputs=2 GC time elapsed (ms)=948 CPU time spent (ms)=5160 Physical memory (bytes) snapshot=47749120 Virtual memory (bytes) snapshot=2899349504 Total committed heap usage (bytes)=277684224 File Output Format Counters Bytes Written=40
Шаг 8 – Следующая команда используется для проверки результирующих файлов в выходной папке.
$HADOOP_HOME/bin/hadoop fs -ls output_dir/
Шаг 9 – Следующая команда используется для просмотра выходных данных в файле Part-00000 . Этот файл создан HDFS.
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000
Ниже приводится вывод, сгенерированный программой MapReduce –
Шаг 10 – Следующая команда используется для копирования выходной папки из HDFS в локальную файловую систему.
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000/bin/hadoop dfs -get output_dir /home/hadoop
MapReduce – Partitioner
Секционер работает как условие при обработке входного набора данных. Фаза разбиения происходит после фазы Map и до фазы Reduce.
Количество секционеров равно количеству редукторов. Это означает, что разделитель разделит данные в соответствии с числом редукторов. Следовательно, данные, передаваемые с одного разделителя, обрабатываются одним редуктором.
Разметка
Разделитель разделяет пары ключ-значение промежуточных выходов Map. Он разделяет данные, используя пользовательское условие, которое работает как хэш-функция. Общее количество разделов совпадает с количеством заданий Reducer для задания. Давайте рассмотрим пример, чтобы понять, как работает разделитель.
Внедрение MapReduce Partitioner
Для удобства предположим, что у нас есть небольшая таблица Employee со следующими данными. Мы будем использовать этот пример данных в качестве нашего входного набора данных, чтобы продемонстрировать, как работает разделитель.
| Я бы | название | Возраст | Пол | Оплата труда |
|---|---|---|---|---|
| 1201 | Гопал | 45 | мужчина | 50000 |
| 1202 | Маниша | 40 | женский | 50000 |
| 1203 | Халил | 34 | мужчина | 30000 |
| 1204 | Prasanth | 30 | мужчина | 30000 |
| 1205 | Киран | 20 | мужчина | 40000 |
| 1206 | Лакшми | 25 | женский | 35000 |
| 1207 | Бхавайя | 20 | женский | 15000 |
| 1208 | Reshma | 19 | женский | 15000 |
| 1209 | kranthi | 22 | мужчина | 22000 |
| +1210 | Сатиш | 24 | мужчина | 25000 |
| 1211 | Кришна | 25 | мужчина | 25000 |
| 1212 | Аршад | 28 | мужчина | 20000 |
| 1213 | Лаванья | 18 | женский | 8000 |
Мы должны написать заявление для обработки входного набора данных, чтобы найти работника с наибольшим окладом по полу в разных возрастных группах (например, ниже 20 лет, от 21 до 30 лет, выше 30 лет).
Входные данные
Приведенные выше данные сохраняются в файле input.txt в каталоге «/ home / hadoop / hadoopPartitioner» и передаются в качестве входных данных.
| 1201 | Гопал | 45 | мужчина | 50000 |
| 1202 | Маниша | 40 | женский | 51000 |
| 1203 | Khaleel | 34 | мужчина | 30000 |
| 1204 | Prasanth | 30 | мужчина | 31000 |
| 1205 | Киран | 20 | мужчина | 40000 |
| 1206 | Лакшми | 25 | женский | 35000 |
| 1207 | Бхавайя | 20 | женский | 15000 |
| 1208 | Reshma | 19 | женский | 14 000 |
| 1209 | kranthi | 22 | мужчина | 22000 |
| +1210 | Сатиш | 24 | мужчина | 25000 |
| 1211 | Кришна | 25 | мужчина | 26000 |
| 1212 | Аршад | 28 | мужчина | 20000 |
| 1213 | Лаванья | 18 | женский | 8000 |
Основываясь на данном входе, ниже приводится алгоритмическое объяснение программы.
Задачи карты
Задача карты принимает пары ключ-значение в качестве входных данных, пока у нас есть текстовые данные в текстовом файле. Входные данные для этой задачи карты следующие:
Ввод – ключом будет шаблон, такой как «любая специальная клавиша + имя файла + номер строки» (пример: ключ = @ input1), а значением будут данные в этой строке (пример: значение = 1201 t gopal t 45 т мужской т 50000).
Метод – Работа этой задачи карты заключается в следующем –
-
Прочитайте значение (запись данных), которое поступает в качестве входного значения из списка аргументов в строке.
-
Используя функцию split, разделите пол и сохраните в строковую переменную.
Прочитайте значение (запись данных), которое поступает в качестве входного значения из списка аргументов в строке.
Используя функцию split, разделите пол и сохраните в строковую переменную.
String[] str = value.toString().split("t", -3);
String gender=str[3];
-
Отправьте информацию о поле и значение записи в виде пары выходной ключ-значение из задачи сопоставления в задачу разбиения .
Отправьте информацию о поле и значение записи в виде пары выходной ключ-значение из задачи сопоставления в задачу разбиения .
context.write(new Text(gender), new Text(value));
-
Повторите все вышеперечисленные шаги для всех записей в текстовом файле.
Повторите все вышеперечисленные шаги для всех записей в текстовом файле.
Вывод. Вы получите половые данные и данные записи в виде пар ключ-значение.
Задача Partitioner
Задача секционера принимает пары ключ-значение из задачи карты в качестве входных данных. Разделение подразумевает разделение данных на сегменты. В соответствии с заданными условными критериями разделов входные парные данные ключ-значение могут быть разделены на три части на основе возрастных критериев.
Ввод – все данные в коллекции пар ключ-значение.
ключ = значение поля пола в записи.
значение = значение всей записи данных этого пола.
Метод . Процесс логики разбиения выполняется следующим образом.
- Считайте значение поля возраста из пары ключ-значение.
String[] str = value.toString().split("t");
int age = Integer.parseInt(str[2]);
-
Проверьте значение возраста с соблюдением следующих условий.
- Возраст не более 20
- Возраст больше 20 и меньше или равно 30.
- Возраст старше 30.
Проверьте значение возраста с соблюдением следующих условий.
if(age<=20) { return 0; } else if(age>20 && age<=30) { return 1 % numReduceTasks; } else { return 2 % numReduceTasks; }
Вывод . Все данные пар ключ-значение сегментированы на три набора пар ключ-значение. Редуктор работает индивидуально на каждую коллекцию.
Уменьшить задачи
Количество задач секционирования равно количеству задач редуктора. Здесь у нас есть три задачи секционирования, и, следовательно, у нас есть три задачи редуктора, которые нужно выполнить.
Ввод – Редуктор будет выполняться три раза с различным набором пар ключ-значение.
ключ = значение поля пола в записи.
значение = все данные записи этого пола.
Метод – следующая логика будет применяться к каждой коллекции.
- Прочитайте значение поля Зарплата каждой записи.
String [] str = val.toString().split("t", -3);
Note: str[4] have the salary field value.
-
Проверьте зарплату с помощью переменной max. Если str [4] является максимальной зарплатой, присвойте str [4] значение max, в противном случае пропустите шаг.
Проверьте зарплату с помощью переменной max. Если str [4] является максимальной зарплатой, присвойте str [4] значение max, в противном случае пропустите шаг.
if(Integer.parseInt(str[4])>max) { max=Integer.parseInt(str[4]); }
-
Повторите шаги 1 и 2 для каждой коллекции ключей (мужские и женские – ключевые коллекции). Выполнив эти три шага, вы найдете одну максимальную зарплату из коллекции ключей для мужчин и одну максимальную зарплату из коллекции ключей для женщин.
Повторите шаги 1 и 2 для каждой коллекции ключей (мужские и женские – ключевые коллекции). Выполнив эти три шага, вы найдете одну максимальную зарплату из коллекции ключей для мужчин и одну максимальную зарплату из коллекции ключей для женщин.
context.write(new Text(key), new IntWritable(max));
Вывод. Наконец, вы получите набор данных пары ключ-значение в трех коллекциях разных возрастных групп. Он содержит максимальную зарплату из коллекции мужчин и максимальную зарплату из коллекции женщин в каждой возрастной группе соответственно.
После выполнения задач Map, Partitioner и Reduce три набора данных пары ключ-значение сохраняются в трех разных файлах в качестве выходных данных.
Все три задачи рассматриваются как задания MapReduce. Следующие требования и спецификации этих заданий должны быть указаны в Конфигурациях –
- Название работы
- Форматы ввода и вывода ключей и значений
- Отдельные классы для задач Map, Reduce и Partitioner
Configuration conf = getConf(); //Create Job Job job = new Job(conf, "topsal"); job.setJarByClass(PartitionerExample.class); // File Input and Output paths FileInputFormat.setInputPaths(job, new Path(arg[0])); FileOutputFormat.setOutputPath(job,new Path(arg[1])); //Set Mapper class and Output format for key-value pair. job.setMapperClass(MapClass.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); //set partitioner statement job.setPartitionerClass(CaderPartitioner.class); //Set Reducer class and Input/Output format for key-value pair. job.setReducerClass(ReduceClass.class); //Number of Reducer tasks. job.setNumReduceTasks(3); //Input and Output format for data job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class);
Пример программы
Следующая программа показывает, как реализовать разделители для заданных критериев в программе MapReduce.
package partitionerexample; import java.io.*; import org.apache.hadoop.io.*; import org.apache.hadoop.mapreduce.*; import org.apache.hadoop.conf.*; import org.apache.hadoop.conf.*; import org.apache.hadoop.fs.*; import org.apache.hadoop.mapreduce.lib.input.*; import org.apache.hadoop.mapreduce.lib.output.*; import org.apache.hadoop.util.*; public class PartitionerExample extends Configured implements Tool { //Map class public static class MapClass extends Mapper<LongWritable,Text,Text,Text> { public void map(LongWritable key, Text value, Context context) { try{ String[] str = value.toString().split("t", -3); String gender=str[3]; context.write(new Text(gender), new Text(value)); } catch(Exception e) { System.out.println(e.getMessage()); } } } //Reducer class public static class ReduceClass extends Reducer<Text,Text,Text,IntWritable> { public int max = -1; public void reduce(Text key, Iterable <Text> values, Context context) throws IOException, InterruptedException { max = -1; for (Text val : values) { String [] str = val.toString().split("t", -3); if(Integer.parseInt(str[4])>max) max=Integer.parseInt(str[4]); } context.write(new Text(key), new IntWritable(max)); } } //Partitioner class public static class CaderPartitioner extends Partitioner < Text, Text > { @Override public int getPartition(Text key, Text value, int numReduceTasks) { String[] str = value.toString().split("t"); int age = Integer.parseInt(str[2]); if(numReduceTasks == 0) { return 0; } if(age<=20) { return 0; } else if(age>20 && age<=30) { return 1 % numReduceTasks; } else { return 2 % numReduceTasks; } } } @Override public int run(String[] arg) throws Exception { Configuration conf = getConf(); Job job = new Job(conf, "topsal"); job.setJarByClass(PartitionerExample.class); FileInputFormat.setInputPaths(job, new Path(arg[0])); FileOutputFormat.setOutputPath(job,new Path(arg[1])); job.setMapperClass(MapClass.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); //set partitioner statement job.setPartitionerClass(CaderPartitioner.class); job.setReducerClass(ReduceClass.class); job.setNumReduceTasks(3); job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); System.exit(job.waitForCompletion(true)? 0 : 1); return 0; } public static void main(String ar[]) throws Exception { int res = ToolRunner.run(new Configuration(), new PartitionerExample(),ar); System.exit(0); } }
Сохраните приведенный выше код как PartitionerExample.java в «/ home / hadoop / hadoopPartitioner». Компиляция и выполнение программы приведены ниже.
Компиляция и выполнение
Предположим, мы находимся в домашнем каталоге пользователя Hadoop (например, / home / hadoop).
Следуйте инструкциям ниже, чтобы скомпилировать и выполнить вышеуказанную программу.
Шаг 1 – Загрузите Hadoop-core-1.2.1.jar, который используется для компиляции и запуска программы MapReduce. Вы можете скачать банку с mvnrepository.com .
Допустим, загруженная папка имеет вид «/ home / hadoop / hadoopPartitioner»
Шаг 2 – Следующие команды используются для компиляции программы PartitionerExample.java и создания jar для программы.
$ javac -classpath hadoop-core-1.2.1.jar -d ProcessUnits.java $ jar -cvf PartitionerExample.jar -C .
Шаг 3 – Используйте следующую команду для создания входного каталога в HDFS.
$HADOOP_HOME/bin/hadoop fs -mkdir input_dir
Шаг 4 – Используйте следующую команду, чтобы скопировать входной файл с именем input.txt во входной каталог HDFS.
$HADOOP_HOME/bin/hadoop fs -put /home/hadoop/hadoopPartitioner/input.txt input_dir
Шаг 5 – Используйте следующую команду, чтобы проверить файлы во входном каталоге.
$HADOOP_HOME/bin/hadoop fs -ls input_dir/
Шаг 6 – Используйте следующую команду, чтобы запустить приложение Top salary, взяв входные файлы из входного каталога.
$HADOOP_HOME/bin/hadoop jar PartitionerExample.jar partitionerexample.PartitionerExample input_dir/input.txt output_dir
Подождите некоторое время, пока файл не запустится. После выполнения выходные данные содержат несколько входных разбиений, задач сопоставления и задач редуктора.
15/02/04 15:19:51 INFO mapreduce.Job: Job job_1423027269044_0021 completed successfully 15/02/04 15:19:52 INFO mapreduce.Job: Counters: 49 File System Counters FILE: Number of bytes read=467 FILE: Number of bytes written=426777 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=480 HDFS: Number of bytes written=72 HDFS: Number of read operations=12 HDFS: Number of large read operations=0 HDFS: Number of write operations=6 Job Counters Launched map tasks=1 Launched reduce tasks=3 Data-local map tasks=1 Total time spent by all maps in occupied slots (ms)=8212 Total time spent by all reduces in occupied slots (ms)=59858 Total time spent by all map tasks (ms)=8212 Total time spent by all reduce tasks (ms)=59858 Total vcore-seconds taken by all map tasks=8212 Total vcore-seconds taken by all reduce tasks=59858 Total megabyte-seconds taken by all map tasks=8409088 Total megabyte-seconds taken by all reduce tasks=61294592 Map-Reduce Framework Map input records=13 Map output records=13 Map output bytes=423 Map output materialized bytes=467 Input split bytes=119 Combine input records=0 Combine output records=0 Reduce input groups=6 Reduce shuffle bytes=467 Reduce input records=13 Reduce output records=6 Spilled Records=26 Shuffled Maps =3 Failed Shuffles=0 Merged Map outputs=3 GC time elapsed (ms)=224 CPU time spent (ms)=3690 Physical memory (bytes) snapshot=553816064 Virtual memory (bytes) snapshot=3441266688 Total committed heap usage (bytes)=334102528 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=361 File Output Format Counters Bytes Written=72
Шаг 7 – Используйте следующую команду для проверки результирующих файлов в выходной папке.
$HADOOP_HOME/bin/hadoop fs -ls output_dir/
Вы найдете выходные данные в трех файлах, потому что вы используете в своей программе три секционера и три редуктора.
Шаг 8 – Используйте следующую команду, чтобы увидеть выходные данные в файле Part-00000 . Этот файл создан HDFS.
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000
Выход в Part-00000
Female 15000 Male 40000
Используйте следующую команду, чтобы увидеть выходные данные в файле Part-00001 .
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00001
Выход в Part-00001
Female 35000 Male 31000
Используйте следующую команду, чтобы увидеть выходные данные в файле Part-00002 .
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00002
Выход в Part-00002
Female 51000 Male 50000
MapReduce – Combiners
Combiner, также известный как полуредуктор, является необязательным классом, который работает, принимая входные данные из класса Map и затем передавая выходные пары ключ-значение в класс Reducer.
Основная функция Combiner состоит в том, чтобы суммировать выходные записи карты с одним и тем же ключом. Выход (сбор значения ключа) объединителя будет отправлен по сети фактической задаче «Редуктор» в качестве входных данных.
Сумматор
Класс Combiner используется между классом Map и классом Reduce для уменьшения объема передачи данных между Map и Reduce. Обычно выходные данные задачи карты большие, а данные, передаваемые в задачу сокращения, большие.
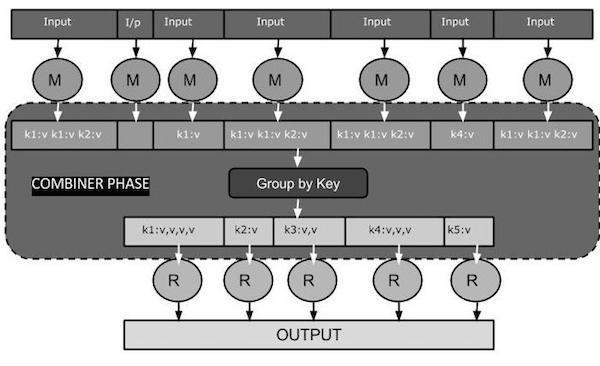
На следующей диаграмме задачи MapReduce показана ФАЗА КОМБИНИРОВАНИЯ.
Как работает Combiner?
Вот краткое описание того, как работает MapReduce Combiner:
-
У объединителя нет предопределенного интерфейса, и он должен реализовывать метод Redu () интерфейса Reducer.
-
Комбайнер работает с каждым ключом вывода карты. Он должен иметь те же типы значений выходного ключа, что и класс Reducer.
-
Объединитель может создавать сводную информацию из большого набора данных, поскольку он заменяет исходный вывод карты.
У объединителя нет предопределенного интерфейса, и он должен реализовывать метод Redu () интерфейса Reducer.
Комбайнер работает с каждым ключом вывода карты. Он должен иметь те же типы значений выходного ключа, что и класс Reducer.
Объединитель может создавать сводную информацию из большого набора данных, поскольку он заменяет исходный вывод карты.
Хотя Combiner не является обязательным, он помогает разделить данные на несколько групп для фазы сокращения, что упрощает обработку.
Реализация MapReduce Combiner
Следующий пример дает теоретическое представление о комбайнерах. Предположим, у нас есть следующий входной текстовый файл с именем input.txt для MapReduce.
What do you mean by Object What do you know about Java What is Java Virtual Machine How Java enabled High Performance
Важные этапы программы MapReduce с Combiner обсуждаются ниже.
Record Reader
Это первая фаза MapReduce, где Record Reader считывает каждую строку из входного текстового файла в виде текста и выдает выходные данные в виде пар ключ-значение.
Ввод – построчно текст из входного файла.
Выход – формирует пары ключ-значение. Ниже приведен набор ожидаемых пар ключ-значение.
<1, What do you mean by Object> <2, What do you know about Java> <3, What is Java Virtual Machine> <4, How Java enabled High Performance>
Фаза карты
Фаза Map принимает входные данные из Record Reader, обрабатывает их и создает выходные данные в виде другого набора пар ключ-значение.
Вход – следующая пара ключ-значение – это вход, полученный от устройства чтения записей.
<1, What do you mean by Object> <2, What do you know about Java> <3, What is Java Virtual Machine> <4, How Java enabled High Performance>
Фаза Map считывает каждую пару ключ-значение, делит каждое слово на значение, используя StringTokenizer, обрабатывает каждое слово как ключ, а счетчик этого слова – как значение. В следующем фрагменте кода показаны класс Mapper и функция map.
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Context context) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); } } }
Вывод – ожидаемый вывод выглядит следующим образом –
<What,1> <do,1> <you,1> <mean,1> <by,1> <Object,1> <What,1> <do,1> <you,1> <know,1> <about,1> <Java,1> <What,1> <is,1> <Java,1> <Virtual,1> <Machine,1> <How,1> <Java,1> <enabled,1> <High,1> <Performance,1>
Фаза Combiner
Фаза Combiner берет каждую пару ключ-значение из фазы Map, обрабатывает ее и создает выходные данные в виде пар набора ключ-значение .
Ввод – следующая пара ключ-значение является вводом, взятым из фазы карты.
<What,1> <do,1> <you,1> <mean,1> <by,1> <Object,1> <What,1> <do,1> <you,1> <know,1> <about,1> <Java,1> <What,1> <is,1> <Java,1> <Virtual,1> <Machine,1> <How,1> <Java,1> <enabled,1> <High,1> <Performance,1>
Фаза Combiner считывает каждую пару ключ-значение, объединяет общие слова как ключ и значения как коллекцию. Как правило, код и работа для Combiner аналогичны таковым для Reducer. Ниже приведен фрагмент кода для объявления классов Mapper, Combiner и Reducer.
job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class);
Вывод – ожидаемый вывод выглядит следующим образом –
<What,1,1,1> <do,1,1> <you,1,1> <mean,1> <by,1> <Object,1> <know,1> <about,1> <Java,1,1,1> <is,1> <Virtual,1> <Machine,1> <How,1> <enabled,1> <High,1> <Performance,1>
Фаза редуктора
Фаза редуктора берет каждую пару сбора ключ-значение из фазы Combiner, обрабатывает ее и передает выходные данные в виде пар ключ-значение. Обратите внимание, что функциональность Combiner такая же, как и у Reducer.
Вход – следующая пара ключ-значение является входом, взятым из фазы Combiner.
<What,1,1,1> <do,1,1> <you,1,1> <mean,1> <by,1> <Object,1> <know,1> <about,1> <Java,1,1,1> <is,1> <Virtual,1> <Machine,1> <How,1> <enabled,1> <High,1> <Performance,1>
Фаза редуктора считывает каждую пару ключ-значение. Ниже приведен фрагмент кода для Combiner.
public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> { private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } }
Выходные данные – ожидаемый выходной сигнал от фазы редуктора следующий –
<What,3> <do,2> <you,2> <mean,1> <by,1> <Object,1> <know,1> <about,1> <Java,3> <is,1> <Virtual,1> <Machine,1> <How,1> <enabled,1> <High,1> <Performance,1>
Record Writer
Это последняя фаза MapReduce, где Record Writer записывает каждую пару ключ-значение из фазы Reducer и отправляет вывод в виде текста.
Ввод – каждая пара ключ-значение из фазы редуктора вместе с форматом вывода.
Вывод – он дает вам пары ключ-значение в текстовом формате. Ниже приводится ожидаемый результат.
What 3 do 2 you 2 mean 1 by 1 Object 1 know 1 about 1 Java 3 is 1 Virtual 1 Machine 1 How 1 enabled 1 High 1 Performance 1
Пример программы
Следующий блок кода подсчитывает количество слов в программе.
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>
{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException
{
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens())
{
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable>
{
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException
{
int sum = 0;
for (IntWritable val : values)
{
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception
{
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
Сохраните вышеуказанную программу как WordCount.java . Компиляция и выполнение программы приведены ниже.
Компиляция и выполнение
Предположим, мы находимся в домашнем каталоге пользователя Hadoop (например, / home / hadoop).
Следуйте инструкциям ниже, чтобы скомпилировать и выполнить вышеуказанную программу.
Шаг 1 – Используйте следующую команду, чтобы создать каталог для хранения скомпилированных классов Java.
$ mkdir units
Шаг 2 – Загрузите Hadoop-core-1.2.1.jar, который используется для компиляции и выполнения программы MapReduce. Вы можете скачать банку с mvnrepository.com .
Давайте предположим, что загруженная папка – / home / hadoop /.
Шаг 3 – Используйте следующие команды для компиляции программы WordCount.java и для создания jar для программы.
$ javac -classpath hadoop-core-1.2.1.jar -d units WordCount.java $ jar -cvf units.jar -C units/ .
Шаг 4 – Используйте следующую команду для создания входного каталога в HDFS.
$HADOOP_HOME/bin/hadoop fs -mkdir input_dir
Шаг 5 – Используйте следующую команду, чтобы скопировать входной файл с именем input.txt во входной каталог HDFS.
$HADOOP_HOME/bin/hadoop fs -put /home/hadoop/input.txt input_dir
Шаг 6 – Используйте следующую команду, чтобы проверить файлы во входном каталоге.
$HADOOP_HOME/bin/hadoop fs -ls input_dir/
Шаг 7 – Используйте следующую команду, чтобы запустить приложение Word count, взяв входные файлы из входного каталога.
$HADOOP_HOME/bin/hadoop jar units.jar hadoop.ProcessUnits input_dir output_dir
Подождите некоторое время, пока файл не запустится. После выполнения выходные данные содержат несколько входных разбиений, задачи Map и задачи Reducer.
Шаг 8 – Используйте следующую команду для проверки результирующих файлов в выходной папке.
$HADOOP_HOME/bin/hadoop fs -ls output_dir/
Шаг 9 – Используйте следующую команду, чтобы увидеть выходные данные в файле Part-00000 . Этот файл создан HDFS.
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000
Ниже приводится вывод, сгенерированный программой MapReduce.
What 3 do 2 you 2 mean 1 by 1 Object 1 know 1 about 1 Java 3 is 1 Virtual 1 Machine 1 How 1 enabled 1 High 1 Performance 1
MapReduce – Администрирование Hadoop
В этой главе описывается администрирование Hadoop, которое включает администрирование HDFS и MapReduce.
-
Администрирование HDFS включает в себя мониторинг файловой структуры HDFS, расположения и обновленных файлов.
-
Администрирование MapReduce включает мониторинг списка приложений, конфигурации узлов, состояния приложений и т. Д.
Администрирование HDFS включает в себя мониторинг файловой структуры HDFS, расположения и обновленных файлов.
Администрирование MapReduce включает мониторинг списка приложений, конфигурации узлов, состояния приложений и т. Д.
HDFS мониторинг
HDFS (распределенная файловая система Hadoop) содержит пользовательские каталоги, входные и выходные файлы. Используйте команды MapReduce, put и get, для хранения и извлечения.
После запуска инфраструктуры Hadoop (демонов), передав команду «start-all.sh» в «/ $ HADOOP_HOME / sbin», передайте следующий URL-адрес в браузер «http: // localhost: 50070». Вы должны увидеть следующий экран в вашем браузере.
На следующем снимке экрана показано, как просматривать HDFS.
На следующем снимке экрана показана файловая структура HDFS. Он показывает файлы в каталоге «/ user / hadoop».
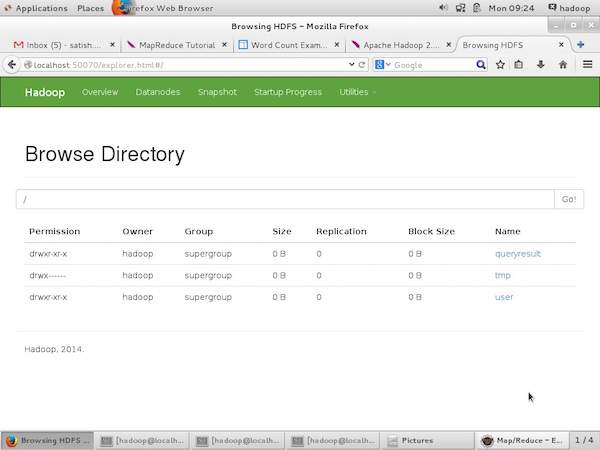
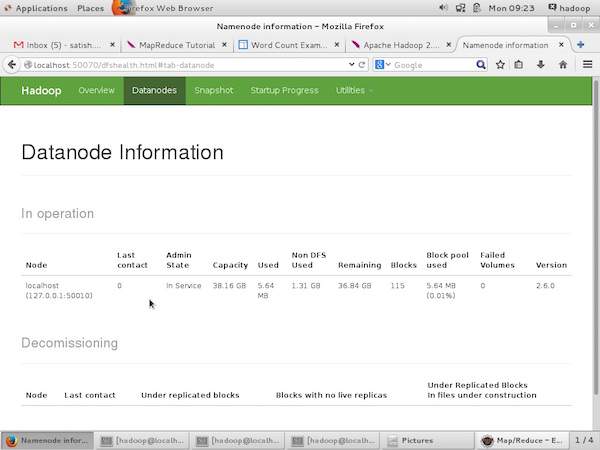
На следующем снимке экрана показана информация Datanode в кластере. Здесь вы можете найти один узел с его конфигурациями и возможностями.
MapReduce Job Monitoring
Приложение MapReduce представляет собой набор заданий (задание Map, Combiner, Partitioner и Reduce job). Обязательно следить и поддерживать следующее –
- Конфигурация датододы, где приложение подходит.
- Количество датододов и ресурсов, используемых в приложении.
Чтобы контролировать все эти вещи, обязательно, чтобы у нас был пользовательский интерфейс. После запуска инфраструктуры Hadoop, передав команду «start-all.sh» в «/ $ HADOOP_HOME / sbin», передайте следующий URL-адрес в браузер «http: // localhost: 8080». Вы должны увидеть следующий экран в вашем браузере.
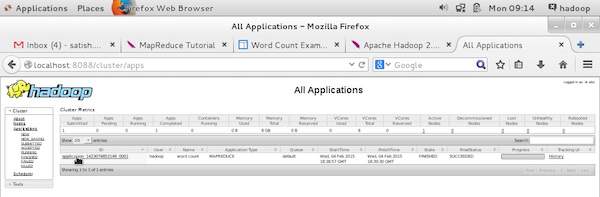
На приведенном выше снимке экрана указатель руки находится на идентификаторе приложения. Просто нажмите на него, чтобы найти следующий экран в вашем браузере. Это описывает следующее –
-
На каком пользователе запущено текущее приложение
-
Название приложения
-
Тип этого приложения
-
Текущий статус, Финальный статус
-
Время запуска приложения, прошедшее (завершенное время), если оно завершено во время мониторинга
-
История этого приложения, т.е. информация журнала
-
И, наконец, информация об узлах, т. Е. Об узлах, которые участвовали в запуске приложения.
На каком пользователе запущено текущее приложение
Название приложения
Тип этого приложения
Текущий статус, Финальный статус
Время запуска приложения, прошедшее (завершенное время), если оно завершено во время мониторинга
История этого приложения, т.е. информация журнала
И, наконец, информация об узлах, т. Е. Об узлах, которые участвовали в запуске приложения.
На следующем снимке экрана показаны детали конкретного приложения.
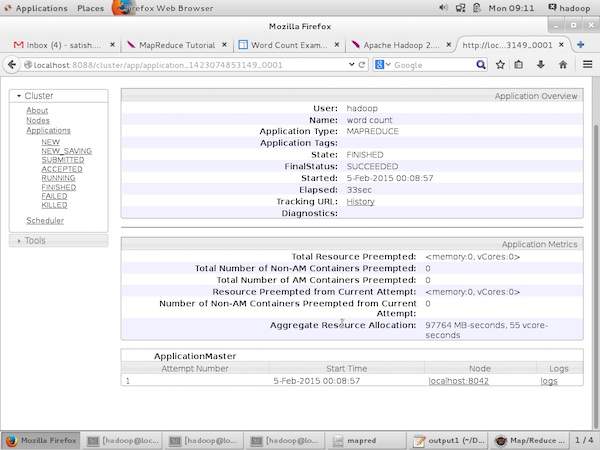
На следующем снимке экрана показана информация о запущенных узлах. Здесь скриншот содержит только один узел. Указатель руки показывает адрес локального хоста работающего узла.
MapReduce is a programming model and an associated implementation for processing and generating big data sets with a parallel, distributed algorithm on a cluster.[1][2][3]
A MapReduce program is composed of a map procedure, which performs filtering and sorting (such as sorting students by first name into queues, one queue for each name), and a reduce method, which performs a summary operation (such as counting the number of students in each queue, yielding name frequencies). The «MapReduce System» (also called «infrastructure» or «framework») orchestrates the processing by marshalling the distributed servers, running the various tasks in parallel, managing all communications and data transfers between the various parts of the system, and providing for redundancy and fault tolerance.
The model is a specialization of the split-apply-combine strategy for data analysis.[4]
It is inspired by the map and reduce functions commonly used in functional programming,[5] although their purpose in the MapReduce framework is not the same as in their original forms.[6] The key contributions of the MapReduce framework are not the actual map and reduce functions (which, for example, resemble the 1995 Message Passing Interface standard’s[7] reduce[8] and scatter[9] operations), but the scalability and fault-tolerance achieved for a variety of applications by optimizing the execution engine[citation needed]. As such, a single-threaded implementation of MapReduce is usually not faster than a traditional (non-MapReduce) implementation; any gains are usually only seen with multi-threaded implementations on multi-processor hardware.[10] The use of this model is beneficial only when the optimized distributed shuffle operation (which reduces network communication cost) and fault tolerance features of the MapReduce framework come into play. Optimizing the communication cost is essential to a good MapReduce algorithm.[11]
MapReduce libraries have been written in many programming languages, with different levels of optimization. A popular open-source implementation that has support for distributed shuffles is part of Apache Hadoop. The name MapReduce originally referred to the proprietary Google technology, but has since been genericized. By 2014, Google was no longer using MapReduce as their primary big data processing model,[12] and development on Apache Mahout had moved on to more capable and less disk-oriented mechanisms that incorporated full map and reduce capabilities.[13]
Overview[edit]
MapReduce is a framework for processing parallelizable problems across large datasets using a large number of computers (nodes), collectively referred to as a cluster (if all nodes are on the same local network and use similar hardware) or a grid (if the nodes are shared across geographically and administratively distributed systems, and use more heterogeneous hardware). Processing can occur on data stored either in a filesystem (unstructured) or in a database (structured). MapReduce can take advantage of the locality of data, processing it near the place it is stored in order to minimize communication overhead.
A MapReduce framework (or system) is usually composed of three operations (or steps):
- Map: each worker node applies the
mapfunction to the local data, and writes the output to a temporary storage. A master node ensures that only one copy of the redundant input data is processed. - Shuffle: worker nodes redistribute data based on the output keys (produced by the
mapfunction), such that all data belonging to one key is located on the same worker node. - Reduce: worker nodes now process each group of output data, per key, in parallel.
MapReduce allows for the distributed processing of the map and reduction operations. Maps can be performed in parallel, provided that each mapping operation is independent of the others; in practice, this is limited by the number of independent data sources and/or the number of CPUs near each source. Similarly, a set of ‘reducers’ can perform the reduction phase, provided that all outputs of the map operation that share the same key are presented to the same reducer at the same time, or that the reduction function is associative. While this process often appears inefficient compared to algorithms that are more sequential (because multiple instances of the reduction process must be run), MapReduce can be applied to significantly larger datasets than a single «commodity» server can handle – a large server farm can use MapReduce to sort a petabyte of data in only a few hours.[14] The parallelism also offers some possibility of recovering from partial failure of servers or storage during the operation: if one mapper or reducer fails, the work can be rescheduled – assuming the input data are still available.
Another way to look at MapReduce is as a 5-step parallel and distributed computation:
- Prepare the Map() input – the «MapReduce system» designates Map processors, assigns the input key K1 that each processor would work on, and provides that processor with all the input data associated with that key.
- Run the user-provided Map() code – Map() is run exactly once for each K1 key, generating output organized by key K2.
- «Shuffle» the Map output to the Reduce processors – the MapReduce system designates Reduce processors, assigns the K2 key each processor should work on, and provides that processor with all the Map-generated data associated with that key.
- Run the user-provided Reduce() code – Reduce() is run exactly once for each K2 key produced by the Map step.
- Produce the final output – the MapReduce system collects all the Reduce output, and sorts it by K2 to produce the final outcome.
These five steps can be logically thought of as running in sequence – each step starts only after the previous step is completed – although in practice they can be interleaved as long as the final result is not affected.
In many situations, the input data might have already been distributed («sharded») among many different servers, in which case step 1 could sometimes be greatly simplified by assigning Map servers that would process the locally present input data. Similarly, step 3 could sometimes be sped up by assigning Reduce processors that are as close as possible to the Map-generated data they need to process.
Logical view[edit]
The Map and Reduce functions of MapReduce are both defined with respect to data structured in (key, value) pairs. Map takes one pair of data with a type in one data domain, and returns a list of pairs in a different domain:
Map(k1,v1) → list(k2,v2)
The Map function is applied in parallel to every pair (keyed by k1) in the input dataset. This produces a list of pairs (keyed by k2) for each call.
After that, the MapReduce framework collects all pairs with the same key (k2) from all lists and groups them together, creating one group for each key.
The Reduce function is then applied in parallel to each group, which in turn produces a collection of values in the same domain:
Reduce(k2, list (v2)) → list((k3, v3))[15]
Each Reduce call typically produces either one key value pair or an empty return, though one call is allowed to return more than one key value pair. The returns of all calls are collected as the desired result list.
Thus the MapReduce framework transforms a list of (key, value) pairs into another list of (key, value) pairs.[16] This behavior is different from the typical functional programming map and reduce combination, which accepts a list of arbitrary values and returns one single value that combines all the values returned by map.
It is necessary but not sufficient to have implementations of the map and reduce abstractions in order to implement MapReduce. Distributed implementations of MapReduce require a means of connecting the processes performing the Map and Reduce phases. This may be a distributed file system. Other options are possible, such as direct streaming from mappers to reducers, or for the mapping processors to serve up their results to reducers that query them.
Examples[edit]
The canonical MapReduce example counts the appearance of each word in a set of documents:[17]
function map(String name, String document):
// name: document name
// document: document contents
for each word w in document:
emit (w, 1)
function reduce(String word, Iterator partialCounts):
// word: a word
// partialCounts: a list of aggregated partial counts
sum = 0
for each pc in partialCounts:
sum += pc
emit (word, sum)
Here, each document is split into words, and each word is counted by the map function, using the word as the result key. The framework puts together all the pairs with the same key and feeds them to the same call to reduce. Thus, this function just needs to sum all of its input values to find the total appearances of that word.
As another example, imagine that for a database of 1.1 billion people, one would like to compute the average number of social contacts a person has according to age. In SQL, such a query could be expressed as:
SELECT age, AVG(contacts) FROM social.person GROUP BY age ORDER BY age
Using MapReduce, the K1 key values could be the integers 1 through 1100, each representing a batch of 1 million records, the K2 key value could be a person’s age in years, and this computation could be achieved using the following functions:
function Map is
input: integer K1 between 1 and 1100, representing a batch of 1 million social.person records
for each social.person record in the K1 batch do
let Y be the person's age
let N be the number of contacts the person has
produce one output record (Y,(N,1))
repeat
end function
function Reduce is
input: age (in years) Y
for each input record (Y,(N,C)) do
Accumulate in S the sum of N*C
Accumulate in Cnew the sum of C
repeat
let A be S/Cnew
produce one output record (Y,(A,Cnew))
end function
Note that in the Reduce function, C is the count of people having in total N contacts, so in the Map function it is natural to write C=1, since every output pair is referring to the contacts of one single person.
The MapReduce system would line up the 1100 Map processors, and would provide each with its corresponding 1 million input records. The Map step would produce 1.1 billion (Y,(N,1)) records, with Y values ranging between, say, 8 and 103. The MapReduce System would then line up the 96 Reduce processors by performing shuffling operation of the key/value pairs due to the fact that we need average per age, and provide each with its millions of corresponding input records. The Reduce step would result in the much reduced set of only 96 output records (Y,A), which would be put in the final result file, sorted by Y.
The count info in the record is important if the processing is reduced more than one time. If we did not add the count of the records, the computed average would be wrong, for example:
-- map output #1: age, quantity of contacts 10, 9 10, 9 10, 9
-- map output #2: age, quantity of contacts 10, 9 10, 9
-- map output #3: age, quantity of contacts 10, 10
If we reduce files #1 and #2, we will have a new file with an average of 9 contacts for a 10-year-old person ((9+9+9+9+9)/5):
-- reduce step #1: age, average of contacts 10, 9
If we reduce it with file #3, we lose the count of how many records we’ve already seen, so we end up with an average of 9.5 contacts for a 10-year-old person ((9+10)/2), which is wrong. The correct answer is 9.166 = 55 / 6 = (9×3+9×2+10×1)/(3+2+1).
Dataflow[edit]
Software framework architecture adheres to open-closed principle where code is effectively divided into unmodifiable frozen spots and extensible hot spots. The frozen spot of the MapReduce framework is a large distributed sort. The hot spots, which the application defines, are:
- an input reader
- a Map function
- a partition function
- a compare function
- a Reduce function
- an output writer
Input reader[edit]
The input reader divides the input into appropriate size ‘splits’ (in practice, typically, 64 MB to 128 MB) and the framework assigns one split to each Map function. The input reader reads data from stable storage (typically, a distributed file system) and generates key/value pairs.
A common example will read a directory full of text files and return each line as a record.
Map function[edit]
The Map function takes a series of key/value pairs, processes each, and generates zero or more output key/value pairs. The input and output types of the map can be (and often are) different from each other.
If the application is doing a word count, the map function would break the line into words and output a key/value pair for each word. Each output pair would contain the word as the key and the number of instances of that word in the line as the value.
Partition function[edit]
Each Map function output is allocated to a particular reducer by the application’s partition function for sharding purposes. The partition function is given the key and the number of reducers and returns the index of the desired reducer.
A typical default is to hash the key and use the hash value modulo the number of reducers. It is important to pick a partition function that gives an approximately uniform distribution of data per shard for load-balancing purposes, otherwise the MapReduce operation can be held up waiting for slow reducers to finish
(i.e. the reducers assigned the larger shares of the non-uniformly partitioned data).
Between the map and reduce stages, the data are shuffled (parallel-sorted / exchanged between nodes) in order to move the data from the map node that produced them to the shard in which they will be reduced. The shuffle can sometimes take longer than the computation time depending on network bandwidth, CPU speeds, data produced and time taken by map and reduce computations.
Comparison function[edit]
The input for each Reduce is pulled from the machine where the Map ran and sorted using the application’s comparison function.
Reduce function[edit]
The framework calls the application’s Reduce function once for each unique key in the sorted order. The Reduce can iterate through the values that are associated with that key and produce zero or more outputs.
In the word count example, the Reduce function takes the input values, sums them and generates a single output of the word and the final sum.
Output writer[edit]
The Output Writer writes the output of the Reduce to the stable storage.
Theoretical background[edit]
Properties of Monoid are the basis for ensuring the validity of Map/Reduce operations.[18][19]
In Algebird package[20] a Scala implementation of Map/Reduce explicitly requires Monoid class type
.[21]
The operations of MapReduce deal with two types: the type A of input data being mapped, and the type B of output data being reduced.
Map operation takes individual values of type A and produces, for each a:A a value b:B; Reduce operation requires a binary operation • defined on values of type B; it consists of folding all available b:B to a single value.
From basic requirements point of view, any MapReduce operation must involve the ability to arbitrarily regroup data being reduced. Such a requirement amounts to two properties of operation •:
- associativity: (x • y) • z = x • (y • z)
- existence of neutral element e such that e • x = x • e = x for every x:B.
The second property guarantees that, when parallelized over multiple nodes, the nodes that don’t have any data to process would have no impact on the result.
These two properties amount to having a Monoid (B, •, e) on values of type B with operation • and with neutral element e.
There’s no requirements on the values of type A; an arbitrary function A → B can be used for Map operation. This means that we have a Catamorphism A* → (B, •, e). Here A* denotes a Kleene star, also known as the type of lists over A.
Shuffle operation per se is not related to the essence of MapReduce; it’s needed to distribute calculations over the cloud.
It follows from the above that not every binary Reduce operation will work in MapReduce. Here are the counter-examples:
- building a tree from subtrees: this operation is not associative, and the result will depend on grouping;
- direct calculation of averages: avg is also not associative (and it has no neutral element); to calculate an average, one needs to calculate moments.
Performance considerations[edit]
MapReduce programs are not guaranteed to be fast. The main benefit of this programming model is to exploit the optimized shuffle operation of the platform, and only having to write the Map and Reduce parts of the program.
In practice, the author of a MapReduce program however has to take the shuffle step into consideration; in particular the partition function and the amount of data written by the Map function can have a large impact on the performance and scalability. Additional modules such as the Combiner function can help to reduce the amount of data written to disk, and transmitted over the network. MapReduce applications can achieve sub-linear speedups under specific circumstances.[22]
When designing a MapReduce algorithm, the author needs to choose a good tradeoff[11] between the computation and the communication costs. Communication cost often dominates the computation cost,[11][22] and many MapReduce implementations are designed to write all communication to distributed storage for crash recovery.
In tuning performance of MapReduce, the complexity of mapping, shuffle, sorting (grouping by the key), and reducing has to be taken into account. The amount of data produced by the mappers is a key parameter that shifts the bulk of the computation cost between mapping and reducing. Reducing includes sorting (grouping of the keys) which has nonlinear complexity. Hence, small partition sizes reduce sorting time, but there is a trade-off because having a large number of reducers may be impractical. The influence of split unit size is marginal (unless chosen particularly badly, say <1MB). The gains from some mappers reading load from local disks, on average, is minor.[23]
For processes that complete quickly, and where the data fits into main memory of a single machine or a small cluster, using a MapReduce framework usually is not effective. Since these frameworks are designed to recover from the loss of whole nodes during the computation, they write interim results to distributed storage. This crash recovery is expensive, and only pays off when the computation involves many computers and a long runtime of the computation. A task that completes in seconds can just be restarted in the case of an error, and the likelihood of at least one machine failing grows quickly with the cluster size. On such problems, implementations keeping all data in memory and simply restarting a computation on node failures or —when the data is small enough— non-distributed solutions will often be faster than a MapReduce system.
Distribution and reliability[edit]
MapReduce achieves reliability by parceling out a number of operations on the set of data to each node in the network. Each node is expected to report back periodically with completed work and status updates. If a node falls silent for longer than that interval, the master node (similar to the master server in the Google File System) records the node as dead and sends out the node’s assigned work to other nodes. Individual operations use atomic operations for naming file outputs as a check to ensure that there are not parallel conflicting threads running. When files are renamed, it is possible to also copy them to another name in addition to the name of the task (allowing for side-effects).
The reduce operations operate much the same way. Because of their inferior properties with regard to parallel operations, the master node attempts to schedule reduce operations on the same node, or in the same rack as the node holding the data being operated on. This property is desirable as it conserves bandwidth across the backbone network of the datacenter.
Implementations are not necessarily highly reliable. For example, in older versions of Hadoop the NameNode was a single point of failure for the distributed filesystem. Later versions of Hadoop have high availability with an active/passive failover for the «NameNode.»
Uses[edit]
MapReduce is useful in a wide range of applications, including distributed pattern-based searching, distributed sorting, web link-graph reversal, Singular Value Decomposition,[24] web access log stats, inverted index construction, document clustering, machine learning,[25] and statistical machine translation. Moreover, the MapReduce model has been adapted to several computing environments like multi-core and many-core systems,[26][27][28] desktop grids,[29]
multi-cluster,[30] volunteer computing environments,[31] dynamic cloud environments,[32] mobile environments,[33] and high-performance computing environments.[34]
At Google, MapReduce was used to completely regenerate Google’s index of the World Wide Web. It replaced the old ad hoc programs that updated the index and ran the various analyses.[35] Development at Google has since moved on to technologies such as Percolator, FlumeJava[36] and MillWheel that offer streaming operation and updates instead of batch processing, to allow integrating «live» search results without rebuilding the complete index.[37]
MapReduce’s stable inputs and outputs are usually stored in a distributed file system. The transient data are usually stored on local disk and fetched remotely by the reducers.
Criticism[edit]
Lack of novelty[edit]
David DeWitt and Michael Stonebraker, computer scientists specializing in parallel databases and shared-nothing architectures, have been critical of the breadth of problems that MapReduce can be used for.[38] They called its interface too low-level and questioned whether it really represents the paradigm shift its proponents have claimed it is.[39] They challenged the MapReduce proponents’ claims of novelty, citing Teradata as an example of prior art that has existed for over two decades. They also compared MapReduce programmers to CODASYL programmers, noting both are «writing in a low-level language performing low-level record manipulation.»[39] MapReduce’s use of input files and lack of schema support prevents the performance improvements enabled by common database system features such as B-trees and hash partitioning, though projects such as Pig (or PigLatin), Sawzall, Apache Hive,[40] HBase[41] and Bigtable[41][42] are addressing some of these problems.
Greg Jorgensen wrote an article rejecting these views.[43] Jorgensen asserts that DeWitt and Stonebraker’s entire analysis is groundless as MapReduce was never designed nor intended to be used as a database.
DeWitt and Stonebraker have subsequently published a detailed benchmark study in 2009 comparing performance of Hadoop’s MapReduce and RDBMS approaches on several specific problems.[44] They concluded that relational databases offer real advantages for many kinds of data use, especially on complex processing or where the data is used across an enterprise, but that MapReduce may be easier for users to adopt for simple or one-time processing tasks.
The MapReduce programming paradigm was also described in Danny Hillis’s 1985 thesis [45] intended for use on the Connection Machine, where it was called «xapping/reduction»[46] and relied upon that machine’s special hardware to accelerate both map and reduce. The dialect ultimately used for the Connection Machine, the 1986 StarLisp, had parallel *map and reduce!!,[47] which in turn was based on the 1984 Common Lisp, which had non-parallel map and reduce built in.[48] The tree-like approach that the Connection Machine’s hypercube architecture uses to execute reduce in  time[49] is effectively the same as the approach referred to within the Google paper as prior work.[3]: 11
time[49] is effectively the same as the approach referred to within the Google paper as prior work.[3]: 11
In 2010 Google was granted what is described as a patent on MapReduce. The patent, filed in 2004, may cover use of MapReduce by open source software such as Hadoop, CouchDB, and others. In Ars Technica, an editor acknowledged Google’s role in popularizing the MapReduce concept, but questioned whether the patent was valid or novel.[50][51] In 2013, as part of its «Open Patent Non-Assertion (OPN) Pledge», Google pledged to only use the patent defensively.[52][53] The patent is expected to expire on 23 December 2026.[54]
Restricted programming framework[edit]
MapReduce tasks must be written as acyclic dataflow programs, i.e. a stateless mapper followed by a stateless reducer, that are executed by a batch job scheduler. This paradigm makes repeated querying of datasets difficult and imposes limitations that are felt in fields such as graph processing[55] where iterative algorithms that revisit a single working set multiple times are the norm, as well as, in the presence of disk-based data with high latency, even the field of machine learning where multiple passes through the data are required even though algorithms can tolerate serial access to the data each pass.[56]
See also[edit]
- Bird–Meertens formalism
Implementations of MapReduce[edit]
- Apache CouchDB
- Apache Hadoop
- Infinispan
- Riak
References[edit]
- ^ «MapReduce Tutorial». Apache Hadoop. Retrieved 3 July 2019.
- ^ «Google spotlights data center inner workings». cnet.com. 30 May 2008. Archived from the original on 19 October 2013. Retrieved 31 May 2008.
- ^ a b «MapReduce: Simplified Data Processing on Large Clusters» (PDF). googleusercontent.com.
- ^ Wickham, Hadley (2011). «The split-apply-combine strategy for data analysis». Journal of Statistical Software. 40: 1–29. doi:10.18637/jss.v040.i01.
- ^ «Our abstraction is inspired by the map and reduce primitives present in Lisp and many other functional languages.» -«MapReduce: Simplified Data Processing on Large Clusters», by Jeffrey Dean and Sanjay Ghemawat; from Google Research
- ^ Lämmel, R. (2008). «Google’s Map Reduce programming model — Revisited». Science of Computer Programming. 70: 1–30. doi:10.1016/j.scico.2007.07.001.
- ^ http://www.mcs.anl.gov/research/projects/mpi/mpi-standard/mpi-report-2.0/mpi2-report.htm MPI 2 standard
- ^ «MPI Reduce and Allreduce · MPI Tutorial». mpitutorial.com.
- ^ «Performing Parallel Rank with MPI · MPI Tutorial». mpitutorial.com.
- ^ «MongoDB: Terrible MapReduce Performance». Stack Overflow. October 16, 2010.
The MapReduce implementation in MongoDB has little to do with map reduce apparently. Because for all I read, it is single-threaded, while map-reduce is meant to be used highly parallel on a cluster. … MongoDB MapReduce is single threaded on a single server…
- ^ a b c Ullman, J. D. (2012). «Designing good MapReduce algorithms». XRDS: Crossroads, the ACM Magazine for Students. 19: 30–34. doi:10.1145/2331042.2331053. S2CID 26498063.
- ^ Sverdlik, Yevgeniy (2014-06-25). «Google Dumps MapReduce in Favor of New Hyper-Scale Analytics System». Data Center Knowledge. Retrieved 2015-10-25.
«We don’t really use MapReduce anymore» [Urs Hölzle, senior vice president of technical infrastructure at Google]
- ^ Harris, Derrick (2014-03-27). «Apache Mahout, Hadoop’s original machine learning project, is moving on from MapReduce». Gigaom. Retrieved 2015-09-24.
Apache Mahout […] is joining the exodus away from MapReduce.
- ^ Czajkowski, Grzegorz; Marián Dvorský; Jerry Zhao; Michael Conley (7 September 2011). «Sorting Petabytes with MapReduce – The Next Episode». Retrieved 7 April 2014.
- ^ «MapReduce Tutorial».
- ^ «Apache/Hadoop-mapreduce». GitHub. 31 August 2021.
- ^ «Example: Count word occurrences». Google Research. Retrieved September 18, 2013.
- ^ Fegaras, Leonidas (2017). «An algebra for distributed Big Data analytics». Journal of Functional Programming. 28. doi:10.1017/S0956796817000193. S2CID 44629767.
- ^ Lin, Jimmy (29 Apr 2013). «Monoidify! Monoids as a Design Principle for Efficient MapReduce Algorithms». arXiv:1304.7544 [cs.DC].
- ^ «Abstract Algebra for Scala».
- ^ «Encoding Map-Reduce As A Monoid With Left Folding». 5 September 2016.
- ^ a b Senger, Hermes; Gil-Costa, Veronica; Arantes, Luciana; Marcondes, Cesar A. C.; Marín, Mauricio; Sato, Liria M.; da Silva, Fabrício A.B. (2015-01-01). «BSP cost and scalability analysis for MapReduce operations». Concurrency and Computation: Practice and Experience. 28 (8): 2503–2527. doi:10.1002/cpe.3628. hdl:10533/147670. ISSN 1532-0634. S2CID 33645927.
- ^ Berlińska, Joanna; Drozdowski, Maciej (2010-12-01). «Scheduling divisible MapReduce computations». Journal of Parallel and Distributed Computing. 71 (3): 450–459. doi:10.1016/j.jpdc.2010.12.004.
- ^ Bosagh Zadeh, Reza; Carlsson, Gunnar (2013). «Dimension Independent Matrix Square Using MapReduce» (PDF). Stanford University. arXiv:1304.1467. Bibcode:2013arXiv1304.1467B. Retrieved 12 July 2014.
- ^ Ng, Andrew Y.; Bradski, Gary; Chu, Cheng-Tao; Olukotun, Kunle; Kim, Sang Kyun; Lin, Yi-An; Yu, YuanYuan (2006). «Map-Reduce for Machine Learning on Multicore». NIPS 2006.
- ^ Ranger, C.; Raghuraman, R.; Penmetsa, A.; Bradski, G.; Kozyrakis, C. (2007). «Evaluating MapReduce for Multi-core and Multiprocessor Systems». 2007 IEEE 13th International Symposium on High Performance Computer Architecture. p. 13. CiteSeerX 10.1.1.220.8210. doi:10.1109/HPCA.2007.346181. ISBN 978-1-4244-0804-7. S2CID 12563671.
- ^ He, B.; Fang, W.; Luo, Q.; Govindaraju, N. K.; Wang, T. (2008). «Mars: a MapReduce framework on graphics processors» (PDF). Proceedings of the 17th international conference on Parallel architectures and compilation techniques – PACT ’08. p. 260. doi:10.1145/1454115.1454152. ISBN 9781605582825. S2CID 207169888.
- ^ Chen, R.; Chen, H.; Zang, B. (2010). «Tiled-MapReduce: optimizing resource usages of data-parallel applications on multicore with tiling». Proceedings of the 19th international conference on Parallel architectures and compilation techniques – PACT ’10. p. 523. doi:10.1145/1854273.1854337. ISBN 9781450301787. S2CID 2082196.
- ^ Tang, B.; Moca, M.; Chevalier, S.; He, H.; Fedak, G. (2010). «Towards MapReduce for Desktop Grid Computing» (PDF). 2010 International Conference on P2P, Parallel, Grid, Cloud and Internet Computing. p. 193. CiteSeerX 10.1.1.671.2763. doi:10.1109/3PGCIC.2010.33. ISBN 978-1-4244-8538-3. S2CID 15044391.
- ^ Luo, Y.; Guo, Z.; Sun, Y.; Plale, B.; Qiu, J.; Li, W. (2011). «A Hierarchical Framework for Cross-Domain MapReduce Execution» (PDF). Proceedings of the second international workshop on Emerging computational methods for the life sciences (ECMLS ’11). CiteSeerX 10.1.1.364.9898. doi:10.1145/1996023.1996026. ISBN 978-1-4503-0702-4. S2CID 15179363.
- ^ Lin, H.; Ma, X.; Archuleta, J.; Feng, W. C.; Gardner, M.; Zhang, Z. (2010). «MOON: MapReduce On Opportunistic eNvironments» (PDF). Proceedings of the 19th ACM International Symposium on High Performance Distributed Computing – HPDC ’10. p. 95. doi:10.1145/1851476.1851489. ISBN 9781605589428. S2CID 2351790.
- ^ Marozzo, F.; Talia, D.; Trunfio, P. (2012). «P2P-MapReduce: Parallel data processing in dynamic Cloud environments». Journal of Computer and System Sciences. 78 (5): 1382–1402. doi:10.1016/j.jcss.2011.12.021.
- ^ Dou, A.; Kalogeraki, V.; Gunopulos, D.; Mielikainen, T.; Tuulos, V. H. (2010). «Misco: a MapReduce framework for mobile systems». Proceedings of the 3rd International Conference on PErvasive Technologies Related to Assistive Environments – PETRA ’10. p. 1. doi:10.1145/1839294.1839332. ISBN 9781450300711. S2CID 14517696.
- ^ Wang, Yandong; Goldstone, Robin; Yu, Weikuan; Wang, Teng (May 2014). «Characterization and Optimization of Memory-Resident MapReduce on HPC Systems». 2014 IEEE 28th International Parallel and Distributed Processing Symposium. IEEE. pp. 799–808. doi:10.1109/IPDPS.2014.87. ISBN 978-1-4799-3800-1. S2CID 11157612.
- ^ «How Google Works». baselinemag.com. 7 July 2006.
As of October, Google was running about 3,000 computing jobs per day through MapReduce, representing thousands of machine-days, according to a presentation by Dean. Among other things, these batch routines analyze the latest Web pages and update Google’s indexes.
- ^ Chambers, Craig; Raniwala, Ashish; Perry, Frances; Adams, Stephen; Henry, Robert R.; Bradshaw, Robert; Weizenbaum, Nathan (1 January 2010). FlumeJava: Easy, Efficient Data-parallel Pipelines (PDF). Proceedings of the 31st ACM SIGPLAN Conference on Programming Language Design and Implementation. pp. 363–375. doi:10.1145/1806596.1806638. ISBN 9781450300193. S2CID 14888571. Archived from the original (PDF) on 23 September 2016. Retrieved 4 August 2016.
- ^ Peng, D., & Dabek, F. (2010, October). Large-scale Incremental Processing Using Distributed Transactions and Notifications. In OSDI (Vol. 10, pp. 1-15).
- ^ «Database Experts Jump the MapReduce Shark».
- ^ a b David DeWitt; Michael Stonebraker. «MapReduce: A major step backwards». craig-henderson.blogspot.com. Retrieved 2008-08-27.
- ^ «Apache Hive – Index of – Apache Software Foundation».
- ^ a b «HBase – HBase Home – Apache Software Foundation».
- ^ «Bigtable: A Distributed Storage System for Structured Data» (PDF).
- ^ Greg Jorgensen. «Relational Database Experts Jump The MapReduce Shark». typicalprogrammer.com. Retrieved 2009-11-11.
- ^ Pavlo, Andrew; Paulson, Erik; Rasin, Alexander; Abadi, Daniel J.; DeWitt, Deavid J.; Madden, Samuel; Stonebraker, Michael. «A Comparison of Approaches to Large-Scale Data Analysis». Brown University. Retrieved 2010-01-11.
- ^ Hillis, W. Danny (1986). The Connection Machine. MIT Press. ISBN 0262081571.
- ^ «Connection Machine Model CM-2 Technical Summary» (PDF). Thinking Machines Corporation. 1987-04-01. Retrieved 2022-11-21.
- ^ «Supplement to the *Lisp Reference Manual» (PDF). Thinking Machines Corporation. 1988-09-01. Retrieved 2022-11-21.
- ^ «Rediflow Architecture Prospectus» (PDF). University of Utah Department of Computer Science. 1986-04-05. Retrieved 2022-11-21.
- ^ Ranka, Sanjay (1989). «2.6 Data Sum». Hypercube Algorithms for Image Processing and Pattern Recognition (PDF). University of Florida. Retrieved 2022-12-08.
- ^ Paul, Ryan (20 January 2010). «Google’s MapReduce patent: what does it mean for Hadoop?». Ars Technica. Retrieved 21 March 2021.
- ^ «United States Patent: 7650331 — System and method for efficient large-scale data processing». uspto.gov.
- ^ Nazer, Daniel (28 March 2013). «Google Makes Open Patent Non-assertion Pledge and Proposes New Licensing Models». Electronic Frontier Foundation. Retrieved 21 March 2021.
- ^ King, Rachel (2013). «Google expands open patent pledge to 79 more about data center management». ZDNet. Retrieved 21 March 2021.
- ^ «System and method for efficient large-scale data processing». Google Patents Search. 18 June 2004. Retrieved 21 March 2021.
- ^ Gupta, Upa; Fegaras, Leonidas (2013-10-06). «Map-Based Graph Analysis on MapReduce» (PDF). Proceedings: 2013 IEEE International Conference on Big Data. 2013 IEEE International Conference on Big Data. Santa Clara, California: IEEE. pp. 24–30.
- ^ Zaharia, Matei; Chowdhury, Mosharaf; Franklin, Michael; Shenker, Scott; Stoica, Ion (June 2010). Spark: Cluster Computing with Working Sets (PDF). HotCloud 2010.
![]()
Wikimedia Commons has media related to MapReduce.
MapReduce is a programming model and an associated implementation for processing and generating big data sets with a parallel, distributed algorithm on a cluster.[1][2][3]
A MapReduce program is composed of a map procedure, which performs filtering and sorting (such as sorting students by first name into queues, one queue for each name), and a reduce method, which performs a summary operation (such as counting the number of students in each queue, yielding name frequencies). The «MapReduce System» (also called «infrastructure» or «framework») orchestrates the processing by marshalling the distributed servers, running the various tasks in parallel, managing all communications and data transfers between the various parts of the system, and providing for redundancy and fault tolerance.
The model is a specialization of the split-apply-combine strategy for data analysis.[4]
It is inspired by the map and reduce functions commonly used in functional programming,[5] although their purpose in the MapReduce framework is not the same as in their original forms.[6] The key contributions of the MapReduce framework are not the actual map and reduce functions (which, for example, resemble the 1995 Message Passing Interface standard’s[7] reduce[8] and scatter[9] operations), but the scalability and fault-tolerance achieved for a variety of applications by optimizing the execution engine[citation needed]. As such, a single-threaded implementation of MapReduce is usually not faster than a traditional (non-MapReduce) implementation; any gains are usually only seen with multi-threaded implementations on multi-processor hardware.[10] The use of this model is beneficial only when the optimized distributed shuffle operation (which reduces network communication cost) and fault tolerance features of the MapReduce framework come into play. Optimizing the communication cost is essential to a good MapReduce algorithm.[11]
MapReduce libraries have been written in many programming languages, with different levels of optimization. A popular open-source implementation that has support for distributed shuffles is part of Apache Hadoop. The name MapReduce originally referred to the proprietary Google technology, but has since been genericized. By 2014, Google was no longer using MapReduce as their primary big data processing model,[12] and development on Apache Mahout had moved on to more capable and less disk-oriented mechanisms that incorporated full map and reduce capabilities.[13]
OverviewEdit
MapReduce is a framework for processing parallelizable problems across large datasets using a large number of computers (nodes), collectively referred to as a cluster (if all nodes are on the same local network and use similar hardware) or a grid (if the nodes are shared across geographically and administratively distributed systems, and use more heterogeneous hardware). Processing can occur on data stored either in a filesystem (unstructured) or in a database (structured). MapReduce can take advantage of the locality of data, processing it near the place it is stored in order to minimize communication overhead.
A MapReduce framework (or system) is usually composed of three operations (or steps):
- Map: each worker node applies the
mapfunction to the local data, and writes the output to a temporary storage. A master node ensures that only one copy of the redundant input data is processed. - Shuffle: worker nodes redistribute data based on the output keys (produced by the
mapfunction), such that all data belonging to one key is located on the same worker node. - Reduce: worker nodes now process each group of output data, per key, in parallel.
MapReduce allows for the distributed processing of the map and reduction operations. Maps can be performed in parallel, provided that each mapping operation is independent of the others; in practice, this is limited by the number of independent data sources and/or the number of CPUs near each source. Similarly, a set of ‘reducers’ can perform the reduction phase, provided that all outputs of the map operation that share the same key are presented to the same reducer at the same time, or that the reduction function is associative. While this process often appears inefficient compared to algorithms that are more sequential (because multiple instances of the reduction process must be run), MapReduce can be applied to significantly larger datasets than a single «commodity» server can handle – a large server farm can use MapReduce to sort a petabyte of data in only a few hours.[14] The parallelism also offers some possibility of recovering from partial failure of servers or storage during the operation: if one mapper or reducer fails, the work can be rescheduled – assuming the input data are still available.
Another way to look at MapReduce is as a 5-step parallel and distributed computation:
- Prepare the Map() input – the «MapReduce system» designates Map processors, assigns the input key K1 that each processor would work on, and provides that processor with all the input data associated with that key.
- Run the user-provided Map() code – Map() is run exactly once for each K1 key, generating output organized by key K2.
- «Shuffle» the Map output to the Reduce processors – the MapReduce system designates Reduce processors, assigns the K2 key each processor should work on, and provides that processor with all the Map-generated data associated with that key.
- Run the user-provided Reduce() code – Reduce() is run exactly once for each K2 key produced by the Map step.
- Produce the final output – the MapReduce system collects all the Reduce output, and sorts it by K2 to produce the final outcome.
These five steps can be logically thought of as running in sequence – each step starts only after the previous step is completed – although in practice they can be interleaved as long as the final result is not affected.
In many situations, the input data might have already been distributed («sharded») among many different servers, in which case step 1 could sometimes be greatly simplified by assigning Map servers that would process the locally present input data. Similarly, step 3 could sometimes be sped up by assigning Reduce processors that are as close as possible to the Map-generated data they need to process.
Logical viewEdit
The Map and Reduce functions of MapReduce are both defined with respect to data structured in (key, value) pairs. Map takes one pair of data with a type in one data domain, and returns a list of pairs in a different domain:
Map(k1,v1) → list(k2,v2)
The Map function is applied in parallel to every pair (keyed by k1) in the input dataset. This produces a list of pairs (keyed by k2) for each call.
After that, the MapReduce framework collects all pairs with the same key (k2) from all lists and groups them together, creating one group for each key.
The Reduce function is then applied in parallel to each group, which in turn produces a collection of values in the same domain:
Reduce(k2, list (v2)) → list((k3, v3))[15]
Each Reduce call typically produces either one key value pair or an empty return, though one call is allowed to return more than one key value pair. The returns of all calls are collected as the desired result list.
Thus the MapReduce framework transforms a list of (key, value) pairs into another list of (key, value) pairs.[16] This behavior is different from the typical functional programming map and reduce combination, which accepts a list of arbitrary values and returns one single value that combines all the values returned by map.
It is necessary but not sufficient to have implementations of the map and reduce abstractions in order to implement MapReduce. Distributed implementations of MapReduce require a means of connecting the processes performing the Map and Reduce phases. This may be a distributed file system. Other options are possible, such as direct streaming from mappers to reducers, or for the mapping processors to serve up their results to reducers that query them.
ExamplesEdit
The canonical MapReduce example counts the appearance of each word in a set of documents:[17]
function map(String name, String document):
// name: document name
// document: document contents
for each word w in document:
emit (w, 1)
function reduce(String word, Iterator partialCounts):
// word: a word
// partialCounts: a list of aggregated partial counts
sum = 0
for each pc in partialCounts:
sum += pc
emit (word, sum)
Here, each document is split into words, and each word is counted by the map function, using the word as the result key. The framework puts together all the pairs with the same key and feeds them to the same call to reduce. Thus, this function just needs to sum all of its input values to find the total appearances of that word.
As another example, imagine that for a database of 1.1 billion people, one would like to compute the average number of social contacts a person has according to age. In SQL, such a query could be expressed as:
SELECT age, AVG(contacts) FROM social.person GROUP BY age ORDER BY age
Using MapReduce, the K1 key values could be the integers 1 through 1100, each representing a batch of 1 million records, the K2 key value could be a person’s age in years, and this computation could be achieved using the following functions:
function Map is
input: integer K1 between 1 and 1100, representing a batch of 1 million social.person records
for each social.person record in the K1 batch do
let Y be the person's age
let N be the number of contacts the person has
produce one output record (Y,(N,1))
repeat
end function
function Reduce is
input: age (in years) Y
for each input record (Y,(N,C)) do
Accumulate in S the sum of N*C
Accumulate in Cnew the sum of C
repeat
let A be S/Cnew
produce one output record (Y,(A,Cnew))
end function
Note that in the Reduce function, C is the count of people having in total N contacts, so in the Map function it is natural to write C=1, since every output pair is referring to the contacts of one single person.
The MapReduce system would line up the 1100 Map processors, and would provide each with its corresponding 1 million input records. The Map step would produce 1.1 billion (Y,(N,1)) records, with Y values ranging between, say, 8 and 103. The MapReduce System would then line up the 96 Reduce processors by performing shuffling operation of the key/value pairs due to the fact that we need average per age, and provide each with its millions of corresponding input records. The Reduce step would result in the much reduced set of only 96 output records (Y,A), which would be put in the final result file, sorted by Y.
The count info in the record is important if the processing is reduced more than one time. If we did not add the count of the records, the computed average would be wrong, for example:
-- map output #1: age, quantity of contacts 10, 9 10, 9 10, 9
-- map output #2: age, quantity of contacts 10, 9 10, 9
-- map output #3: age, quantity of contacts 10, 10
If we reduce files #1 and #2, we will have a new file with an average of 9 contacts for a 10-year-old person ((9+9+9+9+9)/5):
-- reduce step #1: age, average of contacts 10, 9
If we reduce it with file #3, we lose the count of how many records we’ve already seen, so we end up with an average of 9.5 contacts for a 10-year-old person ((9+10)/2), which is wrong. The correct answer is 9.166 = 55 / 6 = (9×3+9×2+10×1)/(3+2+1).
DataflowEdit
Software framework architecture adheres to open-closed principle where code is effectively divided into unmodifiable frozen spots and extensible hot spots. The frozen spot of the MapReduce framework is a large distributed sort. The hot spots, which the application defines, are:
- an input reader
- a Map function
- a partition function
- a compare function
- a Reduce function
- an output writer
Input readerEdit
The input reader divides the input into appropriate size ‘splits’ (in practice, typically, 64 MB to 128 MB) and the framework assigns one split to each Map function. The input reader reads data from stable storage (typically, a distributed file system) and generates key/value pairs.
A common example will read a directory full of text files and return each line as a record.
Map functionEdit
The Map function takes a series of key/value pairs, processes each, and generates zero or more output key/value pairs. The input and output types of the map can be (and often are) different from each other.
If the application is doing a word count, the map function would break the line into words and output a key/value pair for each word. Each output pair would contain the word as the key and the number of instances of that word in the line as the value.
Partition functionEdit
Each Map function output is allocated to a particular reducer by the application’s partition function for sharding purposes. The partition function is given the key and the number of reducers and returns the index of the desired reducer.
A typical default is to hash the key and use the hash value modulo the number of reducers. It is important to pick a partition function that gives an approximately uniform distribution of data per shard for load-balancing purposes, otherwise the MapReduce operation can be held up waiting for slow reducers to finish
(i.e. the reducers assigned the larger shares of the non-uniformly partitioned data).
Between the map and reduce stages, the data are shuffled (parallel-sorted / exchanged between nodes) in order to move the data from the map node that produced them to the shard in which they will be reduced. The shuffle can sometimes take longer than the computation time depending on network bandwidth, CPU speeds, data produced and time taken by map and reduce computations.
Comparison functionEdit
The input for each Reduce is pulled from the machine where the Map ran and sorted using the application’s comparison function.
Reduce functionEdit
The framework calls the application’s Reduce function once for each unique key in the sorted order. The Reduce can iterate through the values that are associated with that key and produce zero or more outputs.
In the word count example, the Reduce function takes the input values, sums them and generates a single output of the word and the final sum.
Output writerEdit
The Output Writer writes the output of the Reduce to the stable storage.
Theoretical backgroundEdit
Properties of Monoid are the basis for ensuring the validity of Map/Reduce operations.[18][19]
In Algebird package[20] a Scala implementation of Map/Reduce explicitly requires Monoid class type
.[21]
The operations of MapReduce deal with two types: the type A of input data being mapped, and the type B of output data being reduced.
Map operation takes individual values of type A and produces, for each a:A a value b:B; Reduce operation requires a binary operation • defined on values of type B; it consists of folding all available b:B to a single value.
From basic requirements point of view, any MapReduce operation must involve the ability to arbitrarily regroup data being reduced. Such a requirement amounts to two properties of operation •:
- associativity: (x • y) • z = x • (y • z)
- existence of neutral element e such that e • x = x • e = x for every x:B.
The second property guarantees that, when parallelized over multiple nodes, the nodes that don’t have any data to process would have no impact on the result.
These two properties amount to having a Monoid (B, •, e) on values of type B with operation • and with neutral element e.
There’s no requirements on the values of type A; an arbitrary function A → B can be used for Map operation. This means that we have a Catamorphism A* → (B, •, e). Here A* denotes a Kleene star, also known as the type of lists over A.
Shuffle operation per se is not related to the essence of MapReduce; it’s needed to distribute calculations over the cloud.
It follows from the above that not every binary Reduce operation will work in MapReduce. Here are the counter-examples:
- building a tree from subtrees: this operation is not associative, and the result will depend on grouping;
- direct calculation of averages: avg is also not associative (and it has no neutral element); to calculate an average, one needs to calculate moments.
Performance considerationsEdit
MapReduce programs are not guaranteed to be fast. The main benefit of this programming model is to exploit the optimized shuffle operation of the platform, and only having to write the Map and Reduce parts of the program.
In practice, the author of a MapReduce program however has to take the shuffle step into consideration; in particular the partition function and the amount of data written by the Map function can have a large impact on the performance and scalability. Additional modules such as the Combiner function can help to reduce the amount of data written to disk, and transmitted over the network. MapReduce applications can achieve sub-linear speedups under specific circumstances.[22]
When designing a MapReduce algorithm, the author needs to choose a good tradeoff[11] between the computation and the communication costs. Communication cost often dominates the computation cost,[11][22] and many MapReduce implementations are designed to write all communication to distributed storage for crash recovery.
In tuning performance of MapReduce, the complexity of mapping, shuffle, sorting (grouping by the key), and reducing has to be taken into account. The amount of data produced by the mappers is a key parameter that shifts the bulk of the computation cost between mapping and reducing. Reducing includes sorting (grouping of the keys) which has nonlinear complexity. Hence, small partition sizes reduce sorting time, but there is a trade-off because having a large number of reducers may be impractical. The influence of split unit size is marginal (unless chosen particularly badly, say <1MB). The gains from some mappers reading load from local disks, on average, is minor.[23]
For processes that complete quickly, and where the data fits into main memory of a single machine or a small cluster, using a MapReduce framework usually is not effective. Since these frameworks are designed to recover from the loss of whole nodes during the computation, they write interim results to distributed storage. This crash recovery is expensive, and only pays off when the computation involves many computers and a long runtime of the computation. A task that completes in seconds can just be restarted in the case of an error, and the likelihood of at least one machine failing grows quickly with the cluster size. On such problems, implementations keeping all data in memory and simply restarting a computation on node failures or —when the data is small enough— non-distributed solutions will often be faster than a MapReduce system.
Distribution and reliabilityEdit
MapReduce achieves reliability by parceling out a number of operations on the set of data to each node in the network. Each node is expected to report back periodically with completed work and status updates. If a node falls silent for longer than that interval, the master node (similar to the master server in the Google File System) records the node as dead and sends out the node’s assigned work to other nodes. Individual operations use atomic operations for naming file outputs as a check to ensure that there are not parallel conflicting threads running. When files are renamed, it is possible to also copy them to another name in addition to the name of the task (allowing for side-effects).
The reduce operations operate much the same way. Because of their inferior properties with regard to parallel operations, the master node attempts to schedule reduce operations on the same node, or in the same rack as the node holding the data being operated on. This property is desirable as it conserves bandwidth across the backbone network of the datacenter.
Implementations are not necessarily highly reliable. For example, in older versions of Hadoop the NameNode was a single point of failure for the distributed filesystem. Later versions of Hadoop have high availability with an active/passive failover for the «NameNode.»
UsesEdit
MapReduce is useful in a wide range of applications, including distributed pattern-based searching, distributed sorting, web link-graph reversal, Singular Value Decomposition,[24] web access log stats, inverted index construction, document clustering, machine learning,[25] and statistical machine translation. Moreover, the MapReduce model has been adapted to several computing environments like multi-core and many-core systems,[26][27][28] desktop grids,[29]
multi-cluster,[30] volunteer computing environments,[31] dynamic cloud environments,[32] mobile environments,[33] and high-performance computing environments.[34]
At Google, MapReduce was used to completely regenerate Google’s index of the World Wide Web. It replaced the old ad hoc programs that updated the index and ran the various analyses.[35] Development at Google has since moved on to technologies such as Percolator, FlumeJava[36] and MillWheel that offer streaming operation and updates instead of batch processing, to allow integrating «live» search results without rebuilding the complete index.[37]
MapReduce’s stable inputs and outputs are usually stored in a distributed file system. The transient data are usually stored on local disk and fetched remotely by the reducers.
CriticismEdit
Lack of noveltyEdit
David DeWitt and Michael Stonebraker, computer scientists specializing in parallel databases and shared-nothing architectures, have been critical of the breadth of problems that MapReduce can be used for.[38] They called its interface too low-level and questioned whether it really represents the paradigm shift its proponents have claimed it is.[39] They challenged the MapReduce proponents’ claims of novelty, citing Teradata as an example of prior art that has existed for over two decades. They also compared MapReduce programmers to CODASYL programmers, noting both are «writing in a low-level language performing low-level record manipulation.»[39] MapReduce’s use of input files and lack of schema support prevents the performance improvements enabled by common database system features such as B-trees and hash partitioning, though projects such as Pig (or PigLatin), Sawzall, Apache Hive,[40] HBase[41] and Bigtable[41][42] are addressing some of these problems.
Greg Jorgensen wrote an article rejecting these views.[43] Jorgensen asserts that DeWitt and Stonebraker’s entire analysis is groundless as MapReduce was never designed nor intended to be used as a database.
DeWitt and Stonebraker have subsequently published a detailed benchmark study in 2009 comparing performance of Hadoop’s MapReduce and RDBMS approaches on several specific problems.[44] They concluded that relational databases offer real advantages for many kinds of data use, especially on complex processing or where the data is used across an enterprise, but that MapReduce may be easier for users to adopt for simple or one-time processing tasks.
The MapReduce programming paradigm was also described in Danny Hillis’s 1985 thesis [45] intended for use on the Connection Machine, where it was called «xapping/reduction»[46] and relied upon that machine’s special hardware to accelerate both map and reduce. The dialect ultimately used for the Connection Machine, the 1986 StarLisp, had parallel *map and reduce!!,[47] which in turn was based on the 1984 Common Lisp, which had non-parallel map and reduce built in.[48] The tree-like approach that the Connection Machine’s hypercube architecture uses to execute reduce in time[49] is effectively the same as the approach referred to within the Google paper as prior work.[3]: 11
In 2010 Google was granted what is described as a patent on MapReduce. The patent, filed in 2004, may cover use of MapReduce by open source software such as Hadoop, CouchDB, and others. In Ars Technica, an editor acknowledged Google’s role in popularizing the MapReduce concept, but questioned whether the patent was valid or novel.[50][51] In 2013, as part of its «Open Patent Non-Assertion (OPN) Pledge», Google pledged to only use the patent defensively.[52][53] The patent is expected to expire on 23 December 2026.[54]
Restricted programming frameworkEdit
MapReduce tasks must be written as acyclic dataflow programs, i.e. a stateless mapper followed by a stateless reducer, that are executed by a batch job scheduler. This paradigm makes repeated querying of datasets difficult and imposes limitations that are felt in fields such as graph processing[55] where iterative algorithms that revisit a single working set multiple times are the norm, as well as, in the presence of disk-based data with high latency, even the field of machine learning where multiple passes through the data are required even though algorithms can tolerate serial access to the data each pass.[56]
See alsoEdit
- Bird–Meertens formalism
Implementations of MapReduceEdit
- Apache CouchDB
- Apache Hadoop
- Infinispan
- Riak
ReferencesEdit
- ^ «MapReduce Tutorial». Apache Hadoop. Retrieved 3 July 2019.
- ^ «Google spotlights data center inner workings». cnet.com. 30 May 2008. Archived from the original on 19 October 2013. Retrieved 31 May 2008.
- ^ a b «MapReduce: Simplified Data Processing on Large Clusters» (PDF). googleusercontent.com.
- ^ Wickham, Hadley (2011). «The split-apply-combine strategy for data analysis». Journal of Statistical Software. 40: 1–29. doi:10.18637/jss.v040.i01.
- ^ «Our abstraction is inspired by the map and reduce primitives present in Lisp and many other functional languages.» -«MapReduce: Simplified Data Processing on Large Clusters», by Jeffrey Dean and Sanjay Ghemawat; from Google Research
- ^ Lämmel, R. (2008). «Google’s Map Reduce programming model — Revisited». Science of Computer Programming. 70: 1–30. doi:10.1016/j.scico.2007.07.001.
- ^ http://www.mcs.anl.gov/research/projects/mpi/mpi-standard/mpi-report-2.0/mpi2-report.htm MPI 2 standard
- ^ «MPI Reduce and Allreduce · MPI Tutorial». mpitutorial.com.
- ^ «Performing Parallel Rank with MPI · MPI Tutorial». mpitutorial.com.
- ^ «MongoDB: Terrible MapReduce Performance». Stack Overflow. October 16, 2010.
The MapReduce implementation in MongoDB has little to do with map reduce apparently. Because for all I read, it is single-threaded, while map-reduce is meant to be used highly parallel on a cluster. … MongoDB MapReduce is single threaded on a single server…
- ^ a b c Ullman, J. D. (2012). «Designing good MapReduce algorithms». XRDS: Crossroads, the ACM Magazine for Students. 19: 30–34. doi:10.1145/2331042.2331053. S2CID 26498063.
- ^ Sverdlik, Yevgeniy (2014-06-25). «Google Dumps MapReduce in Favor of New Hyper-Scale Analytics System». Data Center Knowledge. Retrieved 2015-10-25.
«We don’t really use MapReduce anymore» [Urs Hölzle, senior vice president of technical infrastructure at Google]
- ^ Harris, Derrick (2014-03-27). «Apache Mahout, Hadoop’s original machine learning project, is moving on from MapReduce». Gigaom. Retrieved 2015-09-24.
Apache Mahout […] is joining the exodus away from MapReduce.
- ^ Czajkowski, Grzegorz; Marián Dvorský; Jerry Zhao; Michael Conley (7 September 2011). «Sorting Petabytes with MapReduce – The Next Episode». Retrieved 7 April 2014.
- ^ «MapReduce Tutorial».
- ^ «Apache/Hadoop-mapreduce». GitHub. 31 August 2021.
- ^ «Example: Count word occurrences». Google Research. Retrieved September 18, 2013.
- ^ Fegaras, Leonidas (2017). «An algebra for distributed Big Data analytics». Journal of Functional Programming. 28. doi:10.1017/S0956796817000193. S2CID 44629767.
- ^ Lin, Jimmy (29 Apr 2013). «Monoidify! Monoids as a Design Principle for Efficient MapReduce Algorithms». arXiv:1304.7544 [cs.DC].
- ^ «Abstract Algebra for Scala».
- ^ «Encoding Map-Reduce As A Monoid With Left Folding». 5 September 2016.
- ^ a b Senger, Hermes; Gil-Costa, Veronica; Arantes, Luciana; Marcondes, Cesar A. C.; Marín, Mauricio; Sato, Liria M.; da Silva, Fabrício A.B. (2015-01-01). «BSP cost and scalability analysis for MapReduce operations». Concurrency and Computation: Practice and Experience. 28 (8): 2503–2527. doi:10.1002/cpe.3628. hdl:10533/147670. ISSN 1532-0634. S2CID 33645927.
- ^ Berlińska, Joanna; Drozdowski, Maciej (2010-12-01). «Scheduling divisible MapReduce computations». Journal of Parallel and Distributed Computing. 71 (3): 450–459. doi:10.1016/j.jpdc.2010.12.004.
- ^ Bosagh Zadeh, Reza; Carlsson, Gunnar (2013). «Dimension Independent Matrix Square Using MapReduce» (PDF). Stanford University. arXiv:1304.1467. Bibcode:2013arXiv1304.1467B. Retrieved 12 July 2014.
- ^ Ng, Andrew Y.; Bradski, Gary; Chu, Cheng-Tao; Olukotun, Kunle; Kim, Sang Kyun; Lin, Yi-An; Yu, YuanYuan (2006). «Map-Reduce for Machine Learning on Multicore». NIPS 2006.
- ^ Ranger, C.; Raghuraman, R.; Penmetsa, A.; Bradski, G.; Kozyrakis, C. (2007). «Evaluating MapReduce for Multi-core and Multiprocessor Systems». 2007 IEEE 13th International Symposium on High Performance Computer Architecture. p. 13. CiteSeerX 10.1.1.220.8210. doi:10.1109/HPCA.2007.346181. ISBN 978-1-4244-0804-7. S2CID 12563671.
- ^ He, B.; Fang, W.; Luo, Q.; Govindaraju, N. K.; Wang, T. (2008). «Mars: a MapReduce framework on graphics processors» (PDF). Proceedings of the 17th international conference on Parallel architectures and compilation techniques – PACT ’08. p. 260. doi:10.1145/1454115.1454152. ISBN 9781605582825. S2CID 207169888.
- ^ Chen, R.; Chen, H.; Zang, B. (2010). «Tiled-MapReduce: optimizing resource usages of data-parallel applications on multicore with tiling». Proceedings of the 19th international conference on Parallel architectures and compilation techniques – PACT ’10. p. 523. doi:10.1145/1854273.1854337. ISBN 9781450301787. S2CID 2082196.
- ^ Tang, B.; Moca, M.; Chevalier, S.; He, H.; Fedak, G. (2010). «Towards MapReduce for Desktop Grid Computing» (PDF). 2010 International Conference on P2P, Parallel, Grid, Cloud and Internet Computing. p. 193. CiteSeerX 10.1.1.671.2763. doi:10.1109/3PGCIC.2010.33. ISBN 978-1-4244-8538-3. S2CID 15044391.
- ^ Luo, Y.; Guo, Z.; Sun, Y.; Plale, B.; Qiu, J.; Li, W. (2011). «A Hierarchical Framework for Cross-Domain MapReduce Execution» (PDF). Proceedings of the second international workshop on Emerging computational methods for the life sciences (ECMLS ’11). CiteSeerX 10.1.1.364.9898. doi:10.1145/1996023.1996026. ISBN 978-1-4503-0702-4. S2CID 15179363.
- ^ Lin, H.; Ma, X.; Archuleta, J.; Feng, W. C.; Gardner, M.; Zhang, Z. (2010). «MOON: MapReduce On Opportunistic eNvironments» (PDF). Proceedings of the 19th ACM International Symposium on High Performance Distributed Computing – HPDC ’10. p. 95. doi:10.1145/1851476.1851489. ISBN 9781605589428. S2CID 2351790.
- ^ Marozzo, F.; Talia, D.; Trunfio, P. (2012). «P2P-MapReduce: Parallel data processing in dynamic Cloud environments». Journal of Computer and System Sciences. 78 (5): 1382–1402. doi:10.1016/j.jcss.2011.12.021.
- ^ Dou, A.; Kalogeraki, V.; Gunopulos, D.; Mielikainen, T.; Tuulos, V. H. (2010). «Misco: a MapReduce framework for mobile systems». Proceedings of the 3rd International Conference on PErvasive Technologies Related to Assistive Environments – PETRA ’10. p. 1. doi:10.1145/1839294.1839332. ISBN 9781450300711. S2CID 14517696.
- ^ Wang, Yandong; Goldstone, Robin; Yu, Weikuan; Wang, Teng (May 2014). «Characterization and Optimization of Memory-Resident MapReduce on HPC Systems». 2014 IEEE 28th International Parallel and Distributed Processing Symposium. IEEE. pp. 799–808. doi:10.1109/IPDPS.2014.87. ISBN 978-1-4799-3800-1. S2CID 11157612.
- ^ «How Google Works». baselinemag.com. 7 July 2006.
As of October, Google was running about 3,000 computing jobs per day through MapReduce, representing thousands of machine-days, according to a presentation by Dean. Among other things, these batch routines analyze the latest Web pages and update Google’s indexes.
- ^ Chambers, Craig; Raniwala, Ashish; Perry, Frances; Adams, Stephen; Henry, Robert R.; Bradshaw, Robert; Weizenbaum, Nathan (1 January 2010). FlumeJava: Easy, Efficient Data-parallel Pipelines (PDF). Proceedings of the 31st ACM SIGPLAN Conference on Programming Language Design and Implementation. pp. 363–375. doi:10.1145/1806596.1806638. ISBN 9781450300193. S2CID 14888571. Archived from the original (PDF) on 23 September 2016. Retrieved 4 August 2016.
- ^ Peng, D., & Dabek, F. (2010, October). Large-scale Incremental Processing Using Distributed Transactions and Notifications. In OSDI (Vol. 10, pp. 1-15).
- ^ «Database Experts Jump the MapReduce Shark».
- ^ a b David DeWitt; Michael Stonebraker. «MapReduce: A major step backwards». craig-henderson.blogspot.com. Retrieved 2008-08-27.
- ^ «Apache Hive – Index of – Apache Software Foundation».
- ^ a b «HBase – HBase Home – Apache Software Foundation».
- ^ «Bigtable: A Distributed Storage System for Structured Data» (PDF).
- ^ Greg Jorgensen. «Relational Database Experts Jump The MapReduce Shark». typicalprogrammer.com. Retrieved 2009-11-11.
- ^ Pavlo, Andrew; Paulson, Erik; Rasin, Alexander; Abadi, Daniel J.; DeWitt, Deavid J.; Madden, Samuel; Stonebraker, Michael. «A Comparison of Approaches to Large-Scale Data Analysis». Brown University. Retrieved 2010-01-11.
- ^ Hillis, W. Danny (1986). The Connection Machine. MIT Press. ISBN 0262081571.
- ^ «Connection Machine Model CM-2 Technical Summary» (PDF). Thinking Machines Corporation. 1987-04-01. Retrieved 2022-11-21.
- ^ «Supplement to the *Lisp Reference Manual» (PDF). Thinking Machines Corporation. 1988-09-01. Retrieved 2022-11-21.
- ^ «Rediflow Architecture Prospectus» (PDF). University of Utah Department of Computer Science. 1986-04-05. Retrieved 2022-11-21.
- ^ Ranka, Sanjay (1989). «2.6 Data Sum». Hypercube Algorithms for Image Processing and Pattern Recognition (PDF). University of Florida. Retrieved 2022-12-08.
- ^ Paul, Ryan (20 January 2010). «Google’s MapReduce patent: what does it mean for Hadoop?». Ars Technica. Retrieved 21 March 2021.
- ^ «United States Patent: 7650331 — System and method for efficient large-scale data processing». uspto.gov.
- ^ Nazer, Daniel (28 March 2013). «Google Makes Open Patent Non-assertion Pledge and Proposes New Licensing Models». Electronic Frontier Foundation. Retrieved 21 March 2021.
- ^ King, Rachel (2013). «Google expands open patent pledge to 79 more about data center management». ZDNet. Retrieved 21 March 2021.
- ^ «System and method for efficient large-scale data processing». Google Patents Search. 18 June 2004. Retrieved 21 March 2021.
- ^ Gupta, Upa; Fegaras, Leonidas (2013-10-06). «Map-Based Graph Analysis on MapReduce» (PDF). Proceedings: 2013 IEEE International Conference on Big Data. 2013 IEEE International Conference on Big Data. Santa Clara, California: IEEE. pp. 24–30.
- ^ Zaharia, Matei; Chowdhury, Mosharaf; Franklin, Michael; Shenker, Scott; Stoica, Ion (June 2010). Spark: Cluster Computing with Working Sets (PDF). HotCloud 2010.
Wikimedia Commons has media related to MapReduce.
Hadoop — это наиболее распространенная система хранения файлов и распределенной обработки больших данных на рынке, которая разделена на два больших блока: hdfs и MapReduce, hdfs — это распределенная система хранения файлов, основанная на бумаге Google GFS. MapReduce распространяется Вычислительная вычислительная система, основанная на статье Google MapReduce. Эта статья посвящена комбинированию следующей версии Hadoop MapReduce после 2.3, которая представляет собой инфраструктуру Yarn, и подробной работе по восьми основным шагам MapReduce.
Введение и сравнение нового и старого MapReduce
Введение в старую версию MapReduce
Старая версия MapReduce разделена на две части: JobTracker и TaskTracker.
- JobTracker отвечает за получение запросов задач, отправленных клиентами, распределение системных ресурсов, назначение задач на TaskTracker, управление сбоями / перезапуском задач и другими операциями.
- TaskTracker отвечает за получение и выполнение задач, назначенных JobTracker, и поддерживает механизм пульса с JobTracker, и сообщает JobTracker о состоянии выполнения своих задач.
Есть проблемы со старой версией MapReduce
- Все задачи распределяются, планируются, отслеживаются и обрабатываются на JobTracker, что приводит к чрезмерному потреблению ресурсов. Когда появляется больше заданий, риск сбоя компьютера JobTracker возрастает.
- JobTracker — это централизованная точка обработки Map-Reduce, в которой есть единственная точка отказа.
- Со стороны TaskTracker, использование количества задач сопоставления / уменьшения, поскольку представление ресурса слишком простое, без учета загрузки процессора / памяти.Если две задачи с большим потреблением памяти запланированы вместе, вероятно, появится OOM.
- Со стороны TaskTracker ресурсы принудительно разделяются на слот задачи карты и уменьшают слот задачи.Если в системе есть только задача карты или только задача сокращения, это приведет к пустой трате ресурсов, что является упомянутой выше проблемой использования ресурсов кластера.
Введение в новую версию MapReduce
Новая версия MapReduce также называется фреймворком Yarn.
-
ResourceManager: планировщик ресурсов
Во-первых, поддержите механизм пульса с помощью NodeManager, примите запрос задачи клиента, запустите планирование задач в соответствии с условиями ресурса, о которых сообщает NodeManager, назначьте контейнер ApplicationMaster, контролируйте существование AppMaster, отвечайте за планирование работы и распределение ресурсов, ресурсы включают ЦП, память, диск Сеть и т. Д. Она не участвует в распределении и мониторинге конкретных задач, а также не может управлять сбоями и перезапускать конкретные задачи.
-
ApplicationMaster: диспетчер задач
На одной из машин Node он отвечает за весь жизненный цикл задания. Включая распределение задач и планирование, сбой задачи и управление перезапуском, вся работа по конкретным задачам полностью управляется ApplicationMaster, как большая экономка, только для ResourceManager Подать заявку на ресурсы, назначить задачи для NodeManager, контролировать выполнение задач, управлять сбоями и перезапускать задачи.
-
NodeManager: процессор задач
Отвечает за обработку задач, назначенных ApplicationMaster, и поддержку механизма пульса с помощью ResourceManager, мониторинг использования ресурсов и создание отчетов для отчетов RM, поддерживая распределение ресурсов RM.
Восемь подробных шагов работы MapReduce
MapReduce идеи
Одна из самых важных идей MapReduce: разделяй и властвуй. Она состоит в том, чтобы разделить главную задачу на несколько небольших задач и выполнять их параллельно. После завершения они объединяются вместе. Подходит для большого количества сложных сценариев обработки задач и крупномасштабных сценариев обработки данных.
Карта отвечает за «деление», то есть разбиение сложных задач на несколько «простых задач» для параллельной обработки. Предпосылка разделения заключается в том, что эти небольшие задачи могут быть рассчитаны параллельно, и между ними почти нет зависимости.
Реду отвечает за «комбинацию», которая заключается в глобальном обобщении результатов этапа карты.

Как видно из приведенного выше рисунка, после того, как клиент отправил вычислительное задание, он должен сначала прочитать этот файл. По умолчанию блок обрабатывается с помощью Maptask. После завершения обработки, на этапе Shuffle, после серии разделов, выполните сортировку. , Спецификация, группировка, введите сторону сокращения, после обработки стороны сокращения вывод может вывести результат обработки. Это общий рабочий процесс MapReduce.
Восемь шагов MapReduce:
Этап карты:
- Шаг 1: Считайте файл через FileInputFormat, разберите файл на пары ключ и значение и выведите на второй шаг.
- Шаг 2: Настройте логику карты, обработайте ключ 1, значение 1, преобразуйте его в ключ 2, значение 2 и выведите на третий шаг.
Перемешать этап:
- Шаг 3: Разделение ключа 2, значение 2.
- Шаг 4: Сортировка данных в разных разделах по одному и тому же ключу.
- Шаг 5: Выполните протокол (операция объединения) для сгруппированных данных, чтобы уменьшить сетевую копию данных (необязательный шаг)
- Шаг 6: Для отсортированных данных поместите данные значения того же ключа в набор как значение2.
Уменьшить этап:
- Шаг 7. Комбинируйте и сортируйте задачи нескольких карт, настраивайте логику сокращения, обрабатывайте ключ 2, значение 2, преобразуйте его в ключ 3, значение 3 и выводите его.
- Шаг 8: Вывести обработанные данные через FileOutputFormat и сохранить в файл.


Подробный рабочий механизм MapTask
Краткий обзор всего MapTask:
Сначала файл разделяется на несколько файлов разделения (фрагментов) с помощью логики разделения, и содержимое считывается LineReader из FileInputFormat (также может быть настроен) на карту для обработки. После завершения обработки карты данные передаются в сборщик OutputCollector. Ключ результата разбивается на разделы (по умолчанию используется раздел Hash), а затем записывается в буфер (буфер) памяти. Каждый MapTask имеет буфер памяти. Результаты обработки карты собираются. Буфер очень мал и его необходимо использовать повторно. Каждый раз, когда буфер работает быстро Когда они заполнены, временные файлы будут записаны на диск, отсортированы в буфере памяти, условные обозначения, после завершения всей задачи MapTask временные файлы на этих дисках будут объединены для создания окончательного выходного файла, ожидая, пока будет восстановлен ReduTask. ,
Подробные шаги:
-
Во-первых, компонент считанных данных InputFormat (по умолчанию TextInputFormat) будет использовать метод getSplits для логического планирования файлов во входном каталоге для получения разбиений. Число разделений соответствует количеству запущенных MapTasks. Соответствие между split и block является однозначным по умолчанию.
-
После того, как входной файл разделен на разбиения, он читается объектом RecordReader (по умолчанию LineRecordReader), используя n в качестве разделителя, читает строку данных и возвращает <ключ, значение>. Ключ представляет значение смещения первого символа каждой строки, а значение представляет текстовое содержимое этой строки.
-
Разделение чтения возвращает <ключ, значение>, входит в класс Mapper, унаследованный пользователем, и выполняет функцию карты, переписанную пользователем. RecordReader вызывается один раз для чтения строки.
-
После того, как логика карты завершена, соберите данные каждого результата карты через context.write. В методе collect он будет сначала разбит на разделы, а HashPartitioner используется по умолчанию
Роль разделения заключается в определении задачи сокращения, которая должна быть передана текущей паре выходных данных, на основе ключа или значения и числа сокращения. По умолчанию хэш ключа используется для модуляции количества задач сокращения. Режим по умолчанию по модулю — просто уменьшить вычислительную мощность редуктора.Если пользователю нужен сам разделитель, он может быть настроен и настроен на работу.
-
Затем данные будут записаны в память. Эта область в памяти называется кольцевым буфером. Роль этого буфера состоит в том, чтобы собирать результаты карт в пакетах и уменьшать влияние дискового ввода-вывода. Наши пары ключ / значение и результаты раздела будут записаны в буфер. Конечно, перед записью значения ключа и значения будут сериализованы в байтовый массив.
Кольцевой буфер на самом деле является массивом, и сериализованные данные ключа и значения и метаданные информации ключа и значения сохраняются в массиве, включая начальную позицию раздела, ключ, начальную позицию значения и длину значения. Кольцевая структура — это абстрактное понятие.
Размер буфера ограничен, по умолчанию 100 МБ. Когда выходной результат задачи карты много, он может заполнить память, поэтому при определенных условиях необходимо временно записать данные в буфере на диск, а затем повторно использовать буфер.
Этот процесс записи данных из памяти на диск называется Spill, что означает переполнение записи. Эта запись переполнения выполняется отдельным потоком и не влияет на поток, который записывает результат отображения в буфер. Таким образом, весь буфер имеет коэффициент переполнения записи, который по умолчанию равен 0,8, то есть когда данные буфера достигли порогового значения (размер буфера * процент разлива = 100 МБ * 0,8 = 80 МБ), поток записи переполнения запускается и блокирует 80 МБ. Память, выполните процесс переполнения записи. Выходной результат задачи «Карта» также можно записать в оставшуюся память объемом 20 МБ, не влияя друг на друга.
-
После запуска потока переполнения необходимо отсортировать ключи в 80 МБ пространства. Сортировка — это стандартное поведение модели MapReduce, а также сортировка сериализованных байтов. Если задание установило объединитель, то пришло время использовать объединитель. Добавьте значение пары ключ / значение с одним и тем же ключом, чтобы уменьшить объем данных, записываемых на диск. Комбинатор оптимизирует промежуточные результаты MapReduce, поэтому он будет использоваться несколько раз по всей модели.
Какие сценарии могут использовать Combiner? Из проведенного здесь анализа выходной сигнал объединителя является входом редуктора, и объединитель не должен изменять конечный результат расчета. Комбинатор следует использовать только в сценариях, в которых клавиша ввода / значение типа «Уменьшить» и «клавиша вывода / значение» в точности совпадает и не влияет на конечный результат. Например, накопление, максимальное значение и т. Д. Использование Combiner должно быть осмотрительным: при правильном использовании это поможет повысить эффективность выполнения задания, в противном случае это повлияет на конечный результат снижения.
-
Объединение файлов с переполненной записью: Ø Каждая запись с переполнением создает временный файл на диске (судя по тому, существует ли объединитель перед записью), если вывод карты действительно велик, существует много таких записей с переполнением, соответствующих на диске. Там будет несколько временных файлов. Когда вся обработка данных завершена, файлы слияния объединяются во временные файлы на диске, поскольку на диск записывается только один конечный файл, и для этого файла предоставляется индексный файл для записи смещения данных, соответствующих каждому уменьшению.
Подробный механизм работы ReduceTask
Краткий обзор: Сокращение грубо разделено на три этапа: копирование, сортировка и сокращение с акцентом на первые два этапа. ReduceTask запустит поток Fetcher для копирования своих собственных файлов. Сначала файлы помещаются в буфер памяти. Когда файлы из копии достигают определенного порога, файлы будут объединены на диск, а затем на диске будет сгенерировано много файлов перезаписи. Он не заканчивается до тех пор, пока на стороне карты не будет данных, а затем объединит файлы на диске для создания окончательного файла.
Подробные шаги:
- Скопируйте этап, просто потяните данные. Процесс Reduce запускает некоторые потоки копирования данных (Fetcher) и запрашивает maptask для получения своих собственных файлов через HTTP.
- Стадия слияния. Слияние здесь похоже на действие слияния в конце карты, но значения, хранящиеся в массиве, копируются с разных концов карты. Скопированные данные будут сначала помещены в буфер памяти, размер буфера здесь более гибкий, чем у конца карты. Существует три формы слияния: память в память, память на диск, диск на диск. Первая форма не включена по умолчанию. Когда объем данных в памяти достигает определенного порога, инициируется слияние памяти с диском. Аналогично стороне карты, это также процесс записи переполнения. В этом процессе, если вы настроите Combiner, он также будет включен, а затем на диске будет создано много файлов записи переполнения. Второй метод слияния работал до тех пор, пока конец карты недоступен, а затем запустите третий метод слияния диск-диск, чтобы сгенерировать окончательный файл.
- Сортировка слиянием После объединения разбросанных данных в одну большую, объединенные данные будут снова отсортированы.
- Вызовите метод Reduction для отсортированных пар ключ-значение и один раз вызовите метод Reduce для пар ключ-значение с равными ключами.Каждый вызов будет генерировать ноль или более пар ключ-значение и, наконец, записать эти выходные пары ключ-значение в файл HDFS. ,
MapReduce Shuffle процесс
Как перевести данные, обработанные в фазе карты, в фазу сокращения — самый важный процесс в среде MapReduce, который называется случайным.
shuffle: тасование и лицензирование (основной механизм: разделение данных, сортировка, группировка, сжатие, объединение и т. д.).
Shuffle — это ядро Mapreduce, которое распределяется по фазе карты и сокращает фазу Mapreduce. Вообще говоря, процесс от вывода Map до времени, когда Reduce получает данные в качестве входных данных, называется случайным.
- Этап сбора: вывод результатов MapTask в кольцевой буфер с размером по умолчанию 100M, в котором хранятся ключ / значение, информация о разделе и т. Д.
- Этап разлива: Когда объем данных в памяти достигает определенного порога, данные будут записаны на локальный диск. Перед записью данных на диск данные необходимо отсортировать один раз. Если объединитель настроен, он также будет Сортировка данных с одинаковым номером раздела и ключом.
- Этап объединения: объедините все переполненные временные файлы, чтобы MapTask генерировал только промежуточный файл данных.
- Этап копирования: ReduceTask запускает поток Fetcher для копирования копии своих собственных данных в узел, который завершил MapTask. Эти данные будут сохранены в буфере памяти по умолчанию. Когда буфер памяти достигнет определенного порога, он будет Данные записываются на диск.
- Этап объединения: в то время как ReduceTask выполняет удаленное копирование данных, в фоновом режиме запускаются два потока для объединения файлов данных из памяти в локальную.
- Этап сортировки: при объединении данных будет выполнена операция сортировки.Так как этап MapTask уже отсортировал данные локально, ReduceTask должен только обеспечить окончательную общую достоверность скопированных данных.
Размер буфера в Shuffle будет влиять на эффективность выполнения программы mapreduce.В принципе, чем больше буфер, тем меньше число дисков io и тем выше скорость выполнения. Размер буфера можно настроить по параметрам, параметры: mapreduce.task.io.sort.mb по умолчанию 100M.

Сегодня действительно печальный день, потому что Чжао Лиин и Фэн Шаофэн объявили о своем браке на Вэйбо, а моя другая богиня вышла замуж. Кажется, что это обычная проблема для мужчин. Смотреть на богиню всегда немного грустно, когда я женюсь … Но, давайте благословим … Зачем говорить другую богиню? Потому что моя последняя богиня — это Ишуань …
MapReduce – это модель распределённых вычислений от компании Google, используемая в технологиях Big Data для параллельных вычислений над очень большими (до нескольких петабайт) наборами данных в компьютерных кластерах, и фреймворк для вычисления распределенных задач на узлах (node) кластера [1].
Назначение и области применения
MapReduce можно по праву назвать главной технологией Big Data, т.к. она изначально ориентирована на параллельные вычисления в распределенных кластерах. Суть MapReduce состоит в разделении информационного массива на части, параллельной обработки каждой части на отдельном узле и финального объединения всех результатов.
Программы, использующие MapReduce, автоматически распараллеливаются и исполняются на распределенных узлах кластера, при этом исполнительная система сама заботится о деталях реализации (разбиение входных данных на части, разделение задач по узлам кластера, обработка сбоев и сообщение между распределенными компьютерами). Благодаря этому программисты могут легко и эффективно использовать ресурсы распределённых Big Data систем.
Технология практически универсальна: она может использоваться для индексации веб-контента, подсчета слов в большом файле, счётчиков частоты обращений к заданному адресу, вычисления объём всех веб-страниц с каждого URL-адреса конкретного хост-узла, создания списка всех адресов с необходимыми данными и прочих задач обработки огромных массивов распределенной информации. Также к областям применения MapReduce относится распределённый поиск и сортировка данных, обращение графа веб-ссылок, обработка статистики логов сети, построение инвертированных индексов, кластеризация документов, машинное обучение и статистический машинный перевод. Также MapReduce адаптирована под многопроцессорные системы, добровольные вычислительные, динамические облачные и мобильные среды [2].
История развития главной технологии Big Data
Авторами этой вычислительной модели считаются сотрудники Google Джеффри Дин (Jeffrey Dean) и Санджай Гемават (Sanjay Ghemawat), взявшие за основу две процедуры функционального программирования: map, применяющая нужную функцию к каждому элементу списка, и reduce, объединяющая результаты работы map [3]. В процессе вычисления множество входных пар ключ/значение преобразуется в множество выходных пар ключ/значение [4].
Изначально название MapReduce было запатентовано корпорацией Google, но по мере развития технологий Big Data стало общим понятием мира больших данных. Сегодня множество различных коммерческих, так и свободных продуктов, использующих эту модель распределенных вычислений: Apache Hadoop, Apache CouchDB, MongoDB, MySpace Qizmt и прочие Big Data фреймворки и библиотеки, написанные на разных языках программирования [2]. Среди других наиболее известных реализаций MapReduce стоит отметить следующие [5]:
- Greenplum — коммерческая реализация с поддержкой языков Python, Perl, SQL и пр.;
- GridGain — бесплатная реализация с открытым исходным кодом на языке Java;
- Phoenix — реализация на языке С с использованием разделяемой памяти;
- MapReduce реализована в графических процессорах NVIDIA с использованием CUDA;
- Qt Concurrent — упрощённая версия фреймворка, реализованная на C++, для распределения задачи между несколькими ядрами одного компьютера;
- CouchDB использует MapReduce для определения представлений поверх распределённых документов;
- Skynet — реализация с открытым исходным кодом на языке Ruby;
- Disco — реализация от компании Nokia, ядро которой написано на языке Erlang, а приложения можно разрабатывать на Python;
- Hive framework — надстройка с открытым исходным кодом от Facebook, позволяющая комбинировать подход MapReduce и доступ к данным на SQL-подобном языке;
- Qizmt — реализация с открытым исходным кодом от MySpace, написанная на C#;
- DryadLINQ — реализация от Microsoft Research на основе PLINQ и Dryad.

Прежде всего, еще раз поясним смысл основополагающих функций вычислительной модели [2]:
- mapпринимает на вход список значений и некую функцию, которую затем применяет к каждому элементу списка и возвращает новый список;
- reduce (свёртка) — преобразует список к единственному атомарному значению при помощи заданной функции, которой на каждой итерации передаются новый элемент списка и промежуточный результат.
Для обработки данных в соответствии с вычислительной моделью MapReduce следует определить обе эти функции, указать имена входных и выходных файлов, а также параметры обработки.
Сама вычислительная модель состоит из 3-хшаговой комбинации вышеприведенных функций [2]:
- Map – предварительная обработка входных данных в виде большого список значений. При этом главный узел кластера (master node) получает этот список, делит его на части и передает рабочим узлам (worker node). Далее каждый рабочий узел применяет функцию Map к локальным данным и записывает результат в формате «ключ-значение» во временное хранилище.
- Shuffle, когда рабочие узлы перераспределяют данные на основе ключей, ранее созданных функцией Map, таким образом, чтобы все данные одного ключа лежали на одном рабочем узле.
- Reduce – параллельная обработка каждым рабочим узлом каждой группы данных по порядку следования ключей и «склейка» результатов на master node. Главный узел получает промежуточные ответы от рабочих узлов и передаёт их на свободные узлы для выполнения следующего шага. Получившийся после прохождения всех необходимых шагов результат – это и есть решение исходной задачи.

О преимуществах и недостатках вычислительной модели MapReduce, а также возможных альтернативах читайте в нашей отдельной статье.
Источники
- https://ru.wikipedia.org/wiki/MapReduce
- https://ru.bmstu.wiki/MapReduce
- https://www.computerra.ru/183360/mapreduce/
- https://www.ibm.com/developerworks/ru/library/cl-mapreduce/index.html
- https://dic.academic.ru/dic.nsf/ruwiki/607046