
Мета-теги — это необязательные атрибуты, размещенные в заголовке страницы, между тегами <head> и </head>, которые никак не отображаются браузером (за исключением содержимого тега <title>). Мета-теги могут содержать описание html-страницы, ключевые слова к ней, информацию об авторе, управляющие команды для браузера и поисковых роботов, а также прочую служебную информацию, не предназначенную для посетителей. Мета-теги для сайта играют очень важную роль. Их добавление в html-документ могут существенно помочь сайту в его жизни.
Всегда применяйте только те мета-теги, которые реально нужны для работы веб-сайта. Не следует загромождать область <head> лишними инструкциями, т.к. любая ошибка здесь может привести к печальным последствиям.
Функции мета-тегов
На данный момент не существует их четкой стандартизации, однако функции мета-тегов достаточно разнообразны. Можно выделить несколько основных направлений использования мета-тегов:
- мета-теги могут идентифицировать авторство веб-документа, его адрес, частоту его обновлений;
- мета-теги используются поисковыми роботами для индексации и создания заголовков гипертекстовых документов;
- мета-теги влияют на режим отображения веб-страниц.
Группы метатегов
Мета-теги можно разделить на две основные группы — это NAME и HTTP-EQUIV. Группа NAME отвечает за текстовую информацию о веб-документе, его авторе, а также — формирует рекомендации для поисковых роботов. Мета-теги, относящиеся к группе HTTP-EQUIV фактически эквивалентны гипертекстовым заголовкам, они формируют заголовок веб-страницы и определяют его обработку, а также управляют действиями браузеров и используются для формирования информации, выдаваемой обычными заголовками.
Элемент meta принимает следующие атрибуты: content, http-equiv, name, charset и scheme.
| Атрибут | Описание |
|---|---|
| Name | Имя метатега, также косвенно устанавливает его предназначение. Примеры: include, keywords, description, author, revised, generator и др. |
| content | Устанавливает значение атрибута, заданного с помощью name или http-equiv. |
| scheme (устарел) | Указывает полезную информацию о схеме или название самой схемы, которая должна быть использована для интерпретации значения свойства (то есть значения атрибута «content»). Не применяется в HTML5. |
| charset | Новый атрибут, показывает кодировку документа в HTML5. Пример: <meta charset=»utf-8″> |
| http-equiv | Формирует заголовок страницы и определяет его обработку. Как правило, управляет действиями браузеров и используется для формирования информации, выдаваемой обычными заголовками. Например HTTP-EQUIV может использоваться для управления кэшированием, обновлением страницы, автоматической загрузки другой страницы. |
Группа значений атрибута NAME
«keywords» (ключевые слова)
Keywords поисковые системы используют для того, чтобы определить релевантность страницы тому или иному запросу. При формировании данного значения необходимо использовать только те слова, которые обязательно встречаются в самом документе. Использование тех слов, которых нет на странице, не рекомендуется. Ключевые слова нужно добавлять по одному, через запятую, в единственном числе. Рекомендованное количество слов в «keywords» — не более десяти. Кроме того, выявлено, что разбивка этого значения на несколько строк влияет на оценку ссылки поисковыми машинами. Некоторые поисковые системы не индексируют сайты, в которых в значении «keywords» повторяется одно и то же слово для увеличения позиции в списке результатов.
Если раньше «keywords» имел определённую роль в ранжировании сайта, то в последнее время поисковые системы относятся к нему нейтрально.
HTML-код с «keywords»:
<!DOCTYPE html>
<html>
<head>
<title>keywords</title>
<meta name="keywords" content="HTML,CSS,PHP,JavaScript">
</head>
<body>Основное содержимое страницы</body>
</html>«description» (описание страницы)
Description используется при создании краткого описания конкретной страницы Вашего сайта. Практически все поисковые системы учитывают его при индексации, а также при создании аннотации в выдаче по запросу. При отсутствии «description» поисковые системы выдают в аннотации первую строку документа или отрывок, содержащий ключевые слова. Отображается после ссылки при поиске страниц в поисковике, поэтому желательно не просто указывать краткое описание документа, но сделать его содержание привлекательным рекламным сообщением.
Таким образом, правильный description обязательно должен содержать ключевое слово, коротко и точно описывать то, о чём данная веб-страница. «Description» вместе с «title» образуют очень важную пару значений, от которых зависит то, перейдёт пользователь из поисковой выдачи на веб-страницу или нет! Поэтому «description» и «title» нужно прописывать для каждой веб-страницы!
HTML-код с «description»:
<!DOCTYPE html>
<html>
<head>
<title>description</title>
<meta name="description" content="Сайт об HTML и CSS">
<meta name="keywords" content="HTML,CSS,PHP,JavaScript">
</head>
<body>Основное содержимое страницы</body>
</html>«Author» и «Copyright»
Эти значения, как правило, не используются одновременно. Функция author и copyright — идентификация автора или принадлежности контента на странице. «Author» содержит имя автора веб-страницы, но в случае, если веб-сайт принадлежит какой-либо организации, целесообразнее использовать значение «Copyright».
HTML-код с «author»:
<!DOCTYPE html>
<html>
<head>
<title>Примеры применения метатегов</title>
<meta name="author" content="Maxim White">
<meta name="keywords" content="HTML, Meta Tags, Metadata">
<meta name="description" content="Сайт об HTML и CSS">
</head>
<body>Основное содержимое страницы</body>
</html>«Robots»
Robots — формирует информацию о гипертекстовых документах, которая поступает к роботам поисковых систем.
У «robots» могут быть следующие значения:
- index — страница должна быть проиндексирована;
- noindex — страница не индексируется;
- follow — гиперссылки на странице учитываются;
- nofollow — гиперссылки на странице не учитываются
- all — включает значения index и follow, включен по умолчанию;
- none — включает значения noindex и nofollow.
HTML-код с «robots»:
<!DOCTYPE html>
<html>
<head>
<title>Примеры применения метатегов</title>
<meta name="robots" content="noindex, nofollow">
<meta name="keywords" content="HTML, Meta Tags, Metadata">
<meta name="author" content="Maxim White">
<meta name="description" content="Сайт об HTML и CSS">
</head>
<body>Основное содержимое страницы</body>
</html>Группа значений атрибута HTTP-EQUIV
«Content-Type»
Content-Type определяет тип документа и его кодировку.
HTML-код с «Content-Type»:
<!DOCTYPE html>
<html>
<head>
<title>Примеры применения метатегов</title>
<meta name="keywords" content="HTML, Meta Tags, Metadata">
<meta name="description" content="Сайт об HTML и CSS">
<meta name="author" content="Maxim White">
<meta name="robots" content="noindex, nofollow">
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
</head>
<body>Основное содержимое страницы</body>
</html>В HTML5 указание кодировки упрощено:
<meta charset="UTF-8">«refresh»
Refresh — задержка времени (в секундах) перед тем, как браузер обновит страницу. Кроме того, может использоваться автоматическая загрузка другой html-страницы с заданным адресом (url).
HTML-код с «refresh»:
<!DOCTYPE html>
<html>
<head>
<title>Автозагрузка</title>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<meta http-equiv="refresh" content="5; URL=http://www.wm-school.ru">
</head>
<body>Основное содержимое страницы</body>
</html>Браузер поймет эту запись, как через 5 секунд загрузить новую страницу, указанную в параметре URL, в данном случае это переход на сайт wm-school.ru.
Значение «refresh» позволяет создавать перенаправление (редирект) на другой сайт. Если URL не указан, произойдет автоматическое обновление текущей страницы через количество секунд, заданных в атрибуте content.
| Обратите внимание, что кавычки в указании URL-адреса перед http не ставятся. |
«Content-Language»
Content-Language указывает язык документа. Может использоваться поисковыми машинами при индексировании страниц. Комбинация поля Accept-Language (посылаемого браузером) с содержимым Content-language может быть условием выбора сервером того или иного языка.
HTML-код с «content-language»:
<!DOCTYPE html>
<html>
<head>
<title>Язык документа</title>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<meta http-equiv="refresh" content="5; URL=http://www.wm-school.ru">
<meta http-equiv="content-language" content="ru">
</head>
<body>Основное содержимое страницы</body>
</html>В HTML5 указание языка упрощено:
<html lang="ru">В этом уроке перечислены не все метатеги, которые вы можете встретить при изучении веб-ремесла. Остальные специфичны и вы познакомитесь с ними в дальнейшем при изучении наших уроков. Из всех же вышеперечисленных к использованию на каждой странице вашего сайта рекомендуются метатеги и их атрибуты приведенные в следующем примере:
Пример HTML:
Попробуй сам
<!DOCTYPE html>
<html>
<head>
<title>Заголовок страницы</title>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<meta name="keywords" content="HTML, Meta Tags, метаданные">
<meta name="description" content="Сайт об HTML и CSS">
</head>
<body>Основное содержимое страницы</body>
</html>Задачи
Итоговое задание [10-14]
На этом уроке вы познакомились с наиболее важными метатегами основным предназначением которых является предоставление структурированных метаданных о веб-странице.
Пришло время повторить изученное и выполнить четыре несложных задания:
Ключевые слова
- Задание
- Ответ
- Реши сам »
С помощью одинарного тега <meta> задайте ключевые слова: «HTML,CSS,JavaScript» для текущей веб-страницы.
<!DOCTYPE html>
<html>
<head>
<meta>
<title>Ключевые слова</title>
</head>
<body>
<p>Метатеги (англ. meta tags) — предназначены для предоставления структурированных метаданных о веб-странице.</p>
</body>
</html>Индексация веб-страницы
- Задание
- Ответ
- Реши сам »
С помощью одинарного тега <meta> разрешите индексацию Web-страницы поисковыми машинами, а переход по ссылкам запретите.
<!DOCTYPE html>
<html>
<head>
<meta>
<title>Индексация и переход по ссылкам</title>
</head>
<body>
<p>Тег meta позволяет запретить или разрешить индексацию Web-страницы поисковыми машинами.</p>
</body>
</html>Автоматическая перезагрузка страницы
- Задание
- Ответ
- Реши сам »
С помощью одинарного тега meta назначте автоматическую перезагрузку текущей веб-страницы через 30 сек.
<!DOCTYPE html>
<html>
<head>
<meta>
<title>Автоматическая перезагрузка страницы</title>
</head>
<body>
<p>Тег meta позволяет автоматически перезагружать страницу через заданный промежуток времени.</p>
</body>
</html>Автозагрузка новой страницы
- Задание
- Ответ
- Реши сам »
Сделайте так, чтобы через 5 сек после загрузки страницы браузер перешел на адрес http://www.wm-school.ru.
<!DOCTYPE html>
<html>
<head>
<meta>
<title>Автозагрузка новой страницы</title>
</head>
<body>
<p>В данном случае через 5 сек после загрузки страницы браузер перейдет на адрес http://www.wm-school.ru.</p>
</body>
</html>Материал взят с разрешения админа здесь
Мета-инструкции
Заголовок
HTML-документа может включать неограниченное
количество META-инструкций.
META-инструкция
— это способ определить некоторую
переменную путем указания ее имени
(атрибут NAME)
и значения (атрибут CONTENT).
Список
META-инструкций
<META
NAME=»description» CONTENT=»Это руководство»>
Переменная
description
содержит краткое описание документа.
<META
NAME=»keywords»
CONTENT=»Интернет,
HTML,
WWW,
руководство, публикация, гипертекст»>
Переменная keywords
содержит набор ключевых слов, описывающих
содержание документа.
Другая группа
META-инструкций определяет эквиваленты
команд протокола передачи гипертекстов.
<META
HTTP-EQUIV=»Content-type» CONTENT=»text/html;
charset=windows-1251″>
Эта META-инструкция
дает браузеру указание интерпретировать
загружаемый документ как содержащий
HTML-текст в кодировке Windows/1251.
<META
HTTP-EQUIV=»Content-type» CONTENT=»text/html;
charset=koi8-r»>
Эта META-инструкция
абсолютно аналогична предыдущей, только
в качестве кодировки указана КОИ-8.
<META
HTTP-EQUIV=»Refresh» CONTENT=»время;
URL=документ»>
Такая META-инструкция
дает браузеру примерно такое указание:
«Если через время
в секундах после завершения загрузки
этого документа пользователь не перейдет
к другому документу, начать загрузку
ресурса документ«.
Более конкретно
это может выглядеть, к примеру, вот так:
<META
HTTP-EQUIV=»Refresh» CONTENT=»10;
URL=http://www.yi.com»>
Если пользователь
не предпримет никаких видимых действий
в течение 10 секунд после загрузки
документа, содержащего такую инструкцию,
автоматически будет загружен документ
http://www.yi.com.
Пример 8
В отличие от всех
примеров, которые мы рассматривали
ранее, пример 8 состоит из трех файлов.
Используя
META-инструкцию Refresh,
создадим небольшой слайд-фильм из трех
кадров (файлов 1.html,
1a.html
и 1b.html),
которые будут циклически повторяться.
Для остановки демонстрации нужно будет
воспользоваться любой из гипертекстовых
ссылок.
<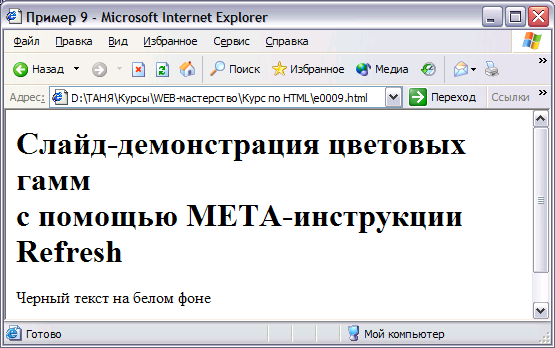 !—файл
!—файл
1.html
—>
<HTML>
<HEAD>
<TITLE>Пример
8</TITLE>
<META
HTTP-EQUIV=»Refresh» CONTENT=»2; URL=1a.html»>
</HEAD>
<BODY
bgcolor=#FFFFFF text=#000000 link=#FF0000>
<H1>Слайд-демонстрация
цветовых гамм <BR> с помощью
META-инструкции Refresh </H1>
<P>Черный
текст на белом фоне </P>
<P>[<A
HREF=»index.html»>Возврат
</A>|
<A
HREF=»2.html»>Возврат
к
2</A>]</P>
</BODY>
</HTML><!—конец
файла
1.html —>
<!—файл
1a.html —>
<HTML>
<HEAD>
<TITLE>Пример
8a</TITLE>
<META
HTTP-EQUIV=»Refresh» CONTENT=»2; URL=1b.html»>
</HEAD>
<BODY
bgcolor=#000000 text=#FFFFFF link=#FF0000>
<H1>Слайд-демонстрация
цветовых гамм <BR> с помощью
META-инструкции Refresh </H1>
<P>Белый
текст на черном фоне </P>
<P>[<A
HREF=»index.html»>Возврат</A>|
<A
HREF=»2.html»>Возврат
к
2</A>]</P>
</BODY>
</HTML><!—конец
файла
1a.html —>
<!—файл
1b.html
—>
<HTML>
<HEAD>
<TITLE>Пример
8b</TITLE>
<META
HTTP-EQUIV=»Refresh» CONTENT=»2; URL=1.html»>
</HEAD>
<BODY
bgcolor=#C0C0C0 text=#0000FF link=#FF0000>
<H1>Слайд-демонстрация
цветовых гамм <BR> с помощью
META-инструкции Refresh </H1>
<P>Синий
текст на сером фоне </P>
<P>[<A
HREF=»index.html»>Возврат</A>|
<A
HREF=»2.html»>Возврат
к
2</A>]</P>
</BODY>
</HTML><!—конец
файла
1b.html —>
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
![]()
A vocabulary and associated APIs for HTML and XHTML
W3C Recommendation 28 October 2014
4.2 Document metadata
4.2.1 The head element
- Categories:
- None.
- Contexts in which this element can be used:
- As the first element in an
htmlelement. - Content model:
- If the document is an
iframesrcdocdocument or if title information is available from a higher-level protocol: Zero or more elements of metadata content, of which no more than one is atitleelement and no more than one is abaseelement. - Otherwise: One or more elements of metadata content, of which exactly one is a
titleelement and no more than one is abaseelement. - Content attributes:
- Global attributes
- Tag omission in text/html:
- A
headelement’s start tag may be omitted if
the element is empty, or if the first thing inside theheadelement is an element. - A
headelement’s end tag may be omitted if the
headelement is not immediately followed by a space character or a comment. - Allowed ARIA role attribute values:
- none
- Allowed ARIA state and property attributes:
- Global aria-* attributes
- DOM interface:
-
interface HTMLHeadElement : HTMLElement {};
The head element represents a collection of metadata for the
Document.
The collection of metadata in a head element can be large or small. Here is an
example of a very short one:
<!doctype html> <html> <head> <title>A document with a short head</title> </head> <body> ...
Here is an example of a longer one:
<!DOCTYPE HTML> <HTML> <HEAD> <META CHARSET="UTF-8"> <BASE HREF="http://www.example.com/"> <TITLE>An application with a long head</TITLE> <LINK REL="STYLESHEET" HREF="default.css"> <LINK REL="STYLESHEET ALTERNATE" HREF="big.css" TITLE="Big Text"> <SCRIPT SRC="support.js"></SCRIPT> <META NAME="APPLICATION-NAME" CONTENT="Long headed application"> </HEAD> <BODY> ...
The title element is a required child in most situations, but when a
higher-level protocol provides title information, e.g. in the Subject line of an e-mail when HTML
is used as an e-mail authoring format, the title element can be omitted.
4.2.2 The title element
- Categories:
- Metadata content.
- Contexts in which this element can be used:
- In a
headelement containing no othertitleelements. - Content model:
- Text that is not inter-element whitespace.
- Content attributes:
- Global attributes
- Tag omission in text/html:
- Neither tag is omissible.
- Allowed ARIA role attribute values:
- none
- Allowed ARIA state and property attributes:
- Global aria-* attributes
- DOM interface:
-
interface HTMLTitleElement : HTMLElement { attribute DOMString text; };
The title element represents the document’s title or name. Authors
should use titles that identify their documents even when they are used out of context, for
example in a user’s history or bookmarks, or in search results. The document’s title is often
different from its first heading, since the first heading does not have to stand alone when taken
out of context.
There must be no more than one title element per document.
If it’s reasonable for the Document to have no title, then the
title element is probably not required. See the head element’s content
model for a description of when the element is required.
- title .
text[ = value ] -
Returns the contents of the element, ignoring child nodes that aren’t
Text
nodes.Can be set, to replace the element’s children with the given value.
The IDL attribute text must return a
concatenation of the contents of all the Text nodes that are children of the
title element (ignoring any other nodes such as comments or elements), in tree order.
On setting, it must act the same way as the textContent IDL attribute.
Here are some examples of appropriate titles, contrasted with the top-level headings that
might be used on those same pages.
<title>Introduction to The Mating Rituals of Bees</title>
...
<h1>Introduction</h1>
<p>This companion guide to the highly successful
<cite>Introduction to Medieval Bee-Keeping</cite> book is...
The next page might be a part of the same site. Note how the title describes the subject
matter unambiguously, while the first heading assumes the reader knows what the context is and
therefore won’t wonder if the dances are Salsa or Waltz:
<title>Dances used during bee mating rituals</title>
...
<h1>The Dances</h1>
The string to use as the document’s title is given by the document.title IDL attribute.
User agents should use the document’s title when referring to the document in their user
interface. When the contents of a title element are used in this way, the
directionality of that title element should be used to set the directionality
of the document’s title in the user interface.
4.2.3 The base element
- Categories:
- Metadata content.
- Contexts in which this element can be used:
- In a
headelement containing no otherbaseelements. - Content model:
- Empty.
- Content attributes:
- Global attributes
href— Document base URLtarget— Default browsing context for hyperlink navigation and form submission- Tag omission in text/html:
- No end tag.
- Allowed ARIA role attribute values:
- none
- Allowed ARIA state and property attributes:
- Global aria-* attributes.
- DOM interface:
-
interface HTMLBaseElement : HTMLElement { attribute DOMString href; attribute DOMString target; };
The base element allows authors to specify the document base URL for
the purposes of resolving relative URLs, and the name of the
default browsing context for the purposes of following hyperlinks. The
element does not represent any content beyond this
information.
There must be no more than one base element per document.
A base element must have either an href
attribute, a target attribute, or both.
The href content attribute, if specified, must
contain a valid URL potentially surrounded by spaces.
A base element, if it has an href attribute,
must come before any other elements in the tree that have attributes defined as taking URLs, except the html element (its manifest attribute isn’t affected by base
elements).
If there are multiple base elements with href attributes, all but the first are ignored.
The target attribute, if specified, must
contain a valid browsing context name or keyword, which specifies which
browsing context is to be used as the default when hyperlinks and forms in the
Document cause navigation.
A base element, if it has a target
attribute, must come before any elements in the tree that represent hyperlinks.
If there are multiple base elements with target attributes, all but the first are ignored.
A base element that is the first base element with an href content attribute in a particular Document has a
frozen base URL. The frozen base URL must be set, synchronously, whenever any of the following situations occur:
- The
baseelement becomes the firstbaseelement in tree
order with anhrefcontent attribute in its
Document. - The
baseelement is the firstbaseelement in tree
order with anhrefcontent attribute in its
Document, and itshrefcontent attribute is
changed.
To set the frozen base URL, resolve
the value of the element’s href content attribute relative to
the Document‘s fallback base URL; if this is successful, set the
frozen base URL to the resulting absolute URL, otherwise, set the
frozen base URL to the fallback base URL.
The href IDL attribute, on getting, must return
the result of running the following algorithm:
-
If the
baseelement has nohrefcontent
attribute, then return the document base URL and abort these steps. -
Let fallback base url be the
Document‘s fallback
base URL. -
Let url be the value of the
href
attribute of thebaseelement. -
Resolve url relative to fallback base url (thus, the
basehrefattribute isn’t affected byxml:baseattributes orbaseelements). -
If the previous step was successful, return the resulting absolute URL and
abort these steps. -
Otherwise, return the empty string.
The href IDL attribute, on setting, must set the href content attribute to the given new value.
The target IDL attribute must
reflect the content attribute of the same name.
In this example, a base element is used to set the document base
URL:
<!DOCTYPE html>
<html>
<head>
<title>This is an example for the <base> element</title>
<base href="http://www.example.com/news/index.html">
</head>
<body>
<p>Visit the <a href="archives.html">archives</a>.</p>
</body>
</html>
The link in the above example would be a link to «http://www.example.com/news/archives.html«.
4.2.4 The link element
- Categories:
- Metadata content.
- Contexts in which this element can be used:
- Where metadata content is expected.
- In a
noscriptelement that is a child of aheadelement. - Content model:
- Empty.
- Content attributes:
- Global attributes
href— Address of the hyperlinkcrossorigin— How the element handles crossorigin requestsrel— Relationship between the document containing the hyperlink and the destination resourcemedia— Applicable mediahreflang— Language of the linked resourcetype— Hint for the type of the referenced resourcesizes— Sizes of the icons (forrel=»icon«)- Also, the
titleattribute has special semantics on this element: Title of the link; alternative style sheet set name. - Tag omission in text/html:
- No end tag.
- Allowed ARIA role attribute values:
link(default — do not set).- Allowed ARIA state and property attributes:
- Global aria-* attributes
- Any
aria-*attributes applicable to the allowed roles. - For
rolevalue - DOM interface:
-
interface HTMLLinkElement : HTMLElement { attribute boolean disabled; attribute DOMString href; attribute DOMString crossOrigin; attribute DOMString rel; attribute DOMString rev; readonly attribute DOMTokenList relList; attribute DOMString media; attribute DOMString hreflang; attribute DOMString type; [PutForwards=value] readonly attribute DOMSettableTokenList sizes; }; HTMLLinkElement implements LinkStyle;
The link element allows authors to link their document to other resources.
The destination of the link(s) is given by the href attribute, which must be present and must contain a
valid non-empty URL potentially surrounded by spaces. If the href attribute is absent, then the element does not define a
link.
A link element must have a rel attribute.
If the rel attribute is used, the element is
restricted to the head element.
The types of link indicated (the relationships) are given by the value of the rel attribute, which, if present, must have a value that
is a set of space-separated tokens. The allowed keywords and
their meanings are defined in a later section. If the rel attribute is absent, has no keywords, or if none of the keywords
used are allowed according to the definitions in this specification, then the element does not
create any links.
Two categories of links can be created using the link element: Links to external resources and hyperlinks. The link types section defines
whether a particular link type is an external resource or a hyperlink. One link
element can create multiple links (of which some might be external resource links and some might
be hyperlinks); exactly which and how many links are created depends on the keywords given in the
rel attribute. User agents must process the links on a per-link
basis, not a per-element basis.
Each link created for a link element is handled separately. For
instance, if there are two link elements with rel="stylesheet",
they each count as a separate external resource, and each is affected by its own attributes
independently. Similarly, if a single link element has a rel attribute with the value next stylesheet,
it creates both a hyperlink (for the next keyword) and
an external resource link (for the stylesheet
keyword), and they are affected by other attributes (such as media or title)
differently.
For example, the following link element creates two hyperlinks (to the same
page):
<link rel="author license" href="/about">
The two links created by this element are one whose semantic is that the target page has
information about the current page’s author, and one whose semantic is that the target page has
information regarding the license under which the current page is provided.
The crossorigin attribute is a CORS
settings attribute. It is intended for use with external resource links.
The exact behavior for links to external resources depends on the exact relationship, as
defined for the relevant link type. Some of the attributes control whether or not the external
resource is to be applied (as defined below).
For external resources that are represented in the DOM (for example, style sheets), the DOM
representation must be made available (modulo cross-origin restrictions) even if the resource is
not applied. To obtain the resource, the user agent must
run the following steps:
-
If the
hrefattribute’s value is the empty string,
then abort these steps. -
Resolve the URL given by the
hrefattribute, relative to the element. -
If the previous step fails, then abort these steps.
-
Do a potentially CORS-enabled fetch of the resulting absolute
URL, with the mode being the current state of the element’scrossorigincontent attribute, the origin
being the origin of thelinkelement’sDocument, and the
default origin behaviour set to taint.The resource obtained in this fashion can be either CORS-same-origin or
CORS-cross-origin.
User agents may opt to only try to obtain such resources when they are needed, instead of
pro-actively fetching all the external resources that are not
applied.
The semantics of the protocol used (e.g. HTTP) must be followed when fetching external
resources. (For example, redirects will be followed and 404 responses will cause the external
resource to not be applied.)
Once the attempts to obtain the resource and its critical subresources are
complete, the user agent must, if the loads were successful, queue a task to
fire a simple event named load at the
link element, or, if the resource or one of its critical subresources
failed to completely load for any reason (e.g. DNS error, HTTP 404 response, a connection being
prematurely closed, unsupported Content-Type), queue a task to fire a simple
event named error at the link element.
Non-network errors in processing the resource or its subresources (e.g. CSS parse errors, PNG
decoding errors) are not failures for the purposes of this paragraph.
The task source for these tasks is the DOM
manipulation task source.
The element must delay the load event of the element’s document until all the
attempts to obtain the resource and its critical subresources are complete.
(Resources that the user agent has not yet attempted to obtain, e.g. because it is waiting for the
resource to be needed, do not delay the load event.)
Interactive user agents may provide users with a means to follow the hyperlinks created using the link element, somewhere
within their user interface. The exact interface is not defined by this specification, but it
could include the following information (obtained from the element’s attributes, again as defined
below), in some form or another (possibly simplified), for each hyperlink created with each
link element in the document:
- The relationship between this document and the resource (given by the
relattribute) - The title of the resource (given by the
title
attribute). - The address of the resource (given by the
href
attribute). - The language of the resource (given by the
hreflang
attribute). - The optimum media for the resource (given by the
media
attribute).
User agents could also include other information, such as the type of the resource (as given by
the type attribute).
Hyperlinks created with the link element and its rel attribute apply to the whole page. This contrasts with the rel attribute of a and area elements,
which indicates the type of a link whose context is given by the link’s location within the
document.
The media attribute says which media the
resource applies to. The value must be a valid media query.
If the link is a hyperlink then the media
attribute is purely advisory, and describes for which media the document in question was
designed.
However, if the link is an external resource link, then the media attribute is prescriptive. The user agent must apply the
external resource when the media attribute’s value
matches the environment and the other relevant conditions apply, and must not apply
it otherwise.
The external resource might have further restrictions defined within that limit
its applicability. For example, a CSS style sheet might have some @media
blocks. This specification does not override such further restrictions or requirements.
The default, if the media attribute is
omitted, is «all«, meaning that by default links apply to all media.
The hreflang attribute on the
link element has the same semantics as the hreflang attribute on a and
area elements.
The type attribute gives the MIME
type of the linked resource. It is purely advisory. The value must be a valid MIME
type.
For external resource links, the type attribute is used as a hint to user agents so that they can
avoid fetching resources they do not support. If the attribute is present, then
the user agent must assume that the resource is of the given type (even if that is not a
valid MIME type, e.g. the empty string). If the attribute is omitted, but the
external resource link type has a default type defined, then the user agent must assume that the
resource is of that type. If the UA does not support the given MIME type for the
given link relationship, then the UA should not obtain
the resource; if the UA does support the given MIME type for the given link
relationship, then the UA should obtain the resource at
the appropriate time as specified for the external resource link’s particular type.
If the attribute is omitted, and the external resource link type does not have a default type
defined, but the user agent would obtain the resource if
the type was known and supported, then the user agent should obtain the resource under the assumption that it will be
supported.
User agents must not consider the type attribute
authoritative — upon fetching the resource, user agents must not use the type attribute to determine its actual type. Only the actual type
(as defined in the next paragraph) is used to determine whether to apply the resource,
not the aforementioned assumed type.
If the external resource link type defines rules for processing
the resource’s Content-Type metadata, then those rules apply.
Otherwise, if the resource is expected to be an image, user agents may apply the image sniffing rules, with the official
type being the type determined from the resource’s Content-Type
metadata, and use the resulting sniffed type of the resource as if it was the actual type.
Otherwise, if neither of these conditions apply or if the user agent opts not to apply the image
sniffing rules, then the user agent must use the resource’s Content-Type metadata to determine the type of the resource. If there
is no type metadata, but the external resource link type has a default type defined, then the user
agent must assume that the resource is of that type.
The stylesheet link type defines rules for
processing the resource’s Content-Type metadata.
Once the user agent has established the type of the resource, the user agent must apply the
resource if it is of a supported type and the other relevant conditions apply, and must ignore the
resource otherwise.
If a document contains style sheet links labeled as follows:
<link rel="stylesheet" href="A" type="text/plain"> <link rel="stylesheet" href="B" type="text/css"> <link rel="stylesheet" href="C">
…then a compliant UA that supported only CSS style sheets would fetch the B and C files, and
skip the A file (since text/plain is not the MIME type for CSS style
sheets).
For files B and C, it would then check the actual types returned by the server. For those that
are sent as text/css, it would apply the styles, but for those labeled as
text/plain, or any other type, it would not.
If one of the two files was returned without a Content-Type metadata, or with a
syntactically incorrect type like Content-Type: "null", then the
default type for stylesheet links would kick in. Since that
default type is text/css, the style sheet would nonetheless be
applied.
The title attribute gives the title of the
link. With one exception, it is purely advisory. The value is text. The exception is for style
sheet links, where the title attribute defines
alternative style sheet sets.
The title attribute on link
elements differs from the global title attribute of most other
elements in that a link without a title does not inherit the title of the parent element: it
merely has no title.
The sizes attribute is used with the icon link type. The attribute must not be specified on link
elements that do not have a rel attribute that specifies the
icon keyword.
The activation behavior of link elements that create hyperlinks is to run the following steps:
-
If the
linkelement’sDocumentis not fully active,
then abort these steps. -
Follow the hyperlink created by the
linkelement.
HTTP Link: headers, if supported, must be assumed to come before
any links in the document, in the order that they were given in the HTTP message. These headers
are to be processed according to the rules given in the relevant specifications. [HTTP] [WEBLINK]
Registration of relation types in HTTP Link: headers is distinct from HTML link types, and thus their semantics can be different from same-named
HTML types.
The IDL attributes href, rel, rev, media,
hreflang, type, and sizes each must reflect the respective
content attributes of the same name.
The crossOrigin IDL attribute must
reflect the crossorigin content attribute,
limited to only known values.
The IDL attribute relList must reflect the rel content attribute.
The IDL attribute disabled only applies to
style sheet links. When the link element defines a style sheet link, then the disabled attribute behaves as defined for the alternative style sheets DOM. For all other
link elements it always return false and does nothing on setting.
The LinkStyle interface is also implemented by this element; the styling
processing model defines how. [CSSOM]
Here, a set of link elements provide some style sheets:
<!-- a persistent style sheet --> <link rel="stylesheet" href="default.css"> <!-- the preferred alternate style sheet --> <link rel="stylesheet" href="green.css" title="Green styles"> <!-- some alternate style sheets --> <link rel="alternate stylesheet" href="contrast.css" title="High contrast"> <link rel="alternate stylesheet" href="big.css" title="Big fonts"> <link rel="alternate stylesheet" href="wide.css" title="Wide screen">
The following example shows how you can specify versions of the page that use alternative
formats, are aimed at other languages, and that are intended for other media:
<link rel=alternate href="/en/html" hreflang=en type=text/html title="English HTML"> <link rel=alternate href="/fr/html" hreflang=fr type=text/html title="French HTML"> <link rel=alternate href="/en/html/print" hreflang=en type=text/html media=print title="English HTML (for printing)"> <link rel=alternate href="/fr/html/print" hreflang=fr type=text/html media=print title="French HTML (for printing)"> <link rel=alternate href="/en/pdf" hreflang=en type=application/pdf title="English PDF"> <link rel=alternate href="/fr/pdf" hreflang=fr type=application/pdf title="French PDF">
4.2.5 The meta element
- Categories:
- Metadata content.
- Contexts in which this element can be used:
- If the
charsetattribute is present, or if the element’shttp-equivattribute is in the encoding declaration state: in aheadelement. - If the
http-equivattribute is present but not in the encoding declaration state: in aheadelement. - If the
http-equivattribute is present but not in the encoding declaration state: in anoscriptelement that is a child of aheadelement. - If the
nameattribute is present: where metadata content is expected. - Content model:
- Empty.
- Content attributes:
- Global attributes
name— Metadata namehttp-equiv— Pragma directivecontent— Value of the elementcharset— Character encoding declaration- Tag omission in text/html:
- No end tag.
- Allowed ARIA role attribute values:
- none
- Allowed ARIA state and property attributes:
- Global aria-* attributes
- DOM interface:
-
interface HTMLMetaElement : HTMLElement { attribute DOMString name; attribute DOMString httpEquiv; attribute DOMString content; };
The meta element represents various kinds of metadata that cannot be
expressed using the title, base, link, style,
and script elements.
The meta element can represent document-level metadata with the name attribute, pragma directives with the http-equiv attribute, and the file’s character encoding
declaration when an HTML document is serialized to string form (e.g. for transmission over
the network or for disk storage) with the charset
attribute.
Exactly one of the name, http-equiv, and charset,
attributes must be specified.
If either name or http-equiv is
specified, then the content attribute must also be
specified. Otherwise, it must be omitted.
The charset attribute specifies the character
encoding used by the document. This is a character encoding declaration. If the
attribute is present in an XML document, its value must be an
ASCII case-insensitive match for the string «UTF-8» (and the
document is therefore forced to use UTF-8 as its encoding).
The charset attribute on the
meta element has no effect in XML documents, and is only allowed in order to
facilitate migration to and from XHTML.
There must not be more than one meta element with a charset attribute per document.
The content attribute gives the value of the
document metadata or pragma directive when the element is used for those purposes. The allowed
values depend on the exact context, as described in subsequent sections of this specification.
If a meta element has a name
attribute, it sets document metadata. Document metadata is expressed in terms of name-value pairs,
the name attribute on the meta element giving the
name, and the content attribute on the same element giving
the value. The name specifies what aspect of metadata is being set; valid names and the meaning of
their values are described in the following sections. If a meta element has no content attribute, then the value part of the metadata name-value
pair is the empty string.
The name and content IDL attributes must reflect the
respective content attributes of the same name. The IDL attribute httpEquiv must reflect the content
attribute http-equiv.
4.2.5.1 Standard metadata names
This specification defines a few names for the name
attribute of the meta element.
Names are case-insensitive, and must be compared in an ASCII
case-insensitive manner.
application-name-
The value must be a short free-form string giving the name of the Web application that the
page represents. If the page is not a Web application, theapplication-namemetadata name must not be used.
Translations of the Web application’s name may be given, using theattribute to specify the language of each name.There must not be more than one
metaelement with a given language
and with itsnameattribute set to the valueapplication-nameper document.User agents may use the application name in UI in preference to the page’s
title, since the title might include status messages and the like relevant to the
status of the page at a particular moment in time instead of just being the name of the
application.To find the application name to use given an ordered list of languages (e.g. British English,
American English, and English), user agents must run the following steps:-
Let languages be the list of languages.
-
Let default language be the language of the
Document‘s root element,
if any, and if that language is not unknown. -
If there is a default language, and if it is not the same language
as any of the languages is languages, append it to languages. -
Let winning language be the first language in languages for which there is a
metaelement in the
Documentthat has itsnameattribute set to
the valueapplication-nameand whose
language is the language in question.If none of the languages have such a
metaelement, then abort these steps;
there’s no given application name. -
Return the value of the
contentattribute of the
firstmetaelement in theDocumentin tree order that
has itsnameattribute set to the valueapplication-nameand whose language is winning language.
-
-
The value must be a free-form string giving the name of one of the page’s
authors. description-
The value must be a free-form string that describes the page. The value must be
appropriate for use in a directory of pages, e.g. in a search engine. There must not be more than
onemetaelement with itsnameattribute set to
the valuedescriptionper document. generator-
The value must be a free-form string that identifies one of the software packages used to
generate the document. This value must not be used on pages whose markup is not generated by
software, e.g. pages whose markup was written by a user in a text editor.Here is what a tool called «Frontweaver» could include in its output, in the page’s
headelement, to identify itself as the tool used to generate the page:<meta name=generator content="Frontweaver 8.2">
keywords-
The value must be a set of comma-separated tokens, each of which is a keyword
relevant to the page.This page about typefaces on British motorways uses a
metaelement to specify
some keywords that users might use to look for the page:<!DOCTYPE HTML> <html> <head> <title>Typefaces on UK motorways</title> <meta name="keywords" content="british,type face,font,fonts,highway,highways"> </head> <body> ...
Many search engines do not consider such keywords, because this feature has
historically been used unreliably and even misleadingly as a way to spam search engine results
in a way that is not helpful for users.To obtain the list of keywords that the author has specified as applicable to the page, the
user agent must run the following steps:-
Let keywords be an empty list.
-
For each
metaelement with aname
attribute and acontentattribute and whosenameattribute’s value iskeywords, run the following substeps:-
Split the value of the element’s
contentattribute on commas. -
Add the resulting tokens, if any, to keywords.
-
-
Remove any duplicates from keywords.
-
Return keywords. This is the list of keywords that the author has
specified as applicable to the page.
User agents should not use this information when there is insufficient confidence in the
reliability of the value.For instance, it would be reasonable for a content management system to use
the keyword information of pages within the system to populate the index of a site-specific
search engine, but a large-scale content aggregator that used this information would likely find
that certain users would try to game its ranking mechanism through the use of inappropriate
keywords. -
4.2.5.2 Other metadata names
Extensions to the predefined set of metadata names
may be registered in the WHATWG Wiki
MetaExtensions page. [WHATWGWIKI]
Anyone is free to edit the WHATWG Wiki MetaExtensions page at any time to add a type. These new
names must be specified with the following information:
- Keyword
-
The actual name being defined. The name should not be confusingly similar to any other
defined name (e.g. differing only in case). - Brief description
-
A short non-normative description of what the metadata name’s meaning is, including the
format the value is required to be in. - Specification
- A link to a more detailed description of the metadata name’s semantics and requirements. It
could be another page on the Wiki, or a link to an external page. - Synonyms
-
A list of other names that have exactly the same processing requirements. Authors should
not use the names defined to be synonyms, they are only intended to allow user agents to support
legacy content. Anyone may remove synonyms that are not used in practice; only names that need to
be processed as synonyms for compatibility with legacy content are to be registered in this
way. - Status
-
One of the following:
- Proposed
- The name has not received wide peer review and approval. Someone has proposed it and is, or
soon will be, using it. - Ratified
- The name has received wide peer review and approval. It has a specification that
unambiguously defines how to handle pages that use the name, including when they use it in
incorrect ways. - Discontinued
- The metadata name has received wide peer review and it has been found wanting. Existing
pages are using this metadata name, but new pages should avoid it. The «brief description» and
«specification» entries will give details of what authors should use instead, if anything.
If a metadata name is found to be redundant with existing values, it should be removed and
listed as a synonym for the existing value.If a metadata name is registered in the «proposed» state for a period of a month or more
without being used or specified, then it may be removed from the registry.If a metadata name is added with the «proposed» status and found to be redundant with
existing values, it should be removed and listed as a synonym for the existing value. If a
metadata name is added with the «proposed» status and found to be harmful, then it should be
changed to «discontinued» status.Anyone can change the status at any time, but should only do so in accordance with the
definitions above.
Conformance checkers may use the information given on the WHATWG
Wiki MetaExtensions page to establish if a value is allowed or not:
values defined in this specification or marked as «proposed» or
«ratified» must be accepted, whereas values marked as «discontinued»
or not listed in either this specification or on the aforementioned
page must be reported as invalid. Conformance checkers may cache
this information (e.g. for performance reasons or to avoid the use
of unreliable network connectivity).
When an author uses a new metadata name not defined by either this specification or the Wiki
page, conformance checkers should offer to add the value to the Wiki, with the details described
above, with the «proposed» status.
Metadata names whose values are to be URLs must not be proposed or
accepted. Links must be represented using the link element, not the meta
element.
4.2.5.3 Pragma directives
When the http-equiv attribute is specified
on a meta element, the element is a pragma directive.
The http-equiv attribute is an enumerated
attribute. The following table lists the keywords defined for this attribute. The states
given in the first cell of the rows with keywords give the states to which those keywords map.
Some of the keywords are non-conforming, as noted in the last
column.
| State | Keyword | Notes |
|---|---|---|
| Content Language | content-language
|
Non-conforming |
| Encoding declaration | content-type
|
|
| Default style | default-style
|
|
| Refresh | refresh
|
|
| Cookie setter | set-cookie
|
Non-conforming |
When a meta element is inserted
into the document, if its http-equiv attribute is
present and represents one of the above states, then the user agent must run the algorithm
appropriate for that state, as described in the following list:
- Content language state
(http-equiv="content-language") -
This feature is non-conforming. Authors are encouraged to use the
langattribute instead.This pragma sets the pragma-set default language. Until such a pragma is
successfully processed, there is no pragma-set default language.-
If the
metaelement has nocontent
attribute, then abort these steps. -
If the element’s
contentattribute contains a
«,» (U+002C) character then abort these steps. -
Let input be the value of the element’s
contentattribute. -
Let position point at the first character of input.
-
Skip whitespace.
-
Collect a sequence of characters that are not space characters.
-
Let candidate be the string that resulted from the previous
step. -
If candidate is the empty string, abort these steps.
-
Set the pragma-set default language to candidate.
This pragma is almost, but not quite, entirely unlike the HTTP
Content-Languageheader of the same name. [HTTP] -
- encoding declaration state (
http-equiv="content-type") -
The encoding declaration state is just
an alternative form of setting thecharsetattribute: it is a
character encoding declaration. This state’s user agent
requirements are all handled by the parsing section of the specification.For
metaelements with anhttp-equiv
attribute in the Encoding declaration
state, thecontentattribute must have a value
that is an ASCII case-insensitive match for a string that consists of: the literal
string «text/html;«, optionally followed by any number of space characters, followed by the literal string «charset=«, followed by one of the labels of
the character encoding of the character encoding
declaration.A document must not contain both a
metaelement with anhttp-equivattribute in the encoding declaration state and a
metaelement with thecharsetattribute
present.The encoding declaration state may be
used in HTML documents and in XML Documents. If the
encoding declaration state is used in
XML Documents, the name of the character
encoding must be an ASCII case-insensitive match for the string «UTF-8» (and the document is therefore forced to use UTF-8 as its encoding).The encoding declaration state
has no effect in XML documents, and is only allowed in order to facilitate migration to and from
XHTML. - Default style state (
http-equiv="default-style") -
This pragma sets the name of the default alternative style sheet set.
-
If the
metaelement has nocontent
attribute, or if that attribute’s value is the empty string, then abort these steps. -
Set the preferred style sheet set to the value of the element’s
contentattribute. [CSSOM]
-
- Refresh state (
http-equiv="refresh") -
This pragma acts as timed redirect.
-
If another
metaelement with anhttp-equivattribute in the Refresh state has already been successfully
processed (i.e. when it was inserted the user agent processed it and reached the last step of
this list of steps), then abort these steps. -
If the
metaelement has nocontent
attribute, or if that attribute’s value is the empty string, then abort these steps. -
Let input be the value of the element’s
contentattribute. -
Let position point at the first character of input.
-
Skip whitespace.
-
Collect a sequence of characters that are ASCII digits, and
parse the resulting string using the rules for parsing non-negative integers. If
the sequence of characters collected is the empty string, then no number will have been parsed;
abort these steps. Otherwise, let time be the parsed number. -
Collect a sequence of characters that are ASCII digits and
«.» (U+002E) characters. Ignore any collected characters. -
Skip whitespace.
-
Let url be the address of the current page.
-
If the character in input pointed to by position
is a «;» (U+003B) character or a «,» (U+002C) character, then advance position to the next character. Otherwise, jump to the last step. -
Skip whitespace.
-
If the character in input pointed to by position
is a «U» (U+0055) character or a U+0075 LATIN SMALL LETTER U character
(u), then advance position to the next character. Otherwise, jump to the
last step. -
If the character in input pointed to by position
is a «R» (U+0052) character or a U+0072 LATIN SMALL LETTER R character
(r), then advance position to the next character. Otherwise, jump to the
last step. -
If the character in input pointed to by position
is s «L» (U+004C) character or a U+006C LATIN SMALL LETTER L character
(l), then advance position to the next character. Otherwise, jump to the
last step. -
Skip whitespace.
-
If the character in input pointed to by position
is a «=» (U+003D), then advance position to the next character.
Otherwise, jump to the last step. -
Skip whitespace.
-
If the character in input pointed to by position
is either a «‘» (U+0027) character or «»» (U+0022) character, then let
quote be that character, and advance position to the
next character. Otherwise, let quote be the empty string. -
Let url be equal to the substring of input from
the character at position to the end of the string. -
If quote is not the empty string, and there is a character in url equal to quote, then truncate url at
that character, so that it and all subsequent characters are removed. -
Strip any trailing space characters from the end of
url. -
Strip any «tab» (U+0009), «LF» (U+000A), and «CR» (U+000D) characters from url.
-
Resolve the url value to an
absolute URL, relative to themetaelement. If this fails, abort
these steps. -
Perform one or more of the following steps:
-
After the refresh has come due (as defined below), if the user has not canceled the
redirect and if themetaelement’sDocument‘s active
sandboxing flag set does not have the sandboxed automatic features browsing
context flag set, navigate the
Document‘s browsing context to url, with
replacement enabled, and with theDocument‘s browsing
context as the source browsing context.For the purposes of the previous paragraph, a refresh is said to have come due as soon as
the later of the following two conditions occurs:- At least time seconds have elapsed since the document has
completely loaded, adjusted to take into account user or user agent
preferences. - At least time seconds have elapsed since the
meta
element was inserted into the
Document, adjusted to take into account user or user agent
preferences.
- At least time seconds have elapsed since the document has
-
Provide the user with an interface that, when selected, navigates a browsing context to
url, with theDocument‘s browsing context as
the source browsing context. -
Do nothing.
In addition, the user agent may, as with anything, inform the user of any and all aspects
of its operation, including the state of any timers, the destinations of any timed redirects,
and so forth. -
For
metaelements with anhttp-equiv
attribute in the Refresh state, thecontentattribute must have a value consisting either of:- just a valid non-negative integer, or
- a valid non-negative integer, followed by a U+003B SEMICOLON character
(;), followed by one or more space characters, followed
by a substring that is an ASCII case-insensitive match for the string «URL«, followed by a «=» (U+003D) character, followed by a valid
URL that does not start with a literal «‘» (U+0027) or «»» (U+0022) character.
In the former case, the integer represents a number of seconds before the page is to be
reloaded; in the latter case the integer represents a number of seconds before the page is to be
replaced by the page at the given URL.A news organization’s front page could include the following markup in the page’s
headelement, to ensure that the page automatically reloads from the server every
five minutes:<meta http-equiv="Refresh" content="300">
A sequence of pages could be used as an automated slide show by making each page refresh to
the next page in the sequence, using markup such as the following:<meta http-equiv="Refresh" content="20; URL=page4.html">
-
- Cookie setter (
http-equiv="set-cookie") -
This pragma sets an HTTP cookie. [COOKIES]
It is non-conforming. Real HTTP headers should be used instead.
-
If the
metaelement has nocontent
attribute, or if that attribute’s value is the empty string, then abort these steps. -
Obtain the storage mutex.
-
Act as if receiving a
set-cookie-string for the document’s address via a «non-HTTP» API,
consisting of the value of the element’scontent
attribute encoded as UTF-8. [COOKIES] [RFC3629]
-
There must not be more than one meta element with any particular state in the
document at a time.
4.2.5.4 Other pragma directives
Extensions to the predefined set of pragma
directives may, under certain conditions, be registered in the WHATWG Wiki PragmaExtensions page. [WHATWGWIKI]
Such extensions must use a name that is identical to an HTTP header registered in the Permanent
Message Header Field Registry, and must have behavior identical to that described for the HTTP
header. [IANAPERMHEADERS]
Pragma directives corresponding to headers describing metadata, or not requiring specific user
agent processing, must not be registered; instead, use metadata names. Pragma directives corresponding to headers
that affect the HTTP processing model (e.g. caching) must not be registered, as they would result
in HTTP-level behavior being different for user agents that implement HTML than for user agents
that do not.
Anyone is free to edit the WHATWG Wiki PragmaExtensions page at any time to add a pragma
directive satisfying these conditions. Such registrations must specify the following
information:
- Keyword
-
The actual name being defined. The name must match a previously-registered HTTP name with
the same requirements. - Brief description
-
A short non-normative description of the purpose of the pragma directive.
- Specification
- A link to the specification defining the corresponding HTTP header.
Conformance checkers must use the information given on the WHATWG Wiki PragmaExtensions page to
establish if a value is allowed or not: values defined in this specification or listed on the
aforementioned page must be accepted, whereas values not listed in either this specification or on
the aforementioned page must be rejected as invalid. Conformance checkers may cache this
information (e.g. for performance reasons or to avoid the use of unreliable network
connectivity).
4.2.5.5 Specifying the document’s character encoding
A character encoding declaration is a mechanism by which the character encoding used to store or transmit a document is specified.
The following restrictions apply to character
encoding declarations:
- The character encoding name given must be an ASCII case-insensitive match for
one of the labels of the character
encoding used to serialize the file. [ENCODING] - The character encoding declaration must be serialized without the use of character references or character escapes of any kind.
- The element containing the character encoding
declaration must be serialized completely within the first 1024 bytes of the
document.
In addition, due to a number of restrictions on meta elements, there can only be
one meta-based character encoding declaration per document.
If an HTML document does not start with a BOM, and its
encoding is not explicitly given by Content-Type
metadata, and the document is not an iframe srcdoc document, then the character encoding used must be
an ASCII-compatible character encoding, and the encoding must be specified using a
meta element with a charset attribute or a
meta element with an http-equiv attribute
in the encoding declaration state.
A character encoding declaration is required (either in the Content-Type metadata or explicitly in the file) even if the encoding
is US-ASCII, because a character encoding is needed to process non-ASCII characters entered by the
user in forms, in URLs generated by scripts, and so forth.
If the document is an iframe srcdoc
document, the document must not have a character encoding declaration. (In
this case, the source is already decoded, since it is part of the document that contained the
iframe.)
If an HTML document contains a meta element
with a charset attribute or a meta element
with an http-equiv attribute in the encoding declaration state, then the character
encoding used must be an ASCII-compatible character encoding.
Authors should use UTF-8. Conformance checkers may advise authors against using legacy
encodings. [RFC3629]
Authoring tools should default to using UTF-8 for newly-created documents. [RFC3629]
Encodings in which a series of bytes in the range 0x20 to 0x7E can encode characters other than
the corresponding characters in the range U+0020 to U+007E represent a potential security
vulnerability: a user agent that does not support the encoding (or does not support the label used
to declare the encoding, or does not use the same mechanism to detect the encoding of unlabeled
content as another user agent) might end up interpreting technically benign plain text content as
HTML tags and JavaScript. Authors should therefore not use these encodings. For example, this
applies to encodings in which the bytes corresponding to «<script>» in
ASCII can encode a different string. Authors should not use such encodings, which are known to
include JIS_C6226-1983, JIS_X0212-1990,
HZ-GB-2312, JOHAB (Windows code page 1361), encodings based on
ISO-2022, and encodings
based on EBCDIC. Furthermore, authors must not use the CESU-8, UTF-7, BOCU-1 and SCSU encodings,
which also fall into this category; these encodings were never intended for use for Web content.
[RFC1345]
[RFC1842]
[RFC1468]
[RFC2237]
[RFC1554]
[CP50220]
[RFC1922]
[RFC1557]
[CESU8]
[UTF7]
[BOCU1]
[SCSU]
Authors should not use UTF-32, as the encoding detection algorithms described in this
specification intentionally do not distinguish it from UTF-16. [UNICODE]
Using non-UTF-8 encodings can have unexpected results on form submission and URL
encodings, which use the document’s character encoding by default.
In XHTML, the XML declaration should be used for inline character encoding information, if
necessary.
In HTML, to declare that the character encoding is UTF-8, the author could include the
following markup near the top of the document (in the head element):
<meta charset="utf-8">
In XML, the XML declaration would be used instead, at the very top of the markup:
<?xml version="1.0" encoding="utf-8"?>
4.2.6 The style element
- Categories:
- Metadata content.
- Contexts in which this element can be used:
- Where metadata content is expected.
- In a
noscriptelement that is a child of aheadelement. - Content model:
- Depends on the value of the
typeattribute, but must match requirements described in prose below. - Content attributes:
- Global attributes
media— Applicable mediatype— Type of embedded resource- Also, the
titleattribute has special semantics on this element: Alternative style sheet set name. - Tag omission in text/html:
- Neither tag is omissible.
- Allowed ARIA role attribute values:
- none
- Allowed ARIA state and property attributes:
- Global aria-* attributes
- DOM interface:
-
interface HTMLStyleElement : HTMLElement { attribute boolean disabled; attribute DOMString media; attribute DOMString type; }; HTMLStyleElement implements LinkStyle;
The style element allows authors to embed style information in their documents.
The style element is one of several inputs to the styling processing
model. The element does not represent content for the
user.
The type attribute gives the styling language.
If the attribute is present, its value must be a valid MIME type that designates a
styling language. The charset parameter must not be specified. The default
value for the type attribute, which is used if the attribute
is absent, is «text/css«. [RFC2318]
When examining types to
determine if they support the language, user agents must not ignore unknown MIME parameters
— types with unknown parameters must be assumed to be unsupported. The charset parameter must be treated as an unknown parameter for the purpose of
comparing MIME types here.
The media attribute says which media the
styles apply to. The value must be a valid media query. The user
agent must apply the styles when the media attribute’s value
matches the environment and the other relevant conditions apply, and must not apply
them otherwise.
The styles might be further limited in scope, e.g. in CSS with the use of @media blocks. This specification does not override such further restrictions or
requirements.
The default, if the media
attribute is omitted, is «all«, meaning that by default styles apply to all
media.
The title attribute on
style elements defines alternative style sheet sets. If the
style element has no title attribute, then it
has no title; the title attribute of ancestors does not apply to
the style element. [CSSOM]
The title attribute on style
elements, like the title attribute on link
elements, differs from the global title attribute in that a
style block without a title does not inherit the title of the parent element: it
merely has no title.
The textContent of a style element must match the style production in the following ABNF, the character set for which is Unicode. [ABNF]
style = no-c-start *( c-start no-c-end c-end no-c-start ) no-c-start = < any string that doesn't contain a substring that matches c-start > c-start = "<!--" no-c-end = < any string that doesn't contain a substring that matches c-end > c-end = "-->"
All descendant elements must be processed, according to their semantics, before the
style element itself is evaluated. For styling languages that consist of pure text
(as opposed to XML), user agents must evaluate style elements by passing the
concatenation of the contents of all the Text nodes that are children of the
style element (not any other nodes such as comments or elements), in tree
order, to the style system. For XML-based styling languages, user agents must pass all the
child nodes of the style element to the style system.
All URLs found by the styling language’s processor must be resolved, relative to the element (or as defined by the styling
language), when the processor is invoked.
Once the attempts to obtain the style sheet’s critical subresources, if any, are
complete, or, if the style sheet has no critical subresources, once the style sheet
has been parsed and processed, the user agent must, if the loads were successful or there were
none, queue a task to fire a simple event named load at the style element, or, if one of the style sheet’s
critical subresources failed to completely load for any reason (e.g. DNS error, HTTP
404 response, a connection being prematurely closed, unsupported Content-Type), queue a
task to fire a simple event named error at
the style element. Non-network errors in processing the style sheet or its
subresources (e.g. CSS parse errors, PNG decoding errors) are not failures for the purposes of
this paragraph.
The task source for these tasks is the DOM
manipulation task source.
The element must delay the load event of the element’s document until all the
attempts to obtain the style sheet’s critical subresources, if any, are complete.
This specification does not specify a style system, but CSS is expected to be
supported by most Web browsers. [CSS]
The media and type IDL attributes must reflect the
respective content attributes of the same name.
The disabled IDL attribute behaves as
defined for the alternative style sheets DOM.
The LinkStyle interface is also implemented by this element; the styling
processing model defines how. [CSSOM]
The following document has its stress emphasis styled as bright red text rather than italics
text, while leaving titles of works and Latin words in their default italics. It shows how using
appropriate elements enables easier restyling of documents.
<!DOCTYPE html>
<html lang="en-US">
<head>
<title>My favorite book</title>
<style>
body { color: black; background: white; }
em { font-style: normal; color: red; }
</style>
</head>
<body>
<p>My <em>favorite</em> book of all time has <em>got</em> to be
<cite>A Cat's Life</cite>. It is a book by P. Rahmel that talks
about the <i lang="la">Felis Catus</i> in modern human society.</p>
</body>
</html>
4.2.7 Styling
The link and style elements can provide styling information for the
user agent to use when rendering the document. The CSS and CSSOM specifications specify what
styling information is to be used by the user agent and how it is to be used. [CSS] [CSSOM]
The style and link elements implement the LinkStyle
interface. [CSSOM]
For style elements, if the user agent does not support the specified styling
language, then the sheet attribute of the element’s
LinkStyle interface must return null. Similarly, link elements that do
not represent external resource links that contribute to the styling
processing model (i.e. that do not have a stylesheet
keyword in their rel attribute), for which the link is an
alternative stylesheet but whose title content attribute is
absent or empty, or whose resource is CORS-cross-origin, must have their
LinkStyle interface’s sheet attribute return
null.
Otherwise, the LinkStyle interface’s sheet attribute must return null if the corresponding element
is not in a Document,
and otherwise must return a StyleSheet object with the following properties: [CSSOM]
- The style sheet type
-
The style sheet type must be the same as the style’s specified type. For
styleelements, this is the same as thetype
content attribute’s value, ortext/cssif that is omitted. For
linkelements, this is the Content-Type metadata of the
specified resource. - The style sheet location
-
For
linkelements, the location must be the result of resolving the URL given by the element’shrefcontent attribute, relative to the element, or the empty
string if that fails. Forstyleelements, there is no location. - The style sheet media
-
The media must be the same as the value of the element’s
media
content attribute, or the empty string, if the attribute is omitted. - The style sheet title
-
The title must be the same as the value of the element’s
titlecontent attribute, if the attribute is present and has a non-empty
value. If the attribute is absent or its value is the empty string, then the style sheet does not
have a title (it is the empty string). The title is used for defining alternative style
sheet sets. - The style sheet alternate flag
-
For
linkelements, true if the link is an alternative
stylesheet. In all other cases, false.
The same object must be returned each time.
The disabled IDL attribute on
link and style elements must return false and do nothing on setting, if
the sheet attribute of their LinkStyle
interface is null. Otherwise, it must return the value of the StyleSheet interface’s
disabled attribute on getting, and forward the new
value to that same attribute on setting.
The rules for handling alternative style sheets are defined in the
CSS object model specification. [CSSOM]
Style sheets, whether added by a link element, a style element, an
<?xml-stylesheet> PI, an HTTP Link: header, or some
other mechanism, have a style sheet ready flag, which is initially unset.
When a style sheet is ready to be applied, its style sheet ready flag must be set.
If the style sheet referenced no other resources (e.g. it was an internal style sheet given by a
style element with no @import rules), then the style rules must
be synchronously made available to script; otherwise, the style rules must only be made available
to script once the event loop reaches its «update the rendering» step.
A style sheet in the context of the Document of an HTML parser or
XML parser is said to be a style sheet that is blocking scripts if the
element was created by that Document‘s parser, and the element is either a
style element or a link element that was an external resource link that contributes to the styling processing
model when the element was created by the parser, and the element’s style sheet was enabled
when the element was created by the parser, and the element’s style sheet ready flag
is not yet set, and, the last time the event loop reached step 1, the element was
in that Document, and the user agent hasn’t given
up on that particular style sheet yet. A user agent may give up on a style sheet at any time.
Giving up on a style sheet before the style sheet loads, if the style sheet
eventually does still load, means that the script might end up operating with incorrect
information. For example, if a style sheet sets the color of an element to green, but a script
that inspects the resulting style is executed before the sheet is loaded, the script will find
that the element is black (or whatever the default color is), and might thus make poor choices
(e.g. deciding to use black as the color elsewhere on the page, instead of green). Implementors
have to balance the likelihood of a script using incorrect information with the performance impact
of doing nothing while waiting for a slow network request to finish.
A Document has a style sheet that is blocking scripts if there is
either a style sheet that is blocking scripts in the context of that
Document, or if that Document is in a browsing context that
has a parent browsing context, and the active document of that
parent browsing context itself has a style sheet that is blocking
scripts.
A Document has no style sheet that is blocking scripts if it does not
have a style sheet that is blocking
scripts as defined in the previous paragraph.
В HTML тег <meta>
(от англ. metadata – метаданные)
используется для хранения метаданных (служебных данных), предназначенных для браузеров и поисковых систем, и располагается внутри элемента
<head>. Обычно на одной странице используется сразу несколько элеметов
<meta> с различными значениями атрибута <name>.
Синтаксис
<head> <meta> (закрывающий тег не требуется) </head>
Атрибуты
-
charset – сообщает браузеру кодировку документа и должен задаваться только один раз в одном из элементов
<meta>. Для веб-документов чаще всего используется кодировка UTF-8. -
content – используется совместно с атрибутами name и
http-equiv, устанавливая значения данных атрибутов. Разрешается указывать в одном атрибуте
content сразу несколько значений, перечисленных через запятую или точку с запятой. При этом следует помнить,
что одновременно использовать атрибуты name и http-equiv не разрешается. -
http-equiv – используется для конвертирования метатега в
http-заголовки. Может принимать значения:-
default-style – указывает предпочтительный для данной страницы стиль; при этом
атрибут content должен содержать
id элемента
<link>, ссылающегося на требуемую внешнюю таблицу стилей, или элемента
<style>, содержащего требуемую внутреннюю таблицу стилей; -
refresh – задает время в секундах до перезагрузки страницы (например,
<meta http-equiv=»refresh» content=»15″>) или перенаправления на другую
страницу, если атрибут content содержит целочисленное положительное число (время в секундах), после
которого идет строка с корректным url-адресом (например,
<meta http-equiv=»refresh» content=»15; url=httрs://site.com»>).
-
default-style – указывает предпочтительный для данной страницы стиль; при этом
-
name – используется совместно с атрибутом content и определяет
назначение текущего тега <meta>. Может принимать значения:- author – в атрибуте content указывается имя автора;
-
copyright – если страница разрабатывалась организацией, то авторство обычно не указывается,
а используется название организации; -
description – когда атрибут name имеет такое
значение, в атрибуте content приводится краткое описание страницы, которое используется
поисковыми машинами для индексации, а также выводе ими аннотации при выдаче по запросу; -
document-state – для этого имени атрибут content
может принимать два значения: static и
dynamic; в первом случае поисковым машинам сообщается, что документ нужно индексировать только один
раз и нет необходимости в индексации в дальнейшем; во втором случае от поисковых машин требуется постоянная индексация веб-страницы; -
robots – для этого имени используется ряд значений атрибута
content:- index – роботам разрешается индексировать данную страницу;
-
noindex – роботам запрещается индексировать данную страницу; при этом она не
попадает в базу поисковой машины и, соответственно, её невозможно будет найти через поисковую систему; - follow – роботам разрешается переходить по ссылкам на данной странице;
-
nofollow – роботам запрещается переходить по ссылкам на данной странице;
кроме того, ссылкам не передаётся ТИЦ (тематический индекс цитирования) и
PageRank (определяет «важность» страницы); - noarchive – роботам запрещается кешировать данную страницу;
-
revisit – используется для управления частотой индексации веб-страницы в поисковой системе;
например, для переиндексации страницы раз в три недели в качестве значения атрибута content следует
указать «21»; -
url – для этого имени атрибут content принимает в качестве
значения адрес, по которому робот поисковой системы перенаправляется для индексации на другую страницу (текущая страница при этом не
индексируется); это нужно для отмены индексации «зеркала» и генерируемых страниц.
-
viewport – указывает браузеру мобильного устройства, как обрабатывать размеры страницы и изменять ее
масштаб. Cоответствующий ряд значений атрибута content имеет вид:-
«width» – значение задает ширину области просмотра и через знак равно в
качестве значений принимает:-
device-width — ширина области просмотра будет подстраиваться под ширину экрана
(значение подходит для большинства случаев); -
аппаратно-независимые пиксели — задается фиксированная ширина области просмотра в
аппаратно-независимых пикселях, при этом доступен диапазон целых чисел от 200px —
10 000px (фиксированную ширину применять не рекомендуется!);
-
device-width — ширина области просмотра будет подстраиваться под ширину экрана
-
«height» – значение задает высоту области просмотра (используется редко) и через знак равно в
качестве значений принимает:-
device-height — высота области просмотра будет подстраиваться под высоту экрана
(значение подходит для большинства случаев); -
аппаратно-независимые пиксели — задается фиксированная высота области просмотра в
аппаратно-независимых пикселях, при этом доступен диапазон целых чисел от 223px —
10 000px (фиксированную высоту применять не рекомендуется!);
-
device-height — высота области просмотра будет подстраиваться под высоту экрана
-
«initial-scale» – устанавливает соответствие для пикселей CSS
(это те пиксели, которые мы задаем в таблицах стилей) и аппаратно-независимых пикселей мобильного устройства (это виртуальные пиксели,
которые являются результатом масштабирования аппаратных (физических) пикселей устройства, их величина примерно
одинакова для всех устройств); проще говоря, свойство устанавливает стартовую величину масштабирования страницы; в качестве
значения через знак равно принимаются числа от 0.1 до 10 (чем больше
число, тем больше масштаб, т.е. увеличение страницы), например, «initial-scale=2» можно рассматривать,
как увеличение масштаба страницы в два раза; -
«user-scalable» – разрешает либо запрещает пользователю изменять масштаб страницы; в качестве
значения через знак равно принимает yes либо no
(масштабирование в ряде случаев целесообразно запрещать, например, для мобильных приложений).
-
«width» – значение задает ширину области просмотра и через знак равно в
-
Также для элемента доступны универсальные атрибуты и
соответствующие атрибуты-события.
Ссылки
Примеры
<!DOCTYPE html> <html> <head> <!-- Сообщаем браузеру кодировку документа --> <meta charset="utf-8"> <!-- Указываем автора страницы --> <meta name="author" content="Romanovsky Peter"> <!-- Описываем страницу --> <meta name="description" content="Атрибуты тега meta"> <!-- Разрешаем индексировать страницу постоянно --> <meta name="document-state" content="dynamic"> <!-- Разрешаем переиндексировать раз в 2 недели --> <meta name="revisit" content="14"> <!-- Разрешаем роботам посещать и ходить по ссылкам страницы --> <meta name="robots" content="index, follow"> <!-- Просим робота поисковой машины индексировать другую страницу. --> <meta name="url" content="https://site.name/html/teg_meta.html"> <title>Пример №1</title> </head> <body> ... Тут расположена выводимая информация. ... </body> </html>
Пример №1
<!DOCTYPE html> <html> <head> <!-- Сообщаем браузеру кодировку документа --> <meta charset="utf-8"> <!-- Перенаправление на другую страницу через 3 секунды --> <meta http-equiv="refresh" content="3; url=https://site.name/html/teg_meta.html"> <!-- 1. Ширина области просмотра подстраивается --> <!-- под ширину экрана мобильного устройства автоматически --> <!-- 2. Пользователю разрешается масштабировать страницу (user-scalable=yes) --> <!-- Данный вариант в большинстве случаев наиболее оптимальный --> <meta name="viewport" content="width=device-width, user-scalable=yes"> <title>Пример №2</title> </head> <body> ... Тут расположена выводимая информация. ... </body> </html>
Пример №2