Технологии и методы программирования.
Лекция 13.
Синхронизация.
В CUDA поддерживается
барьерная синхронизация для потоков
одного блока — synchthread().
Для разных блоков прямой
синхронизации нет- только атомарными
операциями. При этом снижается
производительность системы.
Управление устройствами.
CUDAGetDeviceCount(int *count) – число
доступных устройств.
CUDAGetDevice(int *det) – номер
устройства
CUDAGetDeviceProperties(CUDAdevice *prop, int dev)
– свойства устройства
по его номеру.
CUDASetDevice(int dev) – устанавливает
за программой устройства, на которых
будут выполняться ядра.
Управление памятью.
CUDAMalloc(void **devptr, size_t count) –
выделяет память на
устройстве, возвращает указатель на
эту память.
CUDAFree(void *devptr) – освобождает
память.
CUDAMemcpy(void *dst, const void *sre, size_t
size, enum CUDAMemcpykind kind) – копирует
память. enum CUDAMemcpykind задаёт
направление — от центрального процессора
к графическому или наоборот.
У всех перечисленных функций
возвращаемое значение — CUDAError_T.
Особенности компиляции.
Все функции со спецификатором
device – встраиваемые.
_noinline_ устраняет
это.
По умолчанию небольшие циклы
разворачиваются. Но если указать #pragma
unrall N=1, то это не будет
происходить.
Основные этапы программирования.
1) Разработка функций ядер.
2) Распределение памяти, инициализация
данных.
3) Запуск ядра.
Программирование с использованием
OpenCL.
Отличается оригинальной архитектурой,
иерархией моделей.
Модели:
1) Платформы.
2) Памяти
3) Исполнения
4) Программирования.
Модель платформы.
Платформа — host-система
и несколько устройств. Устройство —
один или более вычислительных модулей.
Модуль — несколько обрабатывающих
элементов. Все вычисления выполняются
именно ими.
Управляющая часть запускается
на хосте. При этом создаётся очередь
команд, передаваемая обрабатывающим
элементам. Элементы одного модуля могут
выполнять поток инструкций по схеме
SIMD или SPMD.
Модель исполнения.
Приложения состоят из двух компонент:
ядер, выполняемых на устройствах, и
управляющих программ, организующих
работу ядер.
Исполнение ядер.
Перед запуском каких-либо функций
определяется пространство индексов.
Каждый экземпляр ядра выполняется для
некоторой точки этого пространства.
Каждый элемент работы получает глобальный
идентификатор. Элементы работы
объединяются в группы, группам также
дают идентификаторы. Их размерность
совпадает с размерностью пространства
индексов. Каждый элемент имеет уникальных
локальный идентификатор. Все элементы
одной группы выполняются на одном
вычислительном модуле. В группе
поддерживается барьерная синхронизация,
а для элементов разных групп — нет.
Стандарт предполагает
использование n-мерного
прстранства индексов, но на практике
реализованы одно-, двух- и трёхмерные
пространства. Пространство определяется
массивом целых чисел. Глобальные и
локальные идентификаторы — n-мерные
вектора. Идентификаторы групп — тоже
массивы с координатами, ограниченными
количеством групп по измерению.
Управляющая программа создаёт
структуру данных — контекст, и определяет
среду исполнения ядер. При этом происходит
выделение и распределение памяти
различных типов, обеспечивается передача
данных, создаётся очередь команд. В этой
очереди присутствуют команды выполнения
ядер, управления памятью, синхронизации.
Интерфейс OpenCL обеспечивает
контроль завершения работы ядра, после
которого возможна передача результатов
в ЦПУ, использование их как входных для
других ядер.
Модель памяти.
-
Глобальная память — доступна каждому
элементу работы. -
Константная — также общедоступна, но
только для чтения (хотя управляющая
программа может писать и в неё). -
Локальная — доступна только в этой
группе. -
Частная память — доступна только для
одного элемента работы. Используется
по умолчанию, для работы с любой другой
памятью необходимо отдельно объявлять
её спецификатором.
Модель программирования.
Две схемы программирования:
-
Параллельное по данным.
-
Параллельное по функциям.
Первое предполагает одновременное
выполнение элементов работы, при котором
любой элемент работы обрабатывает свою
порцию данных, определённую точкой
пространства индексов. Второе предполагает
вычисление нескольких потоков (очередей
команд), исполняющих разные версии
программы. Возможно создание нескольких
очередей для выполнения на нескольких
устройствах.
Соседние файлы в папке Лекции
- #
06.07.201673.19 Кб23Лекция 10.odt
- #
- #
06.07.201668.73 Кб23Лекция 11.odt
- #
- #
06.07.201671.71 Кб23Лекция 12.odt
- #
- #
06.07.201625.73 Кб23Лекция 13.odt
- #
- #
06.07.201665.12 Кб23Лекция 14.odt
- #
- #
06.07.201666.68 Кб23Лекция 2.odt
Чтобы дать более полное представление о многопроцессорных вычислительных системах, помимо высокой производительности необходимо назвать и другие отличительные особенности. Прежде всего, это необычные архитектурные решения, направленные на повышение производительности (работа с векторными операциями, организация быстрого обмена сообщениями между процессорами или организация глобальной памяти в многопроцессорных системах и др.).
Понятие архитектуры высокопроизводительной системы является достаточно широким, поскольку под архитектурой можно понимать и способ параллельной обработки данных, используемый в системе, и организацию памяти, и топологию связи между процессорами, и способ исполнения системой арифметических операций. Попытки систематизировать все множество архитектур впервые были предприняты в конце 60-х годов и продолжаются по сей день.
В 1966 г. М. Флинном (Flynn) был предложен чрезвычайно удобный подход к классификации архитектур вычислительных систем. В его основу было положено понятие потока, под которым понимается последовательность элементов, команд или данных, обрабатываемая процессором.
Соответствующая система классификации основана на рассмотрении числа потоков инструкций и потоков данных и описывает четыре архитектурных класса:
- SISD (Single Instruction Single Data) – 1 поток команд и 1 поток данных.
- MISD (Multiple Instruction Single Data) – несколько потоков команд и 1 поток данных.
- SIMD (Single Instruction Multiple Data) – 1 поток команд и несколько потоков данных.
- MIMD (Multiple Instruction Multiple Data) – несколько потоков команд и несколько потоков данных.
|
|
|
|
Рисунок 5.1 – Архитектура SISD, 1 поток команд и 1 поток данных |
Рисунок 5.2 – Архитектура MISD, несколько потоков команд и 1 поток данных |
|
|
|
|
Рисунок 5.3 – Архитектура SIMD, 1 поток команд и несколько потоков данных |
Рисунок 5.4 – MIMD, несколько потоков команд и несколько потоков данных |
SISD (single instruction stream / single data stream) – одиночный поток команд и одиночный поток данных. К этому классу относятся последовательные компьютерные системы, которые имеют один центральный процессор, способный обрабатывать только один поток последовательно исполняемых инструкций.
В настоящее время практически все высокопроизводительные системы имеют более одного центрального процессора, однако каждый из них выполняет несвязанные потоки инструкций, что делает такие системы комплексами SISD-систем, действующих на разных пространствах данных.
Для увеличения скорости обработки команд и скорости выполнения арифметических операций может применяться конвейерная обработка. В случае векторных систем векторный поток данных следует рассматривать как поток из одиночных неделимых векторов.
Примерами компьютеров с архитектурой SISD могут служить большинство рабочих станций Compaq, Hewlett-Packard и Sun Microsystems.
MISD (multiple instruction stream / single data stream) – множественный поток команд и одиночный поток данных. Теоретически в этом типе машин множество инструкций должно выполняться над единственным потоком данных. До сих пор ни одной реальной машины, попадающей в данный класс, создано не было. В качестве аналога работы такой системы, по-видимому, можно рассматривать работу банка. С любого терминала можно подать команду и что-то сделать с имеющимся банком данных. Поскольку база данных одна, а команд много, мы имеем дело с множественным потоком команд и одиночным потоком данных.
SIMD (single instruction stream / multiple data stream) – одиночный поток команд и множественный поток данных. Эти системы обычно имеют большое количество процессоров (от 1024 до 16384), которые могут выполнять одну и ту же инструкцию относительно разных данных в жесткой конфигурации. Единственная инструкция параллельно выполняется над многими элементами данных.
Примерами SIMD-машин являются системы CPP DAP, Gamma II и Quadrics Apemille.
Другим подклассом SIMD-систем являются векторные компьютеры. Векторные компьютеры манипулируют массивами сходных данных подобно тому, как скалярные машины обрабатывают отдельные элементы таких массивов. Это делается за счет использования специально сконструированных векторных центральных процессоров. Когда данные обрабатываются посредством векторных модулей, результаты могут быть выданы на один, два или три такта частотогенератора (такт частотогенератора является основным временным параметром системы). При работе в векторном режиме векторные процессоры обрабатывают данные практически параллельно, что делает их в несколько раз более быстрыми, чем при работе в скалярном режиме. Примерами систем подобного типа являются, например, компьютеры Hitachi S3600.
MIMD (multiple instruction stream / multiple data stream) – множественный поток команд и множественный поток данных. Эти машины параллельно выполняют несколько потоков инструкций над различными потоками данных. В отличие от упомянутых выше многопроцессорных SISD-машин, команды и данные связаны, потому что они представляют различные части одной и той же задачи. Например, MIMD-системы могут параллельно выполнять множество подзадач с целью сокращения времени выполнения основной задачи.
Большое разнообразие попадающих в MIMD класс вычислительных систем делает классификацию Флинна не полностью адекватной. Действительно, и четырехпроцессорный SX-5 компании NEC, и тысячепроцессорный Cray T3E попадают в этот класс. Это заставляет использовать другой подход к классификации, иначе описывающий классы компьютерных систем.
Другой подход к классификации состоит в разделении вычислительных систем по способам обработки множественного потока команд.
Одним конвейерным устройством обработки, работающем в режиме разделения времени для отдельных потоков. Такая возможность используется в MIMD-компьютерах, которые обычно называют конвейерными или векторными. В основе векторных компьютеров лежит концепция конвейеризации, т.е. явного сегментирования арифметического устройства на отдельные части, каждая из которых выполняет свою подзадачу для пары операндов.
Каждый поток обрабатывается своим собственным устройством. Такая возможность используется в параллельных компьютерах. В основе параллельного компьютера лежит идея использования для решения одной задачи нескольких процессоров, работающих сообща, причем процессоры могут быть как скалярными, так и векторными.
Классификация архитектур вычислительных систем нужна для того, чтобы понять особенности работы той или иной архитектуры, но она не является достаточно детальной, чтобы на нее можно было опираться при создании МВС, поэтому следует вводить более детальную классификацию, которая связана с различными архитектурами ЭВМ и с используемым оборудованием.
Аннотация: В данной лекции дается определение понятия архитектуры высокопроизводительной системы, приводится классификация архитектур, основанная на рассмотрении числа потоков инструкций и потоков данных.
Чтобы дать более полное представление о многопроцессорных вычислительных системах, помимо высокой производительности необходимо назвать и другие отличительные особенности. Прежде всего, это необычные архитектурные решения, направленные на повышение производительности (работа с векторными операциями, организация быстрого обмена сообщениями между процессорами или организация глобальной памяти в многопроцессорных системах и др.).
Понятие архитектуры высокопроизводительной системы является достаточно широким, поскольку под архитектурой можно понимать и способ параллельной обработки данных, используемый в системе, и организацию памяти, и топологию связи между процессорами, и способ исполнения системой арифметических операций. Попытки систематизировать все множество архитектур впервые были предприняты в конце 60-х годов и продолжаются по сей день.
В 1966 г. М.Флинном (Flynn) был предложен чрезвычайно удобный подход к классификации архитектур вычислительных систем. В его основу было положено понятие потока, под которым понимается последовательность элементов, команд или данных, обрабатываемая процессором. Соответствующая система классификации основана на рассмотрении числа потоков инструкций и потоков данных и описывает четыре архитектурных класса:
SISD = Single Instruction Single Data MISD = Multiple Instruction Single Data SIMD = Single Instruction Multiple Data MIMD = Multiple Instruction Multiple Data
SISD (single instruction stream / single data stream) – одиночный поток команд и одиночный поток данных. К этому классу относятся последовательные компьютерные системы, которые имеют один центральный процессор, способный обрабатывать только один поток последовательно исполняемых инструкций. В настоящее время практически все высокопроизводительные системы имеют более одного центрального процессора, однако каждый из них выполняет несвязанные потоки инструкций, что делает такие системы комплексами SISD-систем, действующих на разных пространствах данных. Для увеличения скорости обработки команд и скорости выполнения арифметических операций может применяться конвейерная обработка. В случае векторных систем векторный поток данных следует рассматривать как поток из одиночных неделимых векторов. Примерами компьютеров с архитектурой SISD могут служить большинство рабочих станций Compaq, Hewlett-Packard и Sun Microsystems.
MISD (multiple instruction stream / single data stream) – множественный поток команд и одиночный поток данных. Теоретически в этом типе машин множество инструкций должно выполняться над единственным потоком данных. До сих пор ни одной реальной машины, попадающей в данный класс, создано не было. В качестве аналога работы такой системы, по-видимому, можно рассматривать работу банка. С любого терминала можно подать команду и что-то сделать с имеющимся банком данных. Поскольку база данных одна, а команд много, мы имеем дело с множественным потоком команд и одиночным потоком данных.
SIMD (single instruction stream / multiple data stream) – одиночный поток команд и множественный поток данных. Эти системы обычно имеют большое количество процессоров, от 1024 до 16384, которые могут выполнять одну и ту же инструкцию относительно разных данных в жесткой конфигурации. Единственная инструкция параллельно выполняется над многими элементами данных. Примерами SIMD-машин являются системы CPP DAP, Gamma II и Quadrics Apemille. Другим подклассом SIMD-систем являются векторные компьютеры. Векторные компьютеры манипулируют массивами сходных данных подобно тому, как скалярные машины обрабатывают отдельные элементы таких массивов. Это делается за счет использования специально сконструированных векторных центральных процессоров. Когда данные обрабатываются посредством векторных модулей, результаты могут быть выданы на один, два или три такта частотогенератора (такт частотогенератора является основным временным параметром системы). При работе в векторном режиме векторные процессоры обрабатывают данные практически параллельно, что делает их в несколько раз более быстрыми, чем при работе в скалярном режиме. Примерами систем подобного типа являются, например, компьютеры Hitachi S3600.
MIMD (multiple instruction stream / multiple data stream) – множественный поток команд и множественный поток данных. Эти машины параллельно выполняют несколько потоков инструкций над различными потоками данных. В отличие от упомянутых выше многопроцессорных SISD-машин, команды и данные связаны, потому что они представляют различные части одной и той же задачи. Например, MIMD-системы могут параллельно выполнять множество подзадач с целью сокращения времени выполнения основной задачи. Большое разнообразие попадающих в данный класс систем делает классификацию Флинна не полностью адекватной. Действительно, и четырехпроцессорный SX-5 компании NEC, и тысячепроцессорный Cray T3E попадают в этот класс. Это заставляет использовать другой подход к классификации, иначе описывающий классы компьютерных систем. Основная идея такого подхода может состоять, например, в следующем. Будем считать, что множественный поток команд может быть обработан двумя способами: либо одним конвейерным устройством обработки, работающем в режиме разделения времени для отдельных потоков, либо каждый поток обрабатывается своим собственным устройством. Первая возможность используется в MIMD-компьютерах, которые обычно называют конвейерными или векторными, вторая – в параллельных компьютерах. В основе векторных компьютеров лежит концепция конвейеризации, т.е. явного сегментирования арифметического устройства на отдельные части, каждая из которых выполняет свою подзадачу для пары операндов. В основе параллельного компьютера лежит идея использования для решения одной задачи нескольких процессоров, работающих сообща, причем процессоры могут быть как скалярными, так и векторными.
Классификация архитектур вычислительных систем нужна для того, чтобы понять особенности работы той или иной архитектуры, но она не является достаточно детальной, чтобы на нее можно было опираться при создании МВС, поэтому следует вводить более детальную классификацию, которая связана с различными архитектурами ЭВМ и с используемым оборудованием.
Архитектура системы–совокупность свойств системы, существенных для пользования.
Архитектурой компьютера называется его описание на некотором общем уровне, включающее описание пользовательских возможностей программирования, системы команд, системы адресации, организации памяти и т.д. Архитектура определяет принципы действия, информационные связи и взаимное соединение основных логических узлов компьютера: процессора, оперативного ЗУ, внешних ЗУ и периферийных устройств. Общность архитектуры разных компьютеров обеспечивает их совместимость с точки зрения пользователя.
Наиболее распространены следующие архитектурные решения.
Классическая архитектура (архитектура фон Неймана) — одно арифметико-логическое устройство (АЛУ), через которое проходит поток данных, и одно устройство управления (УУ), через которое проходит поток команд — программа. Это однопроцессорный компьютер.
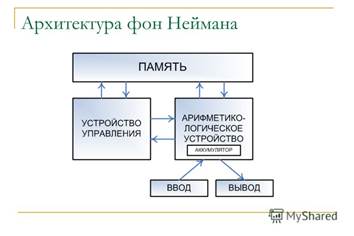
К этому типу архитектуры относится и архитектура персонального компьютера с общей шиной. Все функциональные блоки здесь связаны между собой общей шиной, называемой также системной магистралью.
Физически магистраль представляет собой многопроводную линию с гнездами для подключения электронных схем. Совокупность проводов магистрали разделяется на отдельные группы: шину адреса, шину данных и шину управления.
Периферийные устройства (принтер и др.) подключаются к аппаратуре компьютера через специальные контроллеры — устройства управления периферийными устройствами.
Контроллер — устройство, которое связывает периферийное оборудование или каналы связи с центральным процессором, освобождая процессор от непосредственного управления функционированием данного оборудования.
Многопроцессорная архитектура. Наличие в компьютере нескольких процессоров означает, что параллельно может быть организовано много потоков данных и много потоков команд. Таким образом, параллельно могут выполняться несколько фрагментов одной задачи.
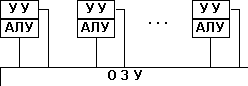
Многомашинная вычислительная система. Здесь несколько процессоров, входящих в вычислительную систему, не имеют общей оперативной памяти, а имеют каждый свою (локальную). Каждый компьютер в многомашинной системе имеет классическую архитектуру, и такая система применяется достаточно широко. Однако эффект от применения такой вычислительной системы может быть получен только при решении задач, имеющих очень специальную структуру: она должна разбиваться на столько слабо связанных подзадач, сколько компьютеров в системе.
Преимущество в быстродействии многопроцессорных и многомашинных вычислительных систем перед однопроцессорными очевидно.
Архитектура с параллельными процессорами. Здесь несколько АЛУ работают под управлением одного УУ. Это означает, что множество данных может обрабатываться по одной программе — то есть по одному потоку команд. Высокое быстродействие такой архитектуры можно получить только на задачах, в которых одинаковые вычислительные операции выполняются одновременно на различных однотипных наборах данных.
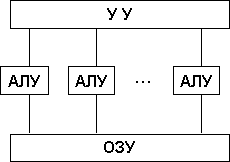
Самой ранней и наиболее известной является классификация архитектур вычислительных систем, предложенная в 1966 году М.Флинном. Классификация базируется на понятии потока, под которым понимается последовательность элементов, команд или данных, обрабатываемая процессором. На основе числа потоков команд и потоков данных Флинн выделяет четыре класса архитектур: SISD,MISD,SIMD,MIMD.
SISD (single instruction stream / single data stream) – одиночный поток команд и одиночный поток данных. К этому классу относятся последовательные компьютерные системы, которые имеют один центральный процессор, способный обрабатывать только один поток последовательно исполняемых инструкций. В настоящее время практически все высокопроизводительные системы имеют более одного центрального процессора, однако каждый из них выполняет несвязанные потоки инструкций, что делает такие системы комплексами SISD-систем, действующих на разных пространствах данных. Для увеличения скорости обработки команд и скорости выполнения арифметических операций может применяться конвейерная обработка. В случае векторных систем векторный поток данных следует рассматривать как поток из одиночных неделимых векторов. Примерами компьютеров с архитектурой SISD могут служить большинство рабочих станций Compaq, Hewlett-Packard и Sun Microsystems.
MISD (multiple instruction stream / single data stream) – множественный поток команд и одиночный поток данных. Теоретически в этом типе машин множество инструкций должно выполняться над единственным потоком данных. До сих пор ни одной реальной машины, попадающей в данный класс, создано не было. В качестве аналога работы такой системы, по-видимому, можно рассматривать работу банка. С любого терминала можно подать команду и что-то сделать с имеющимся банком данных. Посколькубаза данных одна, а команд много, мы имеем дело с множественным потоком команд и одиночным потоком данных.
SIMD (single instruction stream / multiple data stream) – одиночный поток команд и множественный поток данных. Эти системы обычно имеют большое количество процессоров, от 1024 до 16384, которые могут выполнять одну и ту же инструкцию относительно разных данных в жесткой конфигурации. Единственная инструкция параллельно выполняется над многими элементами данных. Примерами SIMD-машин являются системы CPP DAP, Gamma II и Quadrics Apemille. Другим подклассом SIMD-систем являются векторные компьютеры. Векторные компьютеры манипулируют массивами сходных данных подобно тому, как скалярные машины обрабатывают отдельные элементы таких массивов. Это делается за счет использования специально сконструированных векторных центральных процессоров. Когда данные обрабатываются посредством векторных модулей, результаты могут быть выданы на один, два или три такта частотогенератора (такт частотогенератора является основным временным параметром системы). При работе в векторном режиме векторные процессоры обрабатывают данные практически параллельно, что делает их в несколько раз более быстрыми, чем при работе в скалярном режиме. Примерами систем подобного типа являются, например, компьютеры Hitachi S3600.
MIMD (multiple instruction stream / multiple data stream) – множественный поток команд и множественный поток данных. Эти машины параллельно выполняют несколько потоков инструкций над различными потоками данных. В отличие от упомянутых выше многопроцессорных SISD-машин, команды и данные связаны, потому что они представляют различные части одной и той же задачи. Например, MIMD-системы могут параллельно выполнять множество подзадач с целью сокращения времени выполнения основной задачи. Большое разнообразие попадающих в данный класссистем делает классификацию Флинна не полностью адекватной, поэтому существуют дополненные и расширенные классификации, именованные фамилиями разработчиков.
Классификация архитектур вычислительных систем нужна для того, чтобы понять особенности работы той или иной архитектуры, но она не является достаточно детальной, чтобы на нее можно было опираться при создании МВС, поэтому следует вводить более детальную классификацию, которая связана с различными архитектурами ЭВМ и с используемым оборудованием.
Источники:
https://helpiks.org/6-1433.html
Существуют различные стили архитектуры системы и памяти, которые необходимо учитывать при разработке программы или параллельной системы. Это очень необходимо, потому что одна система и стиль памяти могут быть подходящими для одной задачи, но могут быть подвержены ошибкам другой задачи.
Архитектуры компьютерных систем, поддерживающие параллелизм
Майкл Флинн в 1972 году дал таксономию для классификации различных стилей архитектуры компьютерной системы. Эта таксономия определяет четыре различных стиля следующим образом:
- Один поток команд, один поток данных (SISD)
- Один поток инструкций, несколько потоков данных (SIMD)
- Поток с несколькими инструкциями, один поток данных (MISD)
- Многократный поток команд, многократный поток данных (MIMD).
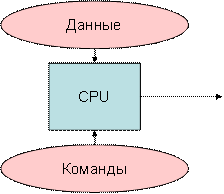
Один поток команд, один поток данных (SISD)
Как следует из названия, системы такого типа будут иметь один последовательный входящий поток данных и один единственный блок обработки для выполнения потока данных. Они похожи на однопроцессорные системы с параллельной вычислительной архитектурой. Ниже приводится архитектура SISD –
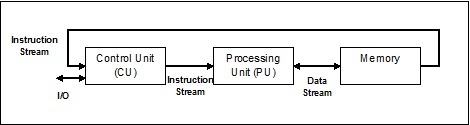
Преимущества СИСД
Преимущества архитектуры SISD следующие:
- Это требует меньше энергии.
- Нет проблем со сложным протоколом связи между несколькими ядрами.
Недостатки СИСД
Недостатки архитектуры SISD следующие:
- Скорость архитектуры SISD ограничена, как и у одноядерных процессоров.
- Это не подходит для больших приложений.
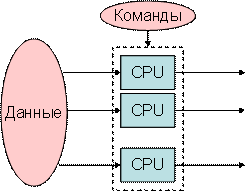
Один поток инструкций, несколько потоков данных (SIMD)
Как следует из названия, системы такого типа будут иметь несколько входящих потоков данных и количество блоков обработки, которые могут выполнять одну инструкцию в любой момент времени. Они похожи на многопроцессорные системы с параллельной вычислительной архитектурой. Ниже приводится архитектура SIMD –
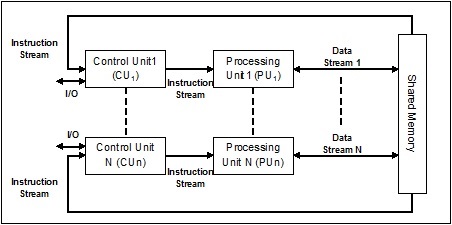
Лучший пример для SIMD – это видеокарты. Эти карты имеют сотни отдельных процессоров. Если говорить о разнице в вычислениях между SISD и SIMD, то для массивов добавления [5, 15, 20] и [15, 25, 10] архитектура SISD должна будет выполнить три различные операции добавления. С другой стороны, с архитектурой SIMD, мы можем добавить одну операцию добавления.
Преимущества SIMD
Преимущества SIMD-архитектуры следующие:
-
Одна и та же операция над несколькими элементами может быть выполнена с использованием только одной инструкции.
-
Пропускная способность системы может быть увеличена за счет увеличения количества ядер процессора.
-
Скорость обработки выше, чем у архитектуры SISD.
Одна и та же операция над несколькими элементами может быть выполнена с использованием только одной инструкции.
Пропускная способность системы может быть увеличена за счет увеличения количества ядер процессора.
Скорость обработки выше, чем у архитектуры SISD.
Недостатки SIMD
Недостатки SIMD-архитектуры следующие:
- Существует сложная связь между числами ядер процессора.
- Стоимость выше, чем у архитектуры SISD.
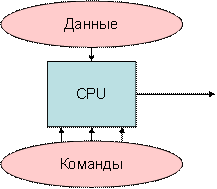
Поток нескольких данных с одной инструкцией (MISD)
Системы с потоком MISD имеют количество блоков обработки, выполняющих разные операции, выполняя разные инструкции для одного и того же набора данных. Ниже приводится архитектура MISD –
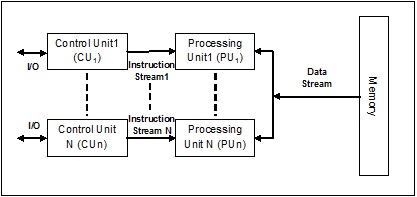
Представители архитектуры MISD еще не существуют коммерчески.
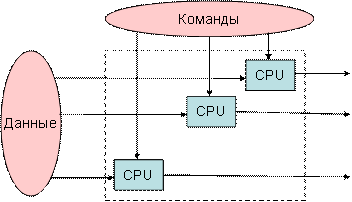
Поток нескольких данных с несколькими командами (MIMD)
В системе, использующей архитектуру MIMD, каждый процессор в многопроцессорной системе может выполнять разные наборы команд независимо от другого набора данных, установленного параллельно. Это противоположно архитектуре SIMD, в которой одна операция выполняется над несколькими наборами данных. Ниже приводится архитектура MIMD –
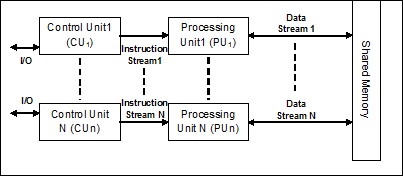
Обычный мультипроцессор использует архитектуру MIMD. Эти архитектуры в основном используются в ряде областей применения, таких как автоматизированное проектирование / автоматизированное производство, моделирование, моделирование, переключатели связи и т. Д.
Архитектуры памяти, поддерживающие параллелизм
При работе с такими понятиями, как параллелизм и параллелизм, всегда необходимо ускорить выполнение программ. Одним из решений, найденных разработчиками компьютеров, является создание нескольких компьютеров с общей памятью, то есть компьютеров, имеющих единственное физическое адресное пространство, доступ к которому имеют все ядра процессора. В этом сценарии может быть несколько разных стилей архитектуры, но вот три важных стиля архитектуры:
UMA (унифицированный доступ к памяти)
В этой модели все процессоры равномерно распределяют физическую память. Все процессоры имеют одинаковое время доступа ко всем словам памяти. Каждый процессор может иметь личную кеш-память. Периферийные устройства следуют ряду правил.
Когда все процессоры имеют равный доступ ко всем периферийным устройствам, система называется симметричным мультипроцессором . Когда только один или несколько процессоров могут получить доступ к периферийным устройствам, система называется асимметричным мультипроцессором .
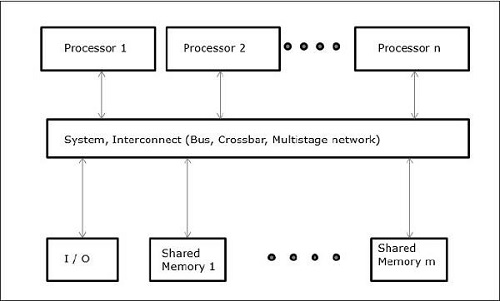
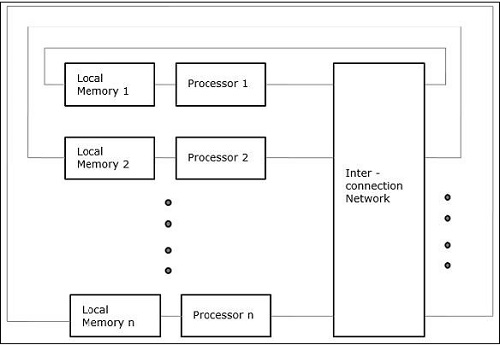
Неоднородный доступ к памяти (NUMA)
В многопроцессорной модели NUMA время доступа зависит от местоположения слова памяти. Здесь разделяемая память физически распределяется между всеми процессорами, называемой локальной памятью. Коллекция всей локальной памяти образует глобальное адресное пространство, к которому могут обращаться все процессоры.
Архитектура кэш-памяти только (COMA)
Модель COMA является специализированной версией модели NUMA. Здесь все распределенные основные памяти преобразуются в кэш-память.