AVX-512 are 512-bit extensions to the 256-bit Advanced Vector Extensions SIMD instructions for x86 instruction set architecture (ISA) proposed by Intel in July 2013, and implemented in Intel’s Xeon Phi x200 (Knights Landing)[1] and Skylake-X CPUs; this includes the Core-X series[2] (excluding the Core i5-7640X and Core i7-7740X), as well as the new Xeon Scalable Processor Family and Xeon D-2100 Embedded Series.[3] AVX-512 consists of multiple extensions that may be implemented independently.[4] This policy is a departure from the historical requirement of implementing the entire instruction block. Only the core extension AVX-512F (AVX-512 Foundation) is required by all AVX-512 implementations.
Besides widening most 256-bit instructions, the extensions introduce various new operations, such as new data conversions, scatter operations, and permutations.[4] The number of AVX registers is increased from 16 to 32, and eight new «mask registers» are added, which allow for variable selection and blending of the results of instructions. In CPUs with the vector length (VL) extension—included in most AVX-512-capable processors (see § CPUs with AVX-512)—these instructions may also be used on the 128-bit and 256-bit vector sizes. AVX-512 is not the first 512-bit SIMD instruction set that Intel has introduced in processors: the earlier 512-bit SIMD instructions used in the first generation Xeon Phi coprocessors, derived from Intel’s Larrabee project, are similar but not binary compatible and only partially source compatible.[1]
Although AVX-512 remains available on newer Xeon chips, as of June 2023, the most recent Intel consumer chips to officially support it are from the Rocket Lake generation released in 2021.
Instruction set[edit]
The AVX-512 instruction set consists of several separate sets each having their own unique CPUID feature bit; however, they are typically grouped by the processor generation that implements them.
- F, CD, ER, PF
- Introduced with Xeon Phi x200 (Knights Landing) and Xeon Gold/Platinum (Skylake SP «Purley»), with the last two (ER and PF) being specific to Knights Landing.
- AVX-512 Foundation (F) – expands most 32-bit and 64-bit based AVX instructions with the EVEX coding scheme to support 512-bit registers, operation masks, parameter broadcasting, and embedded rounding and exception control, implemented by Knights Landing and Skylake Xeon
- AVX-512 Conflict Detection Instructions (CD) – efficient conflict detection to allow more loops to be vectorized, implemented by Knights Landing[1] and Skylake X
- AVX-512 Exponential and Reciprocal Instructions (ER) – exponential and reciprocal operations designed to help implement transcendental operations, implemented by Knights Landing[1]
- AVX-512 Prefetch Instructions (PF) – new prefetch capabilities, implemented by Knights Landing[1]
- VL, DQ, BW
- Introduced with Skylake X and Cannon Lake.
- AVX-512 Vector Length Extensions (VL) – extends most AVX-512 operations to also operate on XMM (128-bit) and YMM (256-bit) registers[5]
- AVX-512 Doubleword and Quadword Instructions (DQ) – adds new 32-bit and 64-bit AVX-512 instructions[5]
- AVX-512 Byte and Word Instructions (BW) – extends AVX-512 to cover 8-bit and 16-bit integer operations[5]
- IFMA, VBMI
- Introduced with Cannon Lake.[6]
- AVX-512 Integer Fused Multiply Add (IFMA) – fused multiply add of integers using 52-bit precision.
- AVX-512 Vector Byte Manipulation Instructions (VBMI) adds vector byte permutation instructions which were not present in AVX-512BW.
- 4VNNIW, 4FMAPS
- Introduced with Knights Mill.[7][8]
- AVX-512 Vector Neural Network Instructions Word variable precision (4VNNIW) – vector instructions for deep learning, enhanced word, variable precision.
- AVX-512 Fused Multiply Accumulation Packed Single precision (4FMAPS) – vector instructions for deep learning, floating point, single precision.
- VPOPCNTDQ
- Vector population count instruction. Introduced with Knights Mill and Ice Lake.[9]
- VNNI, VBMI2, BITALG
- Introduced with Ice Lake.[9]
- AVX-512 Vector Neural Network Instructions (VNNI) – vector instructions for deep learning.
- AVX-512 Vector Byte Manipulation Instructions 2 (VBMI2) – byte/word load, store and concatenation with shift.
- AVX-512 Bit Algorithms (BITALG) – byte/word bit manipulation instructions expanding VPOPCNTDQ.
- VP2INTERSECT
- Introduced with Tiger Lake.
- AVX-512 Vector Pair Intersection to a Pair of Mask Registers (VP2INTERSECT).
- GFNI, VPCLMULQDQ, VAES
- Introduced with Ice Lake.[9]
- These are not AVX-512 features per se. Together with AVX-512, they enable EVEX encoded versions of GFNI, PCLMULQDQ and AES instructions.
Encoding and features[edit]
The VEX prefix used by AVX and AVX2, while flexible, did not leave enough room for the features Intel wanted to add to AVX-512. This has led them to define a new prefix called EVEX.
Compared to VEX, EVEX adds the following benefits:[8]
- Expanded register encoding allowing 32 512-bit registers.
- Adds 8 new opmask registers for masking most AVX-512 instructions.
- Adds a new scalar memory mode that automatically performs a broadcast.
- Adds room for explicit rounding control in each instruction.
- Adds a new compressed displacement memory addressing mode.
The extended registers, SIMD width bit, and opmask registers of AVX-512 are mandatory and all require support from the OS.
SIMD modes[edit]
The AVX-512 instructions are designed to mix with 128/256-bit AVX/AVX2 instructions without a performance penalty. However, AVX-512VL extensions allows the use of AVX-512 instructions on 128/256-bit registers XMM/YMM, so most SSE and AVX/AVX2 instructions have new AVX-512 versions encoded with the EVEX prefix which allow access to new features such as opmask and additional registers. Unlike AVX-256, the new instructions do not have new mnemonics but share namespace with AVX, making the distinction between VEX and EVEX encoded versions of an instruction ambiguous in the source code. Since AVX-512F only works on 32- and 64-bit values, SSE and AVX/AVX2 instructions that operate on bytes or words are available only with the AVX-512BW extension (byte & word support).[8]
Extended registers[edit]
| 511 256 | 255 128 | 127 0 |
| ZMM0 | YMM0 | XMM0 |
| ZMM1 | YMM1 | XMM1 |
| ZMM2 | YMM2 | XMM2 |
| ZMM3 | YMM3 | XMM3 |
| ZMM4 | YMM4 | XMM4 |
| ZMM5 | YMM5 | XMM5 |
| ZMM6 | YMM6 | XMM6 |
| ZMM7 | YMM7 | XMM7 |
| ZMM8 | YMM8 | XMM8 |
| ZMM9 | YMM9 | XMM9 |
| ZMM10 | YMM10 | XMM10 |
| ZMM11 | YMM11 | XMM11 |
| ZMM12 | YMM12 | XMM12 |
| ZMM13 | YMM13 | XMM13 |
| ZMM14 | YMM14 | XMM14 |
| ZMM15 | YMM15 | XMM15 |
| ZMM16 | YMM16 | XMM16 |
| ZMM17 | YMM17 | XMM17 |
| ZMM18 | YMM18 | XMM18 |
| ZMM19 | YMM19 | XMM19 |
| ZMM20 | YMM20 | XMM20 |
| ZMM21 | YMM21 | XMM21 |
| ZMM22 | YMM22 | XMM22 |
| ZMM23 | YMM23 | XMM23 |
| ZMM24 | YMM24 | XMM24 |
| ZMM25 | YMM25 | XMM25 |
| ZMM26 | YMM26 | XMM26 |
| ZMM27 | YMM27 | XMM27 |
| ZMM28 | YMM28 | XMM28 |
| ZMM29 | YMM29 | XMM29 |
| ZMM30 | YMM30 | XMM30 |
| ZMM31 | YMM31 | XMM31 |
The width of the SIMD register file is increased from 256 bits to 512 bits, and expanded from 16 to a total of 32 registers ZMM0–ZMM31. These registers can be addressed as 256 bit YMM registers from AVX extensions and 128-bit XMM registers from Streaming SIMD Extensions, and legacy AVX and SSE instructions can be extended to operate on the 16 additional registers XMM16-XMM31 and YMM16-YMM31 when using EVEX encoded form.
Opmask registers[edit]
Most AVX-512 instructions may indicate one of 8 opmask registers (k0–k7). For instructions which use a mask register as an opmask, register ‘k0’ is special: a hardcoded constant used to indicate unmasked operations. For other operations, such as those that write to an opmask register or perform arithmetic or logical operations, ‘k0’ is a functioning, valid register. In most instructions, the opmask is used to control which values are written to the destination. A flag controls the opmask behavior, which can either be «zero», which zeros everything not selected by the mask, or «merge», which leaves everything not selected untouched. The merge behavior is identical to the blend instructions.
The opmask registers are normally 16 bits wide, but can be up to 64 bits with the AVX-512BW extension.[8] How many of the bits are actually used, though, depends on the vector type of the instructions masked. For the 32-bit single float or double words, 16 bits are used to mask the 16 elements in a 512-bit register. For double float and quad words, at most 8 mask bits are used.
The opmask register is the reason why several bitwise instructions which naturally have no element widths had them added in AVX-512. For instance, bitwise AND, OR or 128-bit shuffle now exist in both double-word and quad-word variants with the only difference being in the final masking.
New opmask instructions[edit]
The opmask registers have a new mini extension of instructions operating directly on them. Unlike the rest of the AVX-512 instructions, these instructions are all VEX encoded. The initial opmask instructions are all 16-bit (Word) versions. With AVX-512DQ 8-bit (Byte) versions were added to better match the needs of masking 8 64-bit values, and with AVX-512BW 32-bit (Double) and 64-bit (Quad) versions were added so they can mask up to 64 8-bit values. The instructions KORTEST and KTEST can be used to set the x86 flags based on mask registers, so that they may be used together with non-SIMD x86 branch and conditional instructions.
New instructions in AVX-512 foundation[edit]
Many AVX-512 instructions are simply EVEX versions of old SSE or AVX instructions. There are, however, several new instructions, and old instructions that have been replaced with new AVX-512 versions. The new or majorly reworked instructions are listed below. These foundation instructions also include the extensions from AVX-512VL and AVX-512BW since those extensions merely add new versions of these instructions instead of new instructions.
Blend using mask[edit]
There are no EVEX-prefixed versions of the blend instructions from SSE4; instead, AVX-512 has a new set of blending instructions using mask registers as selectors. Together with the general compare into mask instructions below, these may be used to implement generic ternary operations or cmov, similar to XOP’s VPCMOV.
Since blending is an integral part of the EVEX encoding, these instructions may also be considered basic move instructions. Using the zeroing blend mode, they can also be used as masking instructions.
Compare into mask[edit]
AVX-512F has four new compare instructions. Like their XOP counterparts they use the immediate field to select between 8 different comparisons. Unlike their XOP inspiration, however, they save the result to a mask register and initially only support doubleword and quadword comparisons. The AVX-512BW extension provides the byte and word versions. Note that two mask registers may be specified for the instructions, one to write to and one to declare regular masking.[8]
| Immediate | Comparison | Description |
|---|---|---|
| 0 | EQ | Equal |
| 1 | LT | Less than |
| 2 | LE | Less than or equal |
| 3 | FALSE | Set to zero |
| 4 | NEQ | Not equal |
| 5 | NLT | Greater than or equal |
| 6 | NLE | Greater than |
| 7 | TRUE | Set to one |
Logical set mask[edit]
The final way to set masks is using Logical Set Mask. These instructions perform either AND or NAND, and then set the destination opmask based on the result values being zero or non-zero. Note that like the comparison instructions, these take two opmask registers, one as destination and one a regular opmask.
| Instruction | Extension set | Description |
|---|---|---|
VPTESTMD, VPTESTMQ
|
F | Logical AND and set mask for 32 or 64 bit integers. |
VPTESTNMD, VPTESTNMQ
|
F | Logical NAND and set mask for 32 or 64 bit integers. |
VPTESTMB, VPTESTMW
|
BW | Logical AND and set mask for 8 or 16 bit integers. |
VPTESTNMB, VPTESTNMW
|
BW | Logical NAND and set mask for 8 or 16 bit integers. |
Compress and expand[edit]
The compress and expand instructions match the APL operations of the same name. They use the opmask in a slightly different way from other AVX-512 instructions. Compress only saves the values marked in the mask, but saves them compacted by skipping and not reserving space for unmarked values. Expand operates in the opposite way, by loading as many values as indicated in the mask and then spreading them to the selected positions.
| Instruction | Description |
|---|---|
VCOMPRESSPD, VCOMPRESSPS
|
Store sparse packed double/single-precision floating-point values into dense memory |
VPCOMPRESSD, VPCOMPRESSQ
|
Store sparse packed doubleword/quadword integer values into dense memory/register |
VEXPANDPD, VEXPANDPS
|
Load sparse packed double/single-precision floating-point values from dense memory |
VPEXPANDD, VPEXPANDQ
|
Load sparse packed doubleword/quadword integer values from dense memory/register |
Permute[edit]
A new set of permute instructions have been added for full two input permutations. They all take three arguments, two source registers and one index; the result is output by either overwriting the first source register or the index register. AVX-512BW extends the instructions to also include 16-bit (word) versions, and the AVX-512_VBMI extension defines the byte versions of the instructions.
| Instruction | Extension set | Description |
|---|---|---|
VPERMB
|
VBMI | Permute packed bytes elements. |
VPERMW
|
BW | Permute packed words elements. |
VPERMT2B
|
VBMI | Full byte permute overwriting first source. |
VPERMT2W
|
BW | Full word permute overwriting first source. |
VPERMI2PD, VPERMI2PS
|
F | Full single/double floating-point permute overwriting the index. |
VPERMI2D, VPERMI2Q
|
F | Full doubleword/quadword permute overwriting the index. |
VPERMI2B
|
VBMI | Full byte permute overwriting the index. |
VPERMI2W
|
BW | Full word permute overwriting the index. |
VPERMT2PS, VPERMT2PD
|
F | Full single/double floating-point permute overwriting first source. |
VPERMT2D, VPERMT2Q
|
F | Full doubleword/quadword permute overwriting first source. |
VSHUFF32x4, VSHUFF64x2, VSHUFI32x4, VSHUFI64x2
|
F | Shuffle four packed 128-bit lines. |
VPMULTISHIFTQB
|
VBMI | Select packed unaligned bytes from quadword sources. |
Bitwise ternary logic[edit]
Two new instructions added can logically implement all possible bitwise operations between three inputs. They take three registers as input and an 8-bit immediate field. Each bit in the output is generated using a lookup of the three corresponding bits in the inputs to select one of the 8 positions in the 8-bit immediate. Since only 8 combinations are possible using three bits, this allow all possible 3 input bitwise operations to be performed.[8]
These are the only bitwise vector instructions in AVX-512F; EVEX versions of the two source SSE and AVX bitwise vector instructions AND, ANDN, OR and XOR were added in AVX-512DQ.
The difference in the doubleword and quadword versions is only the application of the opmask.
| Instruction | Description |
|---|---|
VPTERNLOGD, VPTERNLOGQ
|
Bitwise Ternary Logic |
| A0 | A1 | A2 | Double AND (0x80) |
Double OR (0xFE) |
Bitwise blend (0xCA) |
|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 0 | 1 | 1 |
| 0 | 1 | 0 | 0 | 1 | 0 |
| 0 | 1 | 1 | 0 | 1 | 1 |
| 1 | 0 | 0 | 0 | 1 | 0 |
| 1 | 0 | 1 | 0 | 1 | 0 |
| 1 | 1 | 0 | 0 | 1 | 1 |
| 1 | 1 | 1 | 1 | 1 | 1 |
Conversions[edit]
A number of conversion or move instructions were added; these complete the set of conversion instructions available from SSE2.
| Instruction | Extension set | Description |
|---|---|---|
|
|
F | Down convert quadword or doubleword to doubleword, word or byte; unsaturated, saturated or saturated unsigned. The reverse of the sign/zero extend instructions from SSE4.1. |
VPMOVWB, VPMOVSWB, VPMOVUSWB
|
BW | Down convert word to byte; unsaturated, saturated or saturated unsigned. |
VCVTPS2UDQ, VCVTPD2UDQ, VCVTTPS2UDQ, VCVTTPD2UDQ
|
F | Convert with or without truncation, packed single or double-precision floating point to packed unsigned doubleword integers. |
VCVTSS2USI, VCVTSD2USI, VCVTTSS2USI, VCVTTSD2USI
|
F | Convert with or without truncation, scalar single or double-precision floating point to unsigned doubleword integer. |
VCVTPS2QQ, VCVTPD2QQ, VCVTPS2UQQ, VCVTPD2UQQ, VCVTTPS2QQ, VCVTTPD2QQ, VCVTTPS2UQQ, VCVTTPD2UQQ
|
DQ | Convert with or without truncation, packed single or double-precision floating point to packed signed or unsigned quadword integers. |
VCVTUDQ2PS, VCVTUDQ2PD
|
F | Convert packed unsigned doubleword integers to packed single or double-precision floating point. |
VCVTUSI2PS, VCVTUSI2PD
|
F | Convert scalar unsigned doubleword integers to single or double-precision floating point. |
VCVTUSI2SD, VCVTUSI2SS
|
F | Convert scalar unsigned integers to single or double-precision floating point. |
VCVTUQQ2PS, VCVTUQQ2PD
|
DQ | Convert packed unsigned quadword integers to packed single or double-precision floating point. |
VCVTQQ2PD, VCVTQQ2PS
|
F | Convert packed quadword integers to packed single or double-precision floating point. |
Floating-point decomposition[edit]
Among the unique new features in AVX-512F are instructions to decompose floating-point values and handle special floating-point values. Since these methods are completely new, they also exist in scalar versions.
| Instruction | Description |
|---|---|
VGETEXPPD, VGETEXPPS
|
Convert exponents of packed fp values into fp values |
VGETEXPSD, VGETEXPSS
|
Convert exponent of scalar fp value into fp value |
VGETMANTPD, VGETMANTPS
|
Extract vector of normalized mantissas from float32/float64 vector |
VGETMANTSD, VGETMANTSS
|
Extract float32/float64 of normalized mantissa from float32/float64 scalar |
VFIXUPIMMPD, VFIXUPIMMPS
|
Fix up special packed float32/float64 values |
VFIXUPIMMSD, VFIXUPIMMSS
|
Fix up special scalar float32/float64 value |
Floating-point arithmetic[edit]
This is the second set of new floating-point methods, which includes new scaling and approximate calculation of reciprocal, and reciprocal of square root. The approximate reciprocal instructions guarantee to have at most a relative error of 2−14.[8]
| Instruction | Description |
|---|---|
VRCP14PD, VRCP14PS
|
Compute approximate reciprocals of packed float32/float64 values |
VRCP14SD, VRCP14SS
|
Compute approximate reciprocals of scalar float32/float64 value |
VRNDSCALEPS, VRNDSCALEPD
|
Round packed float32/float64 values to include a given number of fraction bits |
VRNDSCALESS, VRNDSCALESD
|
Round scalar float32/float64 value to include a given number of fraction bits |
VRSQRT14PD, VRSQRT14PS
|
Compute approximate reciprocals of square roots of packed float32/float64 values |
VRSQRT14SD, VRSQRT14SS
|
Compute approximate reciprocal of square root of scalar float32/float64 value |
VSCALEFPS, VSCALEFPD
|
Scale packed float32/float64 values with float32/float64 values |
VSCALEFSS, VSCALEFSD
|
Scale scalar float32/float64 value with float32/float64 value |
Broadcast[edit]
| Instruction | Extension set | Description |
|---|---|---|
VBROADCASTSS, VBROADCASTSD
|
F, VL | Broadcast single/double floating-point value |
VPBROADCASTB, VPBROADCASTW, VPBROADCASTD, VPBROADCASTQ
|
F, VL, DQ, BW | Broadcast a byte/word/doubleword/quadword integer value |
VBROADCASTI32X2, VBROADCASTI64X2, VBROADCASTI32X4, VBROADCASTI32X8, VBROADCASTI64X4
|
F, VL, DQ, BW | Broadcast two or four doubleword/quadword integer values |
Miscellaneous[edit]
| Instruction | Extension set | Description |
|---|---|---|
VALIGND, VALIGNQ
|
F, VL | Align doubleword or quadword vectors |
VDBPSADBW
|
BW | Double block packed sum-absolute-differences (SAD) on unsigned bytes |
VPABSQ
|
F | Packed absolute value quadword |
VPMAXSQ, VPMAXUQ
|
F | Maximum of packed signed/unsigned quadword |
VPMINSQ, VPMINUQ
|
F | Minimum of packed signed/unsigned quadword |
VPROLD, VPROLVD, VPROLQ, VPROLVQ, VPRORD, VPRORVD, VPRORQ, VPRORVQ
|
F | Bit rotate left or right |
VPSCATTERDD, VPSCATTERDQ, VPSCATTERQD, VPSCATTERQQ
|
F | Scatter packed doubleword/quadword with signed doubleword and quadword indices |
VSCATTERDPS, VSCATTERDPD, VSCATTERQPS, VSCATTERQPD
|
F | Scatter packed float32/float64 with signed doubleword and quadword indices |
New instructions by sets[edit]
Conflict detection[edit]
The instructions in AVX-512 conflict detection (AVX-512CD) are designed to help efficiently calculate conflict-free subsets of elements in loops that normally could not be safely vectorized.[10]
| Instruction | Name | Description |
|---|---|---|
VPCONFLICTD, VPCONFLICTQ
|
Detect conflicts within vector of packed double- or quadwords values | Compares each element in the first source, to all elements on same or earlier places in the second source and forms a bit vector of the results |
VPLZCNTD, VPLZCNTQ
|
Count the number of leading zero bits for packed double- or quadword values | Vectorized LZCNT instruction
|
VPBROADCASTMB2Q, VPBROADCASTMW2D
|
Broadcast mask to vector register | Either 8-bit mask to quadword vector, or 16-bit mask to doubleword vector |
Exponential and reciprocal[edit]
AVX-512 exponential and reciprocal (AVX-512ER) instructions contain more accurate approximate reciprocal instructions than those in the AVX-512 foundation; relative error is at most 2−28. They also contain two new exponential functions that have a relative error of at most 2−23.[8]
| Instruction | Description |
|---|---|
VEXP2PD, VEXP2PS
|
Compute approximate exponential 2^x of packed single or double-precision floating-point values |
VRCP28PD, VRCP28PS
|
Compute approximate reciprocals of packed single or double-precision floating-point values |
VRCP28SD, VRCP28SS
|
Compute approximate reciprocal of scalar single or double-precision floating-point value |
VRSQRT28PD, VRSQRT28PS
|
Compute approximate reciprocals of square roots of packed single or double-precision floating-point values |
VRSQRT28SD, VRSQRT28SS
|
Compute approximate reciprocal of square root of scalar single or double-precision floating-point value |
Prefetch[edit]
AVX-512 prefetch (AVX-512PF) instructions contain new prefetch operations for the new scatter and gather functionality introduced in AVX2 and AVX-512. T0 prefetch means prefetching into level 1 cache and T1 means prefetching into level 2 cache.
| Instruction | Description |
|---|---|
VGATHERPF0DPS, VGATHERPF0QPS, VGATHERPF0DPD, VGATHERPF0QPD
|
Using signed dword/qword indices, prefetch sparse byte memory locations containing single/double-precision data using opmask k1 and T0 hint. |
VGATHERPF1DPS, VGATHERPF1QPS, VGATHERPF1DPD, VGATHERPF1QPD
|
Using signed dword/qword indices, prefetch sparse byte memory locations containing single/double-precision data using opmask k1 and T1 hint. |
VSCATTERPF0DPS, VSCATTERPF0QPS, VSCATTERPF0DPD, VSCATTERPF0QPD
|
Using signed dword/qword indices, prefetch sparse byte memory locations containing single/double-precision data using writemask k1 and T0 hint with intent to write. |
VSCATTERPF1DPS, VSCATTERPF1QPS, VSCATTERPF1DPD, VSCATTERPF1QPD
|
Using signed dword/qword indices, prefetch sparse byte memory locations containing single/double precision data using writemask k1 and T1 hint with intent to write. |
4FMAPS and 4VNNIW[edit]
The two sets of instructions perform multiple iterations of processing. They are generally only found in Xeon Phi products.
| Instruction | Extension set | Description |
|---|---|---|
V4FMADDPS, V4FMADDSS
|
4FMAPS | Packed/scalar single-precision floating-point fused multiply-add (4-iterations) |
V4FNMADDPS, V4FNMADDSS
|
4FMAPS | Packed/scalar single-precision floating-point fused multiply-add and negate (4-iterations) |
VP4DPWSSD
|
4VNNIW | Dot product of signed words with double word accumulation (4-iterations) |
VP4DPWSSDS
|
4VNNIW | Dot product of signed words with double word accumulation and saturation (4-iterations) |
BW, DQ and VBMI[edit]
AVX-512DQ adds new doubleword and quadword instructions. AVX-512BW adds byte and words versions of the same instructions, and adds byte and word version of doubleword/quadword instructions in AVX-512F. A few instructions which get only word forms with AVX-512BW acquire byte forms with the AVX-512_VBMI extension (VPERMB, VPERMI2B, VPERMT2B, VPMULTISHIFTQB).
Two new instructions were added to the mask instructions set: KADD and KTEST (B and W forms with AVX-512DQ, D and Q with AVX-512BW). The rest of mask instructions, which had only word forms, got byte forms with AVX-512DQ and doubleword/quadword forms with AVX-512BW. KUNPCKBW was extended to KUNPCKWD and KUNPCKDQ by AVX-512BW.
Among the instructions added by AVX-512DQ are several SSE and AVX instructions that didn’t get AVX-512 versions with AVX-512F, among those are all the two input bitwise instructions and extract/insert integer instructions.
Instructions that are completely new are covered below.
Floating-point instructions[edit]
Three new floating-point operations are introduced. Since they are not only new to AVX-512 they have both packed/SIMD and scalar versions.
The VFPCLASS instructions tests if the floating-point value is one of eight special floating-point values, which of the eight values will trigger a bit in the output mask register is controlled by the immediate field. The VRANGE instructions perform minimum or maximum operations depending on the value of the immediate field, which can also control if the operation is done absolute or not and separately how the sign is handled. The VREDUCE instructions operate on a single source, and subtract from that the integer part of the source value plus a number of bits specified in the immediate field of its fraction.
| Instruction | Extension set | Description |
|---|---|---|
VFPCLASSPS, VFPCLASSPD
|
DQ | Test types of packed single and double precision floating-point values. |
VFPCLASSSS, VFPCLASSSD
|
DQ | Test types of scalar single and double precision floating-point values. |
VRANGEPS, VRANGEPD
|
DQ | Range restriction calculation for packed floating-point values. |
VRANGESS, VRANGESD
|
DQ | Range restriction calculation for scalar floating-point values. |
VREDUCEPS, VREDUCEPD
|
DQ | Perform reduction transformation on packed floating-point values. |
VREDUCESS, VREDUCESD
|
DQ | Perform reduction transformation on scalar floating-point values. |
Other instructions[edit]
| Instruction | Extension set | Description |
|---|---|---|
VPMOVM2D, VPMOVM2Q
|
DQ | Convert mask register to double- or quad-word vector register. |
VPMOVM2B, VPMOVM2W
|
BW | Convert mask register to byte or word vector register. |
VPMOVD2M, VPMOVQ2M
|
DQ | Convert double- or quad-word vector register to mask register. |
VPMOVB2M, VPMOVW2M
|
BW | Convert byte or word vector register to mask register. |
VPMULLQ
|
DQ | Multiply packed quadword store low result. A quadword version of VPMULLD. |
VBMI2[edit]
Extend VPCOMPRESS and VPEXPAND with byte and word variants. Shift instructions are new.
| Instruction | Description |
|---|---|
VPCOMPRESSB, VPCOMPRESSW
|
Store sparse packed byte/word integer values into dense memory/register |
VPEXPANDB, VPEXPANDW
|
Load sparse packed byte/word integer values from dense memory/register |
VPSHLD
|
Concatenate and shift packed data left logical |
VPSHLDV
|
Concatenate and variable shift packed data left logical |
VPSHRD
|
Concatenate and shift packed data right logical |
VPSHRDV
|
Concatenate and variable shift packed data right logical |
VNNI[edit]
VNNI stands for Vector Neural Network Instructions.[11] AVX512-VNNI adds EVEX-coded instructions described below. With AVX-512F, these instructions can operate on 512-bit vectors, and AVX-512VL further adds support for 128- and 256-bit vectors.
A later AVX-VNNI extension adds VEX encodings of these instructions which can only operate on 128- or 256-bit vectors. AVX-VNNI is not part of the AVX-512 suite, it does not require AVX-512F and can be implemented independently.
| Instruction | Description |
|---|---|
VPDPBUSD
|
Multiply and add unsigned and signed bytes |
VPDPBUSDS
|
Multiply and add unsigned and signed bytes with saturation |
VPDPWSSD
|
Multiply and add signed word integers |
VPDPWSSDS
|
Multiply and add word integers with saturation |
IFMA[edit]
| Instruction | Extension set | Description |
|---|---|---|
VPMADD52LUQ
|
IFMA | Packed multiply of unsigned 52-bit integers and add the low 52-bit products to qword accumulators |
VPMADD52HUQ
|
IFMA | Packed multiply of unsigned 52-bit integers and add the high 52-bit products to 64-bit accumulators |
VPOPCNTDQ and BITALG[edit]
| Instruction | Extension set | Description |
|---|---|---|
VPOPCNTD, VPOPCNTQ
|
VPOPCNTDQ | Return the number of bits set to 1 in doubleword/quadword |
VPOPCNTB, VPOPCNTW
|
BITALG | Return the number of bits set to 1 in byte/word |
VPSHUFBITQMB
|
BITALG | Shuffle bits from quadword elements using byte indexes into mask |
VP2INTERSECT[edit]
| Instruction | Extension set | Description |
|---|---|---|
VP2INTERSECTD, VP2INTERSECTQ
|
VP2INTERSECT | Compute intersection between doublewords/quadwords to a pair of mask registers |
GFNI[edit]
EVEX-encoded Galois field new instructions:
| Instruction | Description |
|---|---|
VGF2P8AFFINEINVQB
|
Galois field affine transformation inverse |
VGF2P8AFFINEQB
|
Galois field affine transformation |
VGF2P8MULB
|
Galois field multiply bytes |
VPCLMULQDQ[edit]
VPCLMULQDQ with AVX-512F adds an EVEX-encoded 512-bit version of the PCLMULQDQ instruction. With AVX-512VL, it adds EVEX-encoded 256- and 128-bit versions. VPCLMULQDQ alone (that is, on non-AVX512 CPUs) adds only VEX-encoded 256-bit version. (Availability of the VEX-encoded 128-bit version is indicated by different CPUID bits: PCLMULQDQ and AVX.) The wider than 128-bit variations of the instruction perform the same operation on each 128-bit portion of input registers, but they do not extend it to select quadwords from different 128-bit fields (the meaning of imm8 operand is the same: either low or high quadword of the 128-bit field is selected).
| Instruction | Description |
|---|---|
VPCLMULQDQ
|
Carry-less multiplication quadword |
VAES[edit]
VEX- and EVEX-encoded AES instructions. The wider than 128-bit variations of the instruction perform the same operation on each 128-bit portion of input registers. The VEX versions can be used without AVX-512 support.
| Instruction | Description |
|---|---|
VAESDEC
|
Perform one round of an AES decryption flow |
VAESDECLAST
|
Perform last round of an AES decryption flow |
VAESENC
|
Perform one round of an AES encryption flow |
VAESENCLAST
|
Perform last round of an AES encryption flow |
BF16[edit]
AI acceleration instructions operating on the Bfloat16 numbers.
| Instruction | Description |
|---|---|
VCVTNE2PS2BF16
|
Convert two vectors of packed single precision numbers into one vector of packed Bfloat16 numbers |
VCVTNEPS2BF16
|
Convert one vector of packed single precision numbers to one vector of packed Bfloat16 numbers |
VDPBF16PS
|
Calculate dot product of two Bfloat16 pairs and accumulate the result into one packed single precision number |
FP16[edit]
An extension of the earlier F16C instruction set, adding comprehensive support for the binary16 floating-point numbers (also known as FP16, float16 or half-precision floating-point numbers). The new instructions implement most operations that were previously available for single and double-precision floating-point numbers and also introduce new complex number instructions and conversion instructions. Scalar and packed operations are supported.
Unlike the single and double-precision format instructions, the half-precision operands are neither conditionally flushed to zero (FTZ) nor conditionally treated as zero (DAZ) based on MXCSR settings. Subnormal values are processed at full speed by hardware to facilitate using the full dynamic range of the FP16 numbers. Instructions that create FP32 and FP64 numbers still respect the MXCSR.FTZ bit.[12]
Arithmetic instructions[edit]
| Instruction | Description |
|---|---|
VADDPH, VADDSH
|
Add packed/scalar FP16 numbers. |
VSUBPH, VSUBSH
|
Subtract packed/scalar FP16 numbers. |
VMULPH, VMULSH
|
Multiply packed/scalar FP16 numbers. |
VDIVPH, VDIVSH
|
Divide packed/scalar FP16 numbers. |
VSQRTPH, VSQRTSH
|
Compute square root of packed/scalar FP16 numbers. |
VFMADD{132, 213, 231}PH, VFMADD{132, 213, 231}SH
|
Multiply-add packed/scalar FP16 numbers. |
VFNMADD{132, 213, 231}PH, VFNMADD{132, 213, 231}SH
|
Negated multiply-add packed/scalar FP16 numbers. |
VFMSUB{132, 213, 231}PH, VFMSUB{132, 213, 231}SH
|
Multiply-subtract packed/scalar FP16 numbers. |
VFNMSUB{132, 213, 231}PH, VFNMSUB{132, 213, 231}SH
|
Negated multiply-subtract packed/scalar FP16 numbers. |
VFMADDSUB{132, 213, 231}PH
|
Multiply-add (odd vector elements) or multiply-subtract (even vector elements) packed FP16 numbers. |
VFMSUBADD{132, 213, 231}PH
|
Multiply-subtract (odd vector elements) or multiply-add (even vector elements) packed FP16 numbers. |
VREDUCEPH, VREDUCESH
|
Perform reduction transformation of the packed/scalar FP16 numbers. |
VRNDSCALEPH, VRNDSCALESH
|
Round packed/scalar FP16 numbers to a given number of fraction bits. |
VSCALEFPH, VSCALEFSH
|
Scale packed/scalar FP16 numbers by multiplying it by a power of two. |
Complex arithmetic instructions[edit]
| Instruction | Description |
|---|---|
VFMULCPH, VFMULCSH
|
Multiply packed/scalar complex FP16 numbers. |
VFCMULCPH, VFCMULCSH
|
Multiply packed/scalar complex FP16 numbers. Complex conjugate form of the operation. |
VFMADDCPH, VFMADDCSH
|
Multiply-add packed/scalar complex FP16 numbers. |
VFCMADDCPH, VFCMADDCSH
|
Multiply-add packed/scalar complex FP16 numbers. Complex conjugate form of the operation. |
Approximate reciprocal instructions[edit]
| Instruction | Description |
|---|---|
VRCPPH, VRCPSH
|
Compute approximate reciprocal of the packed/scalar FP16 numbers. The maximum relative error of the approximation is less than 2−11+2−14. |
VRSQRTPH, VRSQRTSH
|
Compute approximate reciprocal square root of the packed/scalar FP16 numbers. The maximum relative error of the approximation is less than 2−14. |
Comparison instructions[edit]
| Instruction | Description |
|---|---|
VCMPPH, VCMPSH
|
Compare the packed/scalar FP16 numbers and store the result in a mask register. |
VCOMISH
|
Compare the scalar FP16 numbers and store the result in the flags register. Signals an exception if a source operand is QNaN or SNaN. |
VUCOMISH
|
Compare the scalar FP16 numbers and store the result in the flags register. Signals an exception only if a source operand is SNaN. |
VMAXPH, VMAXSH
|
Select the maximum of each vertical pair of the source packed/scalar FP16 numbers. |
VMINPH, VMINSH
|
Select the minimum of each vertical pair of the source packed/scalar FP16 numbers. |
VFPCLASSPH, VFPCLASSSH
|
Test packed/scalar FP16 numbers for special categories (NaN, infinity, negative zero, etc.) and store the result in a mask register. |
Conversion instructions[edit]
| Instruction | Description |
|---|---|
VCVTW2PH
|
Convert packed signed 16-bit integers to FP16 numbers. |
VCVTUW2PH
|
Convert packed unsigned 16-bit integers to FP16 numbers. |
VCVTDQ2PH
|
Convert packed signed 32-bit integers to FP16 numbers. |
VCVTUDQ2PH
|
Convert packed unsigned 32-bit integers to FP16 numbers. |
VCVTQQ2PH
|
Convert packed signed 64-bit integers to FP16 numbers. |
VCVTUQQ2PH
|
Convert packed unsigned 64-bit integers to FP16 numbers. |
VCVTPS2PHX
|
Convert packed FP32 numbers to FP16 numbers. Unlike VCVTPS2PH from F16C, VCVTPS2PHX has a different encoding that also supports broadcasting.
|
VCVTPD2PH
|
Convert packed FP64 numbers to FP16 numbers. |
VCVTSI2SH
|
Convert a scalar signed 32-bit or 64-bit integer to FP16 number. |
VCVTUSI2SH
|
Convert a scalar unsigned 32-bit or 64-bit integer to FP16 number. |
VCVTSS2SH
|
Convert a scalar FP32 number to FP16 number. |
VCVTSD2SH
|
Convert a scalar FP64 number to FP16 number. |
VCVTPH2W, VCVTTPH2W
|
Convert packed FP16 numbers to signed 16-bit integers. VCVTPH2W rounds the value according to the MXCSR register. VCVTTPH2W rounds toward zero.
|
VCVTPH2UW, VCVTTPH2UW
|
Convert packed FP16 numbers to unsigned 16-bit integers. VCVTPH2UW rounds the value according to the MXCSR register. VCVTTPH2UW rounds toward zero.
|
VCVTPH2DQ, VCVTTPH2DQ
|
Convert packed FP16 numbers to signed 32-bit integers. VCVTPH2DQ rounds the value according to the MXCSR register. VCVTTPH2DQ rounds toward zero.
|
VCVTPH2UDQ, VCVTTPH2UDQ
|
Convert packed FP16 numbers to unsigned 32-bit integers. VCVTPH2UDQ rounds the value according to the MXCSR register. VCVTTPH2UDQ rounds toward zero.
|
VCVTPH2QQ, VCVTTPH2QQ
|
Convert packed FP16 numbers to signed 64-bit integers. VCVTPH2QQ rounds the value according to the MXCSR register. VCVTTPH2QQ rounds toward zero.
|
VCVTPH2UQQ, VCVTTPH2UQQ
|
Convert packed FP16 numbers to unsigned 64-bit integers. VCVTPH2UQQ rounds the value according to the MXCSR register. VCVTTPH2UQQ rounds toward zero.
|
VCVTPH2PSX
|
Convert packed FP16 numbers to FP32 numbers. Unlike VCVTPH2PS from F16C, VCVTPH2PSX has a different encoding that also supports broadcasting.
|
VCVTPH2PD
|
Convert packed FP16 numbers to FP64 numbers. |
VCVTSH2SI, VCVTTSH2SI
|
Convert a scalar FP16 number to signed 32-bit or 64-bit integer. VCVTSH2SI rounds the value according to the MXCSR register. VCVTTSH2SI rounds toward zero.
|
VCVTSH2USI, VCVTTSH2USI
|
Convert a scalar FP16 number to unsigned 32-bit or 64-bit integer. VCVTSH2USI rounds the value according to the MXCSR register. VCVTTSH2USI rounds toward zero.
|
VCVTSH2SS
|
Convert a scalar FP16 number to FP32 number. |
VCVTSH2SD
|
Convert a scalar FP16 number to FP64 number. |
Decomposition instructions[edit]
| Instruction | Description |
|---|---|
VGETEXPPH, VGETEXPSH
|
Extract exponent components of packed/scalar FP16 numbers as FP16 numbers. |
VGETMANTPH, VGETMANTSH
|
Extract mantissa components of packed/scalar FP16 numbers as FP16 numbers. |
Move instructions[edit]
| Instruction | Description |
|---|---|
VMOVSH
|
Move scalar FP16 number to/from memory or between vector registers. |
VMOVW
|
Move scalar FP16 number to/from memory or general purpose register. |
Legacy instructions with EVEX-encoded versions[edit]
CPUs with AVX-512[edit]
- Intel
- Knights Landing (Xeon Phi x200):[1][13] AVX-512 F, CD, ER, PF
- Knights Mill (Xeon Phi x205):[9] AVX-512 F, CD, ER, PF, 4FMAPS, 4VNNIW, VPOPCNTDQ
- Skylake-SP, Skylake-X:[14][15][16] AVX-512 F, CD, VL, DQ, BW
- Cannon Lake:[9] AVX-512 F, CD, VL, DQ, BW, IFMA, VBMI
- Cascade Lake: AVX-512 F, CD, VL, DQ, BW, VNNI
- Cooper Lake: AVX-512 F, CD, VL, DQ, BW, VNNI, BF16
- Ice Lake,[9] Rocket Lake:[17][18] AVX-512 F, CD, VL, DQ, BW, IFMA, VBMI, VBMI2, VPOPCNTDQ, BITALG, VNNI, VPCLMULQDQ, GFNI, VAES
- Tiger Lake (except Pentium and Celeron but some reviewer have the CPU-Z Screenshot of Celeron 6305 with AVX-512 support[19][20]):[21] AVX-512 F, CD, VL, DQ, BW, IFMA, VBMI, VBMI2, VPOPCNTDQ, BITALG, VNNI, VPCLMULQDQ, GFNI, VAES, VP2INTERSECT
- Alder Lake (never officially supported by Intel, completely removed in newer CPUsNote 1):[22][23] AVX-512 F, CD, VL, DQ, BW, IFMA, VBMI, VBMI2, VPOPCNTDQ, BITALG, VNNI, VPCLMULQDQ, GFNI, VAES, BF16, VP2INTERSECT, FP16
- Sapphire Rapids:[24] AVX-512 F, CD, VL, DQ, BW, IFMA, VBMI, VBMI2, VPOPCNTDQ, BITALG, VNNI, VPCLMULQDQ, GFNI, VAES, BF16, FP16
- Centaur Technology
- «CNS» core (8c/8t):[25][26] AVX-512 F, CD, VL, DQ, BW, IFMA, VBMI
- AMD
- Zen 4:[27][28][29][30][31] AVX-512 F, CD, VL, DQ, BW, IFMA, VBMI, VBMI2, VPOPCNTDQ, BITALG, VNNI, VPCLMULQDQ, GFNI, VAES, BF16
^Note 1 : Intel does not officially support AVX-512 family of instructions on the Alder Lake microprocessors. Intel has disabled in silicon (fused off) AVX-512 on recent steppings of Alder Lake microprocessors to prevent customers from enabling AVX-512.[32]
In older Alder Lake family CPUs with some legacy combinations of BIOS and microcode revisions, it was possible to execute AVX-512 family instructions when disabling all the efficiency cores which do not contain the silicon for AVX-512.[33][34][22]
Performance[edit]
Intel Vectorization Advisor (starting from version 2017) supports native AVX-512 performance and vector code quality analysis (for «Core», Xeon and Intel Xeon Phi processors). Along with traditional hotspots profile, Advisor Recommendations and «seamless» integration of Intel Compiler vectorization diagnostics, Advisor Survey analysis also provides AVX-512 ISA metrics and new AVX-512-specific «traits», e.g. Scatter, Compress/Expand, mask utilization.[35][36]
On some processors (mostly pre-Ice Lake Intel), AVX-512 instructions can cause a frequency throttling even greater than its predecessors, causing a penalty for mixed workloads. The additional downclocking is triggered by the 512-bit width of vectors and depend on the nature of instructions being executed, and using the 128 or 256-bit part of AVX-512 (AVX-512VL) does not trigger it. As a result, gcc and clang default to prefer using the 256-bit vectors for Intel targets.[37][38][39]
See also[edit]
- FMA instruction set (FMA)
- XOP instruction set (XOP)
- Scalable Vector Extension for ARM – a new vector instruction set (supplementing VFP and NEON) supporting very wide bit-widths, and single binary code that can adapt automatically to maximum width supported by hardware.
References[edit]
- Kusswurm, Daniel (2022). Modern parallel programming with C++ and Assembly language : X86 SIMD development using AVX, AVX2, and AVX-512. [United States]. ISBN 978-1-4842-7918-2. OCLC 1304243196.
- ^ a b c d e f James Reinders (23 July 2013). «AVX-512 Instructions». Intel. Retrieved 20 August 2013.
- ^ «Intel® Core™ X-Series Processor Family». Retrieved 2022-11-30.
- ^ «Advanced Intelligence for High-Density Edge Solutions». Intel. Intel. Retrieved 8 February 2018.
- ^ a b Kusswurm 2022, p. 223.
- ^ a b c James Reinders (17 July 2014). «Additional AVX-512 instructions». Intel. Retrieved 3 August 2014.
- ^ Anton Shilov. «Intel ‘Skylake’ processors for PCs will not support AVX-512 instructions». Kitguru.net. Retrieved 2015-03-17.
- ^ «Intel will add deep-learning instructions to its processors». 14 October 2016.
- ^ a b c d e f g h «Intel Architecture Instruction Set Extensions Programming Reference» (PDF). Intel. Retrieved 2014-01-29.
- ^ a b c d e f «Intel Architecture Instruction Set Extensions and Future Features Programming Reference». Intel. Retrieved 2017-10-16.
- ^ «AVX-512 Architecture/Demikhovsky Poster» (PDF). Intel. Retrieved 25 February 2014.
- ^ «Intel® Deep Learning Boost» (PDF). Intel. Retrieved 2021-10-11.
- ^ «Intel® AVX512-FP16 Architecture Specification, June 2021, Revision 1.0, Ref. 347407-001US» (PDF). Intel. 2021-06-30. Retrieved 2021-07-04.
- ^ «Intel Xeon Phi Processor product brief». Intel. Retrieved 12 October 2016.
- ^ «Intel unveils X-series platform: Up to 18 cores and 36 threads, from $242 to $2,000». Ars Technica. Retrieved 2017-05-30.
- ^ «Intel Advanced Vector Extensions 2015/2016: Support in GNU Compiler Collection» (PDF). Gcc.gnu.org. Retrieved 2016-10-20.
- ^ Patrizio, Andy (21 September 2015). «Intel’s Xeon roadmap for 2016 leaks». Itworld.org. Retrieved 2016-10-20.
- ^ «Intel Core i9-11900K Review — World’s Fastest Gaming Processor?». www.techpowerup.com.
- ^ ««Add rocketlake to gcc» commit». gcc.gnu.org.
- ^ «Intel Celeron 6305 Processor (4M Cache, 1.80 GHz, with IPU) Product Specifications». ark.intel.com. Archived from the original on 2020-10-18. Retrieved 2020-11-10.
- ^ Laptop Murah Kinerja Boleh Diadu | HP 14S DQ2518TU, retrieved 2021-08-08
- ^ «Using the GNU Compiler Collection (GCC): x86 Options». GNU. Retrieved 2019-10-14.
- ^ a b Cutress, Ian; Frumusanu, Andrei. «The Intel 12th Gen Core i9-12900K Review: Hybrid Performance Brings Hybrid Complexity». www.anandtech.com. Retrieved 5 November 2021.
- ^ Larabel, Michael. «Intel Core i9 12900K «Alder Lake» AVX-512 On Linux». www.phoronix.com. Retrieved 2021-11-08.
- ^ Larabel, Michael. «AVX-512 Performance Comparison: AMD Genoa vs. Intel Sapphire Rapids & Ice Lake». www.phoronix.com. Retrieved 2023-01-19.
- ^ «The industry’s first high-performance x86 SOC with server-class CPUs and integrated AI coprocessor technology». 2 August 2022. Archived from the original on December 12, 2019.
{{cite web}}: CS1 maint: unfit URL (link) - ^ «x86, x64 Instruction Latency, Memory Latency and CPUID dumps (instlatx64)». users.atw.hu.
- ^ «AMD Zen 4 Based Ryzen CPUs May Feature Up to 24 Cores, Support for AVX512 Vectors». Hardware Times. 2021-05-23. Retrieved 2021-09-02.
- ^ Hagedoorn, Hilbert. «AMD working on a prodigious 96-core EPYC processor». Guru3D.com. Retrieved 2021-05-25.
- ^ clamchowder (2021-08-23). «Details on the Gigabyte Leak». Chips And Cheese. Retrieved 2022-06-10.
- ^ W1zzard. «AMD Answers Our Zen 4 Tech Questions, with Robert Hallock». TechPowerUp. Retrieved 2022-05-29.
- ^ Larabel, Michael (2022-09-26). «AMD Zen 4 AVX-512 Performance Analysis On The Ryzen 9 7950X». www.phoronix.com.
- ^ Alcorn, Paul (2022-03-02). «Intel Nukes Alder Lake’s AVX-512 Support, Now Fuses It Off in Silicon». Tom’s Hardware. Retrieved 2022-03-07.
- ^ Cutress, Ian; Frumusanu, Andrei (2021-08-19). «Intel Architecture Day 2021: Alder Lake, Golden Cove, and Gracemont Detailed». AnandTech. Retrieved 2021-08-25.
- ^ Alcorn, Paul (2021-08-19). «Intel Architecture Day 2021: Alder Lake Chips, Golden Cove and Gracemont Cores». Tom’s Hardware. Retrieved 2021-08-21.
- ^ «Intel Advisor XE 2016 Update 3 What’s new — Intel Software». Software.intel.com. Retrieved 2016-10-20.
- ^ «Intel Advisor — Intel Software». Software.intel.com. Retrieved 2016-10-20.
- ^ Cordes, Peter. «SIMD instructions lowering CPU frequency». Stack Overflow.
- ^ Cordes, Peter. «why does gcc auto-vectorization for tigerlake use ymm not zmm registers». Stack Overflow.
- ^ «LLVM 10.0.0 Release Notes».

Блоки векторных инструкций AVX-512 на процессоре Core i9-12900K
Всем производителям материнских плат Z690 на процессорах Alder Lake пришло обновление микрокода от Intel, которое полностью запрещает использование инструкций AVX-512.
Физически модуль AVX-512 остался на ядрах P. Его можно было активировать через BIOS и повысить производительность в 14–32 раза в некоторых специфических задачах, отключив при этом малополезные ядра E. Теперь лазейку закрыли.
Таким образом Intel окончательно убрала официальную поддержку AVX-512 из новых процессоров 12-го поколения Alder Lake. Изначально предполагалось, что этот модуль физически убрали с микросхемы, потому что он занимает много места. Но потом выяснилось, что блоки остались на месте, но только в производительных ядрах P.
Обновление микрокода пришло производителям буквально за несколько дней до начала выставки CES 2022, где Intel собирается представить ряд младших процессоров в семействе Alder Lake. Естественно, все они работают на материнских платах с чипсетом Z690. И вот теперь компания решила окончательно закрыть вопрос с поддержкой AVX-512.
Набор инструкций AVX-512 расширяет систему команд AVX до векторов длиной 512 бит при помощи кодировки с префиксом EVEX. Расширение AVX-512 вводит 32 векторных регистра (ZMM), каждый по 512 бит, 8 регистров масок, 512-разрядные упакованные форматы для целых и дробных чисел и операции над ними, тонкое управление режимами округления (позволяет переопределить глобальные настройки), операции broadcast (рассылка информации из одного элемента регистра в другие), подавление ошибок в операциях с дробными числами, операции gather/scatter (сборка и рассылка элементов векторного регистра в/из нескольких адресов памяти), быстрые математические операции, компактное кодирование больших смещений. Блок AVX-512 реализован в следующих процессорах: Intel Xeon Phi x200 и x205 (в сопроцессорах Knights Landing и Knights Mill), а также в семействах Skylake-SP, Skylake-X, Cannon Lake, Cascade Lake, Cooper Lake, Ice Lake, Rocket Lake, Tiger Lake, Sapphire Rapids.
Причины отключения AVX-512
Официально причины не разглашаются. Мы можем только предполагать. Дело в том, что единственным условием для активации AVX-512 является отключение ядер E. При этом во многих задачах такая замена (AVX-512 вместо ядер E) практически не отражается на производительности или даже улучшает её.

Отключение ядер E практически не отражается на производительности после активации AVX-512
Другая причина: усложнение настроек с отключением/включением ядер создаёт дополнительную нагрузку на службу технической поддержки Intel.
Наконец, самое главное. Программное отключение AVX-512 в десктопных процессорах создаёт дополнительный спрос на процессоры для рабочих станций и серверов, где набор инструкций будет работать как положено. В данном случае компании совершенно не нужно, чтобы коммерческие клиенты использовали более дешёвые настольные процессоры.
В проигрыше остаются пользователи, которые хотели воспользоваться преимуществами AVX-512 именно на последнем поколении настольных процессоров Intel. Теперь им остаётся использовать другие процессоры с поддержкой AVX-512, то есть все предыдущие поколения Intel или будущее поколение AMD Ryzen, которое выйдет очень скоро.
Искусственная рыночная сегментация и распределение пользователей по секторам рынка с разной рентабельностью — известный приём, который позволяет максимизировать прибыль. Им пользуются очень многие компании, которые выпускают примерно одинаковые товары, но для разных рыночных сегментов и по разным ценам.
Intel многократно использовала этот приём. Говорят, в первых семи поколениях Core специально не выпускались настольные процессоры более чем с четырьмя ядрами, чтобы не повредить более прибыльному серверному сегменту.
Выпуск одинаковых процессоров в «залоченной» и «разлоченной» версиях, с отключенными/включенными ядрами и т. д. — это стандартный арсенал грязных приёмов у производителей компьютерных комплектующих.
Ограничения на AVX2
Проблема с блокировкой AVX-512 усугубляется тем, что в оставшемся наборе инструкций AVX2 стоит ограничение на максимальный множитель тактовой частоты х51, пишет Igor’s Lab.
То есть при выполнении инструкций AVX2 тактовая частота процессора принудительно понижается до 5,1 ГГц не может быть поднята даже до 5,2 ГГц ни при каких настройках BIOS, независимо от охлаждения, энергопотребления, реальной температуры CPU или запущенного приложения. Например, в программе HWInfo режим принудительного ограничения частоты можно распознать по строке IA: Max Turbo Limit – Yes.

Активирован режим IA: Max Turbo Limit – Yes
Неофициальные хаки
К счастью, уже разработаны методы обхода программных ограничений, установленных Intel, как в отношении блокировки AVX-512, так и по троттлингу AVX2.
Например, компания Asus в материнских платах серии Maximus реализовала патч BIOS, который отключает троттлинг AVX2 при условии принудительного выставления тактовой частоты в BIOS.
Активировать AVX-512 сложнее, но тоже возможно. Сообщество уже нашло способ внедрить в новую прошивку старую версию микрокода от Intel, что эффективно включает обратно AVX-512.

Конечно, в этом случае мы получаем неофициальную версию BIOS с лишением гарантии и всеми вытекающими последствиями. Но это хотя бы доказывает, то отключение AVX-512 является обратимым.
Инструкции AVX были впервые реализованы в процессорах Intel, заменив старые инструкции SSE. С тех пор они стали стандартными инструкциями SIMD для процессоров x86 в двух вариантах, 128-битном и 256-битном, которые также были приняты AMD. С другой стороны, если говорить об инструкциях AVX-512, ситуация иная, и они используются только в процессорах Intel.

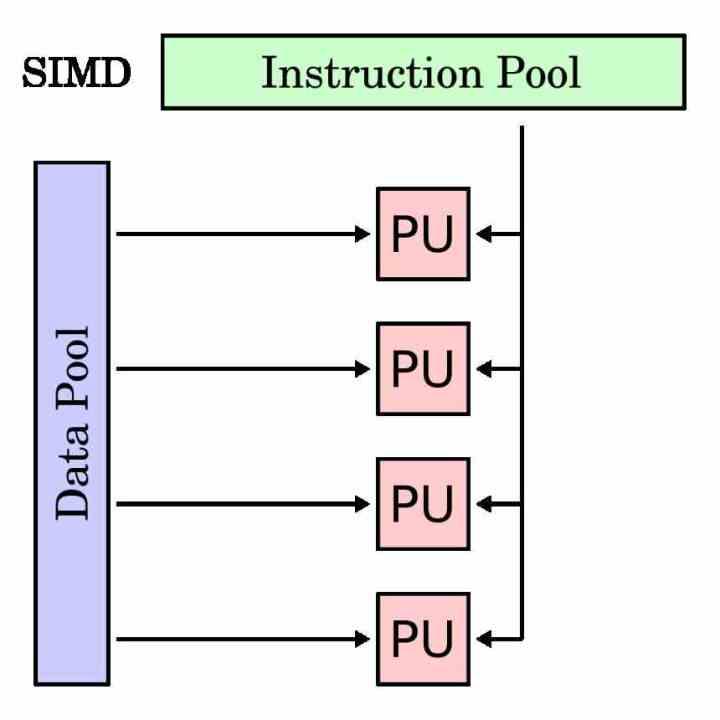
Модуль SIMD — это тип исполнительного модуля, который предназначен для одновременного выполнения одной и той же инструкции для нескольких данных. Следовательно, его регистр накопителя длиннее, чем у традиционной инструкции, поскольку он должен группировать различные данные, с которыми он должен работать с той же самой инструкцией.
Блоки SIMD традиционно использовались для ускорения так называемых мультимедийных процессов, в которых необходимо манипулировать различными данными в соответствии с одними и теми же инструкциями. Блоки SIMD позволяют распараллеливать выполнение программы в этих частях и ускорить время выполнения.
В каждом процессоре, чтобы отделить исполнительные блоки SIMD от традиционных, они имеют собственное подмножество инструкций, которое обычно является зеркалом скалярных инструкций или с одним операндом. Хотя есть случаи, которые невозможно сделать со скалярным модулем и они относятся исключительно к модулям SIMD.
История AVX-512

Инструкции AVX, Advanced Vector eXtensions, находятся внутри процессоров Intel в течение многих лет, но происхождение инструкций AVX-512 отличается от остальных. Причина? Его источником является проект Intel Larrabee, попытка Intel в конце 2000-х годов создать GPU / ГРАФИЧЕСКИЙ ПРОЦЕССОР которые в конечном итоге стали ускорителями Xeon Phi. Серия процессоров, предназначенных для высокопроизводительных вычислений, выпущенная Intel несколько лет назад.
Архитектура Xeon Phi / Larrabee включает специальную версию инструкций AVX с размером регистра накопителя 512 бит, что означает, что они могут работать с 16 32-битными данными. Причина такой суммы связана с тем фактом, что типичное соотношение операций на тексель для графического процессора обычно составляет 16: 1. Не будем забывать, что инструкции AVX-512 взяты из неудачного проекта Larrabee и были перенесены оттуда в Xeon Phi.
По сей день Xeon Phi больше не существует, причина в том, что то же самое можно сделать с помощью традиционного графического процессора для вычислений. Это заставило Intel передать эти инструкции своей основной линейке процессоров.
Тарабарщина в виде инструкций AVX-512
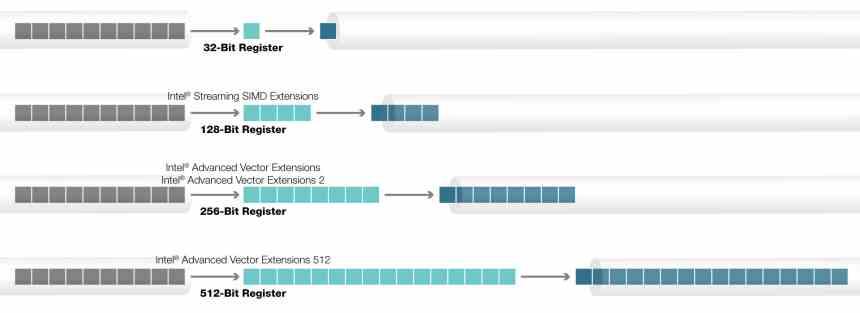
Инструкции AVX-512 не являются однородным блоком, который реализован на 100%, а скорее имеют различные расширения, которые, в зависимости от типа процессора, были добавлены или нет. Все процессоры называются AVX512F, но есть дополнительные инструкции, которые не являются частью исходного набора команд и которые Intel со временем добавила.
Расширения AVX512 следующие:
- AVX-512-CD: Обнаружение конфликтов, позволяет векторизовать циклы и, следовательно, векторизовать их. Впервые они были добавлены в Skylake-X или Skylake-SP.
- AVX-512-ER: Взаимные и экспоненциальные инструкции, которые предназначены для выполнения трансцендентных операций. Они были добавлены в серию Xeon Phi под названием Knights Landing.
- АВХ-512-ПФ: Еще одно включение в Knights Landing, на этот раз для повышения предупредительных или предпочтительных возможностей инструкций.
- AVX-512-BW: Инструкции байтового (8-битного) и уровня слов (16-битного) уровней. Это расширение позволяет работать с 8-битными и 16-битными данными.
- AVX-512-DQ: Добавьте новые инструкции с 32-битными и 64-битными данными.
- АВХ-512-ВЛ : Позволяет инструкциям AVX работать с регистрами накопителя XMM (128-бит) и YMM (256-бит)
- АВХ-512-ИФМА: Fused Multiply Add, которая в просторечии является инструкцией A * (B + C) с 52-битной целочисленной точностью.
- АВХ-512-ВБМИ: Инструкции по манипулированию вектором байтового уровня являются расширением AVX-512-BW.
- АВХ-512-ВННИ: Инструкции векторной нейронной сети — это серия инструкций, добавленных для ускорения алгоритмов глубокого обучения, используемых в приложениях, связанных с искусственным интеллектом.
Почему AMD еще не реализовала это на своих процессорах?

Причина этого очень проста: AMD стремится к комбинированному использованию своих ЦП и ГП при ускорении определенных типов приложений. Давайте не будем забывать происхождение AVX-512 в вышедшем из строя графическом процессоре от Intel и AMD. Благодаря своим графическим процессорам Radeon им не нужны инструкции AVX-512.
Вот почему инструкции AVX-512 являются эксклюзивными для процессоров Intel, не для полной исключительности, а потому, что AMD не заинтересована в использовании этого типа инструкций в своих ЦП, поскольку она намерена продавать свои графические процессоры, особенно недавно выпущенный AMD Instinct. высокопроизводительные вычисления с архитектурой CDNA.
Есть ли будущее у инструкций AVX-512?

Что ж, мы не знаем, это зависит от успеха Intel Xe, особенно Xe-HPC, который даст Intel архитектуру GPU на уровне AMD и NVIDIA. Это означает конфликт между инструкциями Intel Xe и AVX-512 для решения тех же проблем.
Проблема с AVX-512 заключается в том, что активация части процессора, которая его использует, в конечном итоге влияет на тактовую частоту процессора, снижая ее примерно на 25% в программе, которая использует эти инструкции в определенные моменты. Кроме того, его инструкции предназначены для высокопроизводительных вычислений и приложений искусственного интеллекта, которые не важны в том, что является домашним процессором, а появление специализированных блоков делает его пустой тратой транзисторов и пространства.
На самом деле ускорители или процессоры для конкретной области медленно заменяют блоки SIMD в ЦП, поскольку они могут делать то же самое, занимая меньше места и с незначительным энергопотреблением по сравнению.
Аббревиатура AVX расшифровывается как Advanced Vector Extensions. Это наборы инструкций для процессоров Intel и AMD, идея создания которых появилась в марте 2008 года. Впервые такой набор был встроен в процессоры линейки Intel Haswell в 2013 году. Поддержка команд в Pentium и Celeron появилась лишь в 2020 году.
Прочитав эту статью, вы более подробно узнаете, что такое инструкции AVX и AVX2 для процессоров, а также — как узнать поддерживает ли процессор AVX.
AVX и AVX2 – что это такое
AVX/AVX2 — это улучшенные версии старых наборов команд SSE. Advanced Vector Extensions расширяют операционные пакеты со 128 до 512 бит, а также добавляют новые инструкции. Например, за один такт процессора без инструкций AVX будет сложена 1 пара чисел, а с ними — 10. Эти наборы расширяют спектр используемых чисел для оптимизации подсчёта данных.
Наличие у процессоров поддержки AVX весьма желательно. Эти инструкции предназначены, прежде всего, для выполнения сложных профессиональных операций. Без поддержки AVX всё-таки можно запускать большинство игр, редактировать фото, смотреть видео, общаться в интернете и др., хотя и не так комфортно.
Как узнать, поддерживает ли процессор AVX
Далее будут показаны несколько простых способов узнать это. Некоторые из методов потребуют установки специального ПО.
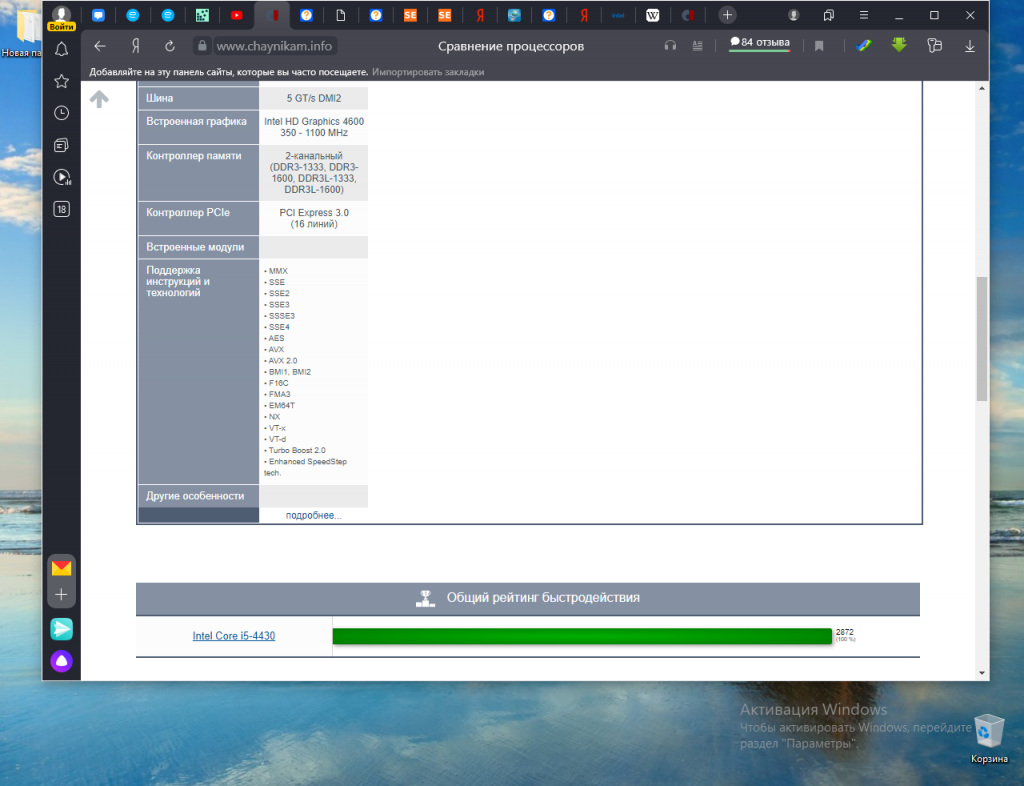
1. Таблица сравнения процессоров на сайте Chaynikam.info.
Для того чтобы узнать, поддерживает ли ваш процессор инструкции AVX, можно воспользоваться предлагаемым способом. Перейдите на этот сайт. В правом верхнем углу страницы расположена зелёная кнопка Добавить процессор. Нажмите её.
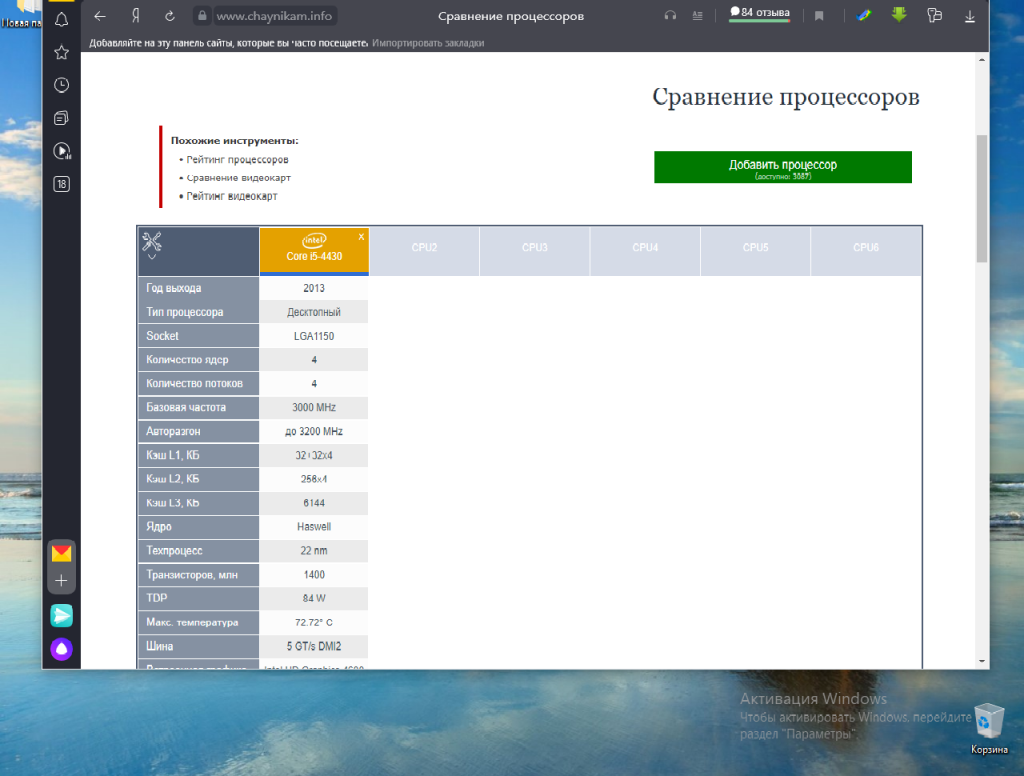
В открывшемся окне вам будет предложено указать параметры выбора нужного процессора. Все указывать не обязательно.
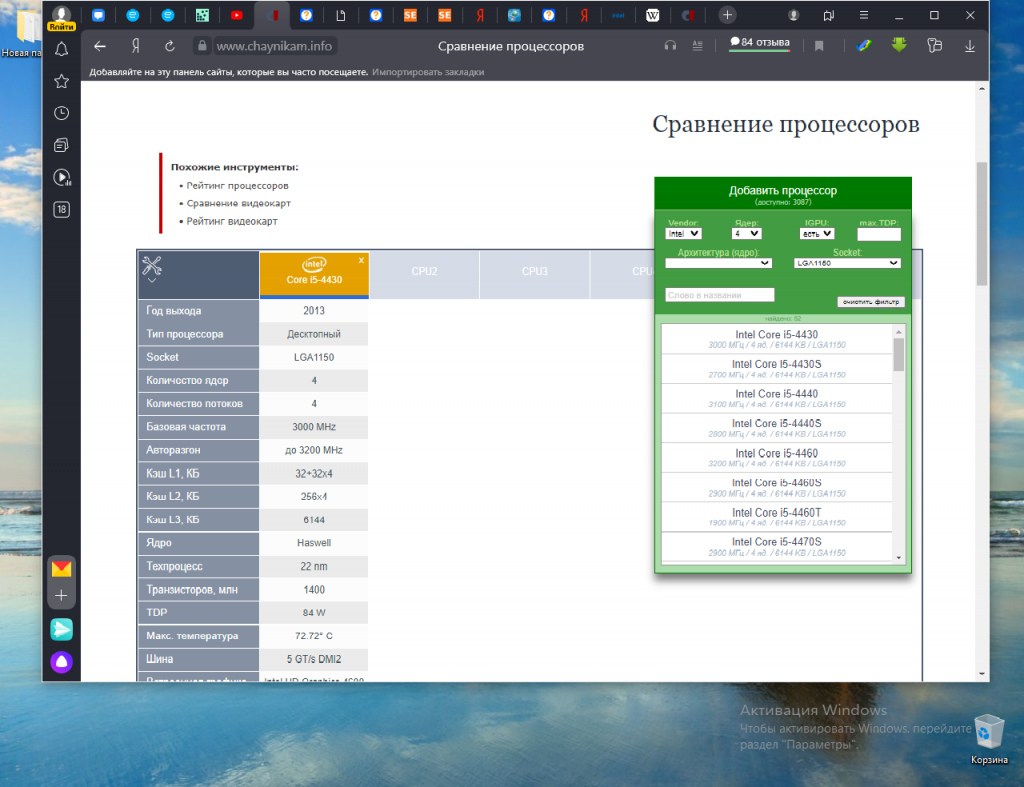
В результате выполнения поиска будет сформирована таблица с параметрами выбранного из списка процессора. Прокрутите таблицу вниз. В строке Поддержка инструкций и технологий будет показана подробная информация.
2. Утилита CPU-Z.
Один из самых простых и надёжных способов узнать поддерживает ли процессор AVX инструкции, использовать утилиту для просмотра информации о процессоре — CPU-Z. Скачать утилиту можно на официальном сайте. После завершения установки ярлык для запуска утилиты появится на рабочем столе. Запустите её.
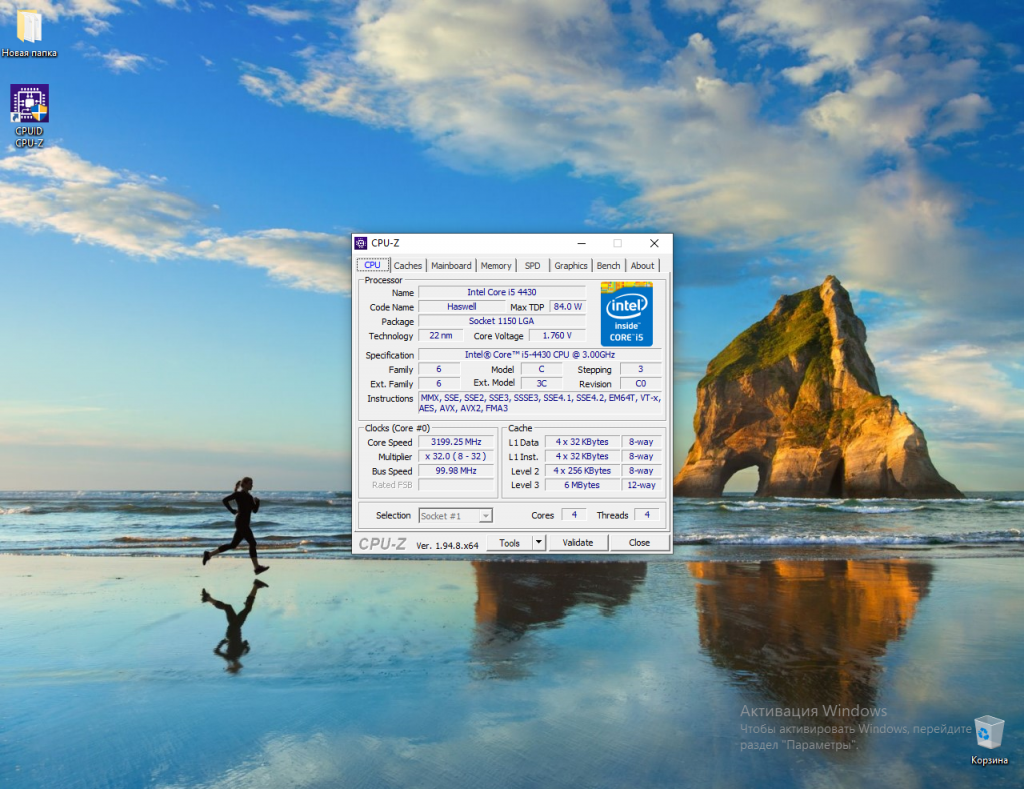
В строке Instructions показаны все инструкции и другие технологии, поддерживаемые вашим процессором.
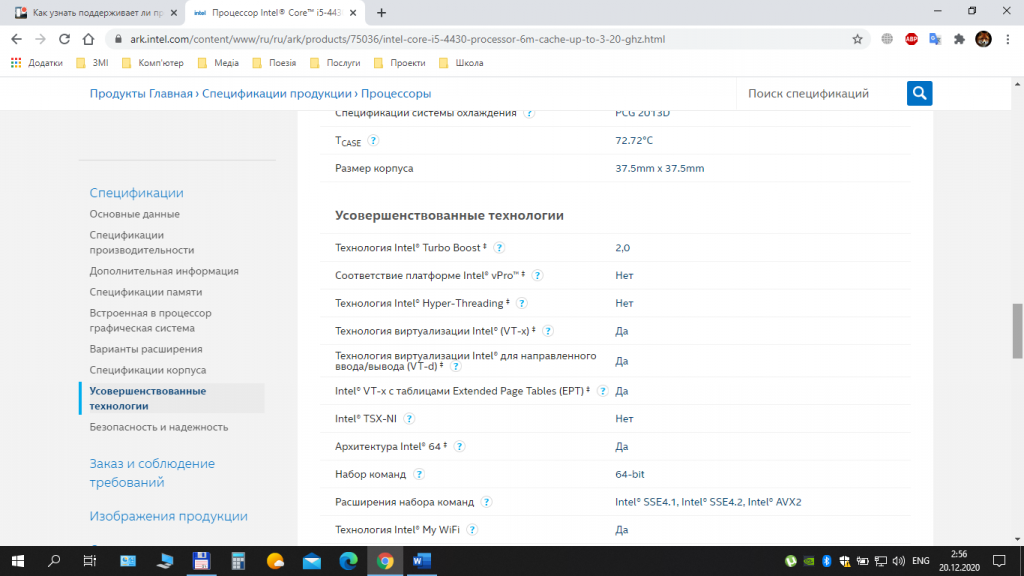
3. Поиск на сайте производителя.
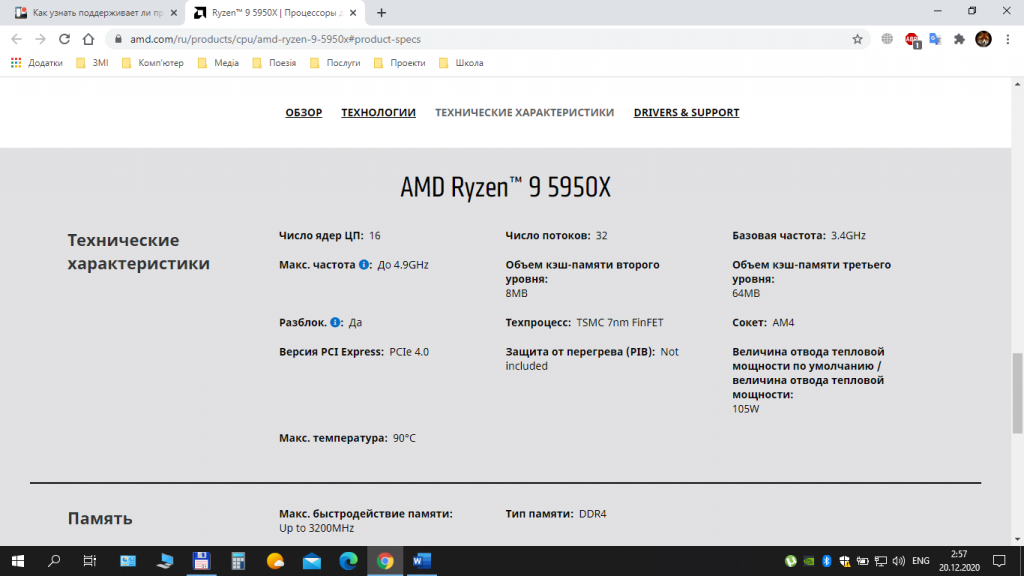
Ещё один способ узнать, есть ли AVX на процессоре, воспользоваться официальным сайтом производителя процессоров. В строке поиска браузера наберите название процессора и выполните поиск. Если у вас процессор Intel, выберите соответствующую страницу в списке и перейдите на неё. На этой странице вам будет предоставлена подробная информация о процессоре.
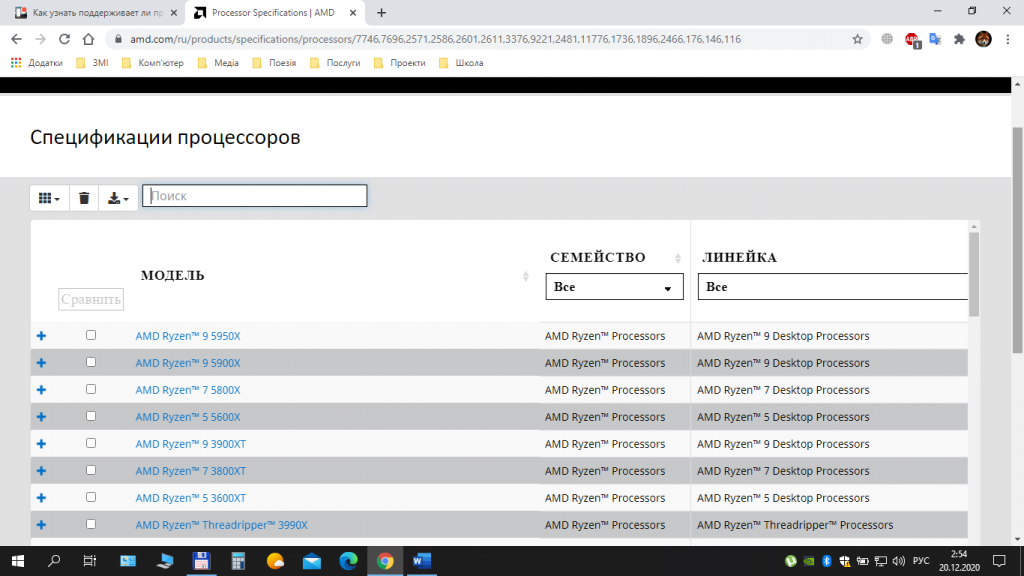
Если у вас процессор от компании AMD, то лучше всего будет воспользоваться сайтом AMD. Выберите пункт меню Процессоры, далее — пункт Характеристики изделия и затем, выбрав тип (например, Потребительские процессоры), выполните переход на страницу Спецификации процессоров. На этой странице выполните поиск вашего процессора по названию и посмотрите подробную информацию о нём.
Выводы
В этой статье мы довольно подробно рассказали о поддержке процессорами инструкций AVX, AVX2, а также показали несколько способов, позволяющих выяснить наличие такой поддержки конкретно вашим процессором. Надеемся, что дополнительная информация об используемом процессоре будет полезна для вас, а также поможет в выборе процессора в будущем.
Была ли эта статья полезной?
ДаНет
Оцените статью:
 (8 оценок, среднее: 5,00 из 5)
(8 оценок, среднее: 5,00 из 5)
![]() Загрузка…
Загрузка…
Об авторе

Над статьей работал не только её автор, но и другие люди из команды te4h, администратор (admin), редакторы или другие авторы. Ещё к этому автору могут попадать статьи, авторы которых написали мало статей и для них не было смысла создавать отдельные аккаунты.
В мире компьютерных технологий нет ничего странного в обилии всевозможных аббревиатур: CPU, GPU, RAM, SSD, BIOS, CD-ROM, и многих других. И почти каждый день появляются всё новые и новые сокращения названий каких-то технологий, что является неизбежным следствием бесконечного стремления инженеров улучшить функции и возможности наших вычислительных устройств.
Сегодня речь пойдёт о таких расширениях набора команд процессоров, как MMX, SSE и AVX. Многим знакомы эти сокращения, и мы выясним, действительно ли это какие-то интересные разработки, или же это не более чем бессмысленные маркетинговые уловки.
Ну о-о-очень первые дни
Середина 80-х прошлого столетия. Рынок процессоров был очень похож на сегодняшний. Intel бесспорно преобладала, но столкнулась с жесткой конкуренцией со стороны AMD. Домашние компьютеры, такие как Commodore 64, использовали базовые 8-битные процессоры, тогда как настольные ПК начинали переходить с 16-битных на 32-битные чипы.
Эти числа означают размер значений данных, которые могут быть обработаны математически, при этом чем выше эти значения, тем выше точность и возможности. Они также определяет размер основных регистров в микросхеме: небольших участков памяти, используемых для хранения рабочих данных.
Такие процессоры являются также скалярными и целочисленными. Что это означает? Скаляр – это когда над одним элементом данных выполняется только одна любая математическая операция. Обычно это обозначается как SISD (single instruction, single data, «одиночный поток команд – одиночный поток данных»).
Таким образом, инструкция по сложению двух значений данных просто обрабатывается для этих двух чисел. А если вам, например, нужно прибавить одно и то же значение к группе из 16 чисел, то для этого потребуется выполнить все 16 наборов инструкций – для каждого числа из этой группы по отдельности. По-другому процессоры тех лет складывать ещё не умели.

Intel 80386DX с частотой 16МГц (1985).
Целое (Integer) – в математике, это такое число, которое не имеет дробной части. Например, 8 или -12. Процессоры типа интеловского 80386SX не имели врожденной способности сложить, скажем, 3.80 и 7.26 – такие дробные числа называются числами с плавающей точкой (или запятой, в русском языке это без разницы) – по-английски FP, floating point или просто floats. Чтобы справиться с ними, нужен был другой процессор, например 80387SX, и отдельный набор инструкций – список команд, который сообщает процессору, что делать.
В те времена под инструкциями x86 понимали наборы команд для целочисленных (integer) операций, а под инструкциями x87 – для чисел с плавающей точкой (float). В наши дни все операции умеет выполнять один процессор, поэтому мы используем термин x86 для обозначения набора инструкций обоих типов данных.
Использование отдельных сопроцессоров для обработки разных типов данных было нормой, пока Intel не представила 80486: их первый CPU для персоналок со встроенным математическим сопроцессором для обработки вещественных данных (FPU, Floating Point Unit).

Intel 80486: Жёлтым цветом выделен блок FPU для обработки чисел с плавающей точкой.
Как вы можете видеть, этот блок совсем немного занимает места в процессоре, но рывок в производительности, благодаря этому решению, был огромен.
Но в целом принцип работы оставался скалярным, и таким он перешел и к преемнику 486-го: оригинальному Intel Pentium.
И пройдёт ещё три года после релиза этого первого Пентиума, прежде чем Intel представит миру Pentium MMX. Это произошло в октябре 1996 года.
V – значит «векторный». А MMX что значит?
В мире математики числа можно группировать в наборы различных видов и размеров – одна такая упорядоченная совокупность называется арифметическим вектором. Проще всего представить его себе в виде списка значений, расположенных горизонтально или вертикально. Технология MMX привнесла в мир процессоров возможность выполнять векторные математические вычисления.
Однако она была изначально довольно ограниченной, поскольку оперировала только целыми числами и фактически эксплуатировала для своих целей регистры FPU. Поэтому программисты, желающие использовать какие-то инструкции MMX, вынуждены иметь в виду, что при выполнении таких инструкций любые вычисления с плавающей запятой не могут выполняться одновременно с ними.
Знаменитая реклама технологии Intel MMX (1997).
FPU Pentium имел 64-битные регистры, и в операциях MMX каждый из них мог вместить два 32-битных, четыре 16-битных или восемь 8-битных целых числа. Именно эти группы чисел и являются векторами, и каждая инструкция, предназначенная для них, будет выполняться сразу над всеми значениями в группе.
Такой принцип получил название SIMD (single instruction, multiple data, «одиночный поток команд, множественный поток данных») и знаменует собой большой шаг вперед в развитии возможностей процессоров для персональных компьютеров.
Ну а какие приложения выигрывают от использования такого принципа? Практически все, которым приходится выполнять одинаковые вычисления над группой однородных данных, и в первую очередь это некоторые функции в 3D-моделировании и мультимедийных технологиях, а также в системах обработки стандартных сигналов.
Например, MMX можно применить для ускорения умножения матриц при обработке вершин в 3D, или для смешивания видеопотоков при работе с хромакеем или альфа-композитингом.

Процессор AMD K6-2 – где-то там есть 3DNow!
К сожалению, внедрение MMX продвигалось довольно медленными темпами из-за негативного влияния этой технологии на производительность операций с плавающей точкой. AMD частично решила эту проблему, создав свою собственную версию под названием 3DNow! примерно через два года после появления MMX. Технология от AMD предлагала больше инструкций SIMD и умела обрабатывать числа с плавающей точкой, но также страдала от недостатка понимания программистами.
Ах, да! Как же официально расшифровывается аббревиатура MMX? Согласно Intel – никак!
Проще пареной SSE
Ситуация переломилась в лучшую сторону с приходом в 1999 году процессора Intel Pentium III. Он принёс с собой блестящую реализацию векторной функции под названием SSE (Streaming SIMD Extensions, «потоковые расширения SIMD»). На этот раз это был дополнительный набор из восьми 128-битных регистров, отдельных от регистров в FPU, и стек дополнительных инструкций для обработки чисел с плавающей точкой.
Использование независимых регистров означает, что больше нет такой сильной зависимости от FPU, хотя Pentium III не мог выполнять инструкции SSE одновременно с инструкциями FP. А также, новая функция поддерживает только один тип данных в регистрах: четыре 32-битных FP-числа.
Но переход к использованию FP-инструкций SIMD позволил значительно увеличить производительность в таких приложениях, как кодирование/декодирование видео, обработка изображений и звука, сжатие файлов и многих других.

Pentium IV: желтым цветом выделен блок регистров SSE2.
Усовершенствованная версия SSE2 появилась в 2001 году вместе с Pentium 4, и на этот раз поддержка типов данных была намного лучше: четыре 32-битных или два 64-битных FP-числа, а также шестнадцать 8-битных, восемь 16-битных, четыре 32-битных или два 64-битных целых числа. Регистры MMX остались в процессоре, но все операции MMX и SSE могли выполняться с использованием независимых 128-битных регистров SSE.
Модификация SSE3 появилась на свет в 2003 году, имея больше инструкций и возможность выполнять некоторые математические вычисления между значениями внутри одного регистра.
Ещё через 3 года мы познакомились с архитектурой Intel Core, принёсшей ещё одну ревизию технологии SIMD (SSSE3 – Supplemental SSE, «расширенные SSE»), и чуть позже в том же году – финальную версию, SSE4.

В 2007 году AMD применила собственную версию расширений CPU-инструкций SSE4 в своей архитектуре Barcelona. С названием в AMD париться не стали, и назвали свою версию просто SSE4a.
С линейкой Nehalem Core в 2008 году было выпущено незначительное обновление этой версии, которую Intel обозначила как SSE4.2 (а под SSE4.1 стали понимать исходную версию этого обновления). Обновления не затронули регистры, а лишь добавили больше инструкций в таблицу, расширив диапазон возможных математических и логических операций.
AMD, со своей стороны, сперва предложила новую версию SSE5, но позже решила разделить ее на три отдельных расширения, одно из которых довольно проблемное – подробнее об этом чуть позже.
К концу 2008 года и Intel, и AMD поставляли процессоры, которые уже могли обрабатывать все версии наборов инструкций от MMX до SSE4.2, и многие приложения (в основном игры) начали требовать этих функций для работы.
Время для новых букв
2008 год также был годом, когда Intel объявила о том, что они работают над значительным апгрейдом своей системы SIMD, и в 2011 году выкатила линейку процессоров Sandy Bridge с поддержкой набора инструкций AVX (Advanced Vector Extensions, «продвинутые векторные расширения»).
Всё удвоилось: вдвое больше векторных регистров и вдвое больше их размер.
Шестнадцать 256-битных регистров вмещают только восемь 32-битных или четыре 64-битных вещественных числа, поэтому в плане форматов данных, этот набор инструкций более ограничен в сравнении с SSE, но ведь и SSE никто не отменял. К тому времени программная поддержка векторных операций для CPU была уже хорошо отлажена, начиная с фундаментального мира компиляторов, заканчивая сложными приложениями.

Над статьей работал не только её автор, но и другие люди из команды te4h, администратор (admin), редакторы или другие авторы. Ещё к этому автору могут попадать статьи, авторы которых написали мало статей и для них не было смысла создавать отдельные аккаунты.


 2-ядерный Intel Skylake
2-ядерный Intel Skylake


