Перевод статьи Learning (not) to Handle Exceptions
В этой статье мы изучим основы обработки ошибок выполнения вашего кода в Python, а также научимся использовать свои собственные (пользовательские) исключения. Вы узнаете, почему иногда лучше не перехватывать исключения и как разработать свой шаблон написания кода, с которым будет удобно работать другим пользователям. Исключения являются важной частью любой программы Python, и их элегантное и эффективное применение на практике значительно повысит ценность и полезность вашего кода.
Примечание переводчика. Многие примеры кода, которые используется в этой статье имеют цель продемонстрировать особенности использования механизма исключений в языке Python. Иногда для наглядности представления особенностей использования инструкций кода, в ущерб практической направленности, некоторые примеры кода довольно надуманы.
Как всегда, вы можете самостоятельно ознакомиться с примерами кода для этой статьи, а также её исходным текстом, и если у вас есть предложения по его улучшению, пишите.
Содержание
- Инструкции Try/Except
- Перехват исключений заданного типа
- Повторное возбуждение исключений
- Использование исключений в исключениях
- Обработка нескольких исключений
- Блок finally
- Блок else
- Работа с traceback (трассировка)
- Применение пользовательских исключений
- Примеры хороших практик использования пользовательских исключений
- Добавляем к исключениям аргументы
- Выводы
Инструкции Try/Except
Допустим, что вы хотите прочитать из файла некоторые данные. Для решения этой задачи вы можете написать что-то вроде этого:
f = open('my_file.dat')
data = f.readfile()
print('Data loaded')
И если вы выполните этот код и файла с именем my_file.dat в рабочей директории нет, то увидите следующее сообщение:
FileNotFoundError: [Errno 2] No such file or directory: 'my_file.dat'
То есть такого файла или директории нет и после появления ошибки код вашей программы не будет выполнен полностью — произойдет её аварийное завершение. Вот почему вы не увидите результата выполнения последней инструкции: сообщения Data loaded в консоли. Это простой пример, часто возникающих на практике ошибок.
Теперь, представьте, что ваша программа в ходе выполнения обращается к некоторому устройству. И если в вашей программе возникает ошибка, то у вас не будет возможности корректно закрыть соединение, чтобы надлежащим образом освободить ресурсы с которыми работало ваше приложение. Это может привести как к потере данных, так и выводу из строя оконечного устройства, которым она управляла.
Работа с такого рода ошибками обычно выполняется с использованием блока инструкций try/except . Из официальной документации известно, что если внутри блока try в коде возникает ошибка, то будет выполнен код в блоке except. С учетом сказанного перепишем код из примера выше следующим образом:
try:
f = open('my_file.dat')
f.readfile()
print('Loaded data')
except:
print('Data not loaded')
Если теперь мы его запустим на выполнение, то увидим на экране сообщение: Data not loaded (Данные не загружены). И это замечательно! Теперь наша программа аварийно не завершает свою работу, и мы можем корректно закрыть соединение или прервать связь с нашим устройством. Однако мы всё ещё не знаем причину, по которой данные не были загружены.
Прежде чем продолжить, создадим пустой файл с именем my_file.dat в рабочей директории и снова запустим наш скрипт на исполнение. И увидим, что данные всё же не загружаются, независимо от того, существует файл или нет, так как наш файл пуст. Таким образом при разработке вашего проекта множество неопределенностей и неоднозначных ситуаций, которые возникают в коде блока except даже в таком простом примере. То есть мы не знаем почему данные не загружены: либо файла нет, либо же он просто пуст, ничего не содержит. Давайте рассмотрим следующий пример кода:
open('my_file.dat')
f.readfile()
print('Loaded data')
После его выполнения получим в консоли ошибку вида:
AttributeError: '_io.TextIOWrapper' object has no attribute 'readfile'
Сообщение об ошибке информирует нас о том, что проблема заключается в том методе readfile, который мы попытались использовать, и что его не существует в полученном объекте.
Если вы используете простой блок try/except , вы будете обрабатывать абсолютно все возможные исключения, но на самом деле у нас нет возможности узнать, что всё же пошло не так, то есть причину появления ошибки. В простых случаях, таких как приведен выше, у вас есть только две строчки кода, которые можно легко проанализировать и найти причину ошибки. Однако, если вы разрабатываете свой пакет или сложную функцию с большим числом вложений кода, то ошибки будут распространяться далее по ходу потока исполнения кода, и вы не знаете, как они повлияют на работу остальной части программы и что именно вызвало их появление.
Чтобы вы имели представление о важности правильной обработки ошибок, я приведу вам пример, ситуации, возникшей при эксплуатации прикладного приложения, которое поставлялось вместе со сложным лабораторным оборудованием. Эта программа управляет прибором Nano Sight и имеет очень приятный пользовательский интерфейс. Однако при сохранении данных, если выбранное имя файла содержало точку, данные не сохранялись. К сожалению, в этом случае данные безвозвратно терялись, и пользователь никогда не узнал бы, что причина возникновения проблемы на самом деле проста: наличие символа . в имени файла.
Поэтому разработка изящного способа обработки всех возможных ошибок очень сложна, а иногда практически невозможна. Тем не менее, вы можете видеть, что программное обеспечение, тем более поставляемое с очень дорогим оборудованием (в данном случае я имею в виду инструменты с ценой, как у небольшой квартиры), должно учитывать возникновение всевозможных видов ошибок и корректную обработку возбужденных исключений.
Перехват исключений заданного типа
Самый правильный способ обработки исключений в Python — указать, какой тип исключения мы ожидаем и соответствующим образом его обработать . Таким образом, если мы узнаём, что проблема в том, что файла не существует, то мы можем его создать. Если же проблема имеет другую природу, то будет генерироваться сообщение с информацией об исключении и отображаться для информирования пользователя. Давайте изменим пример, приведенный выше, следующим образом:
try:
file = open('my_file.dat')
data = file.readfile()
print('Data Loaded')
except FileNotFoundError:
print('This file doesn't exist')
Если вы запустите этот скрипт, а файла my_file.dat в рабочей директории нет, то он выведет на экран сообщение, что файл не существует, и программа продолжит работу. Однако, если файл существует, вы увидите исключение связанное с отсутствием у объекта file метода readfile (такого метода конечно же не существует — это преднамеренная ошибка).
На самом деле мы можем ограничиваться простой печатью сообщения, если происходит перехват исключения — в случае отсутствия файла его легко создать:
try:
file = open('my_file.dat')
data = file.readfile()
print('Data Loaded')
except FileNotFoundError:
file = open('my_file.dat', 'w')
print('File created')
file.close()
Если вы запустите этот скрипт, то увидите, что теперь файл my_file.dat будет создан. Если вы запустите скрипт во второй раз, то будет возбуждено исключение из-за отсутствия метода readfile.
Теперь представьте, что вы не указываете, какое конкретно исключение вы собираетесь перехватывать, и у вас есть следующий код, что произойдет, когда вы его запустите?
try:
file = open('my_file.dat')
data = file.readfile()
print('Data Loaded')
except:
file = open('my_file.dat', 'w')
print('File created')
Если вы его внимательно проанализируете, то поймете, что, даже если файла my_file.dat существует, будет возбуждено исключение, ввиду отсутствия метода readfile. Затем будет выполнен код в блоке except. В этом блоке наша программа создаст новый файл my_file.dat, даже если он уже существует, и, следовательно, вы потеряете все информацию, которая в нем до этого хранилась. Что же мы можем сделать для того, что бы избежать этого рассмотрим далее.
Повторное возбуждение исключений
На практике распространен следующий приём написания кода, когда сначала возбуждается некоторое исключение, далее вы выполняете определённые действия, а затем снова инициализируется это же исключение. Этот прием используется, например, если вы осуществляете запись информации в базу данных или в файл. Представим себе следующую ситуацию: вы храните информацию в двух файлах: в первом вы храните значения частотного спектра, а во втором — температуру, при этом записи в отдельных файлах записываются по порядку и их соответствующие значения снимаются с датчиков в один и тот же момент времени. Далее вы сначала сохраняете в один файл значения спектра, а затем значение температуры уже в другой файл. То есть каждая строка в любом из файлов соответствует в прямом порядке следования некоторой другой строке в другом.
Предположим, что сначала мы сохраняем значения спектра, а затем температуры. Однако время от времени, когда вы пытаетесь считывать показания датчиков у прибора, он сбоит, и значение датчика температуры не считывается. Таким образом, если в этот цикл записи мы не сохраним значение температуры, у вас образуется несоответствие в порядке данных по времени их съёма, потому что во втором файле будет отсутствует строка данных, соответствующая показаниям датчика температуры. В то же время вам не нужно, чтобы эксперимент продолжался далее, так как датчик температуры не исправен и вам необходимо провести с ним некоторые манипуляции. Для решения этой задачи вы можете использовать такой пример кода:
#Данные сохранены. Начало нового цикла опроса датчиков
try:
temp = instrument.readtemp() # пытаемся опросить датчик температуры
except:
remove_last_line(data_file)
# если датчик не отвечает то удалим последнюю запись в файле, записанную в текущем цикле
raise
# возбудим это исключение снова для того, чтобы пользователь был оповещен о возникшей ошибке
save_temperature(temp)
# если все нормально сохраняем показания датчика в файл
Таким образом сначала мы пытаемся получить данные от датчика температуры, и если что-то пойдет не так, мы перехватываем возбужденное исключение, инициированное из-за того, что датчик нам не отвечает. Затем мы удаляем последнюю строку из нашего первого файла с данными о спектре, а затем снова инициируем исключение с помощью оператора raise. Эта команда повторно возбуждает исключение того же типа, что было перехвачено в блоке except. Благодаря этой стратегии мы будем уверены в том, что наши данные в обоих файлах будут согласованны (то есть имеют одинаковую длину или количество записей). А также в том, что программа далее не будет продолжать работать в том, же режиме (и опрашивать нерабочие датчики), и пользователь увидит сообщение с всей необходимой информации о том, что же пошло не так (тип ошибки).
Существует еще один способ практического применения повторного возбуждения исключений. И если кто-то, из читающих эту статью, знает другие способы использования этого приема, напишите мне и я обновлю содержимое статьи с учетом ваших дополнений.
Дополнение. Дело в том, что инструкция except, из примера кода выше, осуществляет перехват абсолютно всех типов исключений, возникающих в ходе выполнения программы. Если же справа от нее указать название класса перехватываемого исключения (или кортеж в котором они перечислены), то этот блок кода будет выполнен лишь при перехвате исключения соответствующего класса.
Рассмотрим следующий пример кода.
try:
# код, который мы проверяем
except:
# при перехвате любого типа исключений
# этот блок кода будет выполнен
raise
except Exception_classname1:
# при перехвате исключения с классом Exception_name1
# этот блок кода будет выполнен
except Exception_classname2:
# при перехвате исключения с классом Exception_name2
# этот блок кода будет выполнен
Как видно первый блок except будет перехватывать абсолютно все типы исключений и соответственно при возникновении любой исключительной ситуации код внутри этого блока будет выполнен всегда. Следующие блоки except будут выполняться только при перехвате исключений соответствующих классов Exception_classname1 и Exception_classname2 .
А значит в первый блок except можно поместить код, который необходимо выполнять при возникновении исключительной ситуации любого вида. После чего инициируем возбуждение исключения того же типа с помощью инструкции raise.
Следующие блоки except с соответствующими классами будут перехватывать заданные типы исключений и внутри их блоков можно добавить код, который будет выполняться в зависимости от вида возникшей исключительной ситуации. Не правда ли, что это очень удобно.
С синтаксисом использования инструкции except вы можете ознакомиться по ссылке. С классами исключительных ситуаций по этой ссылке.
Использование исключений в исключениях
Теперь представим, что наш код является частью функции, отвечающей за открытие файла, загрузку его содержимого или создание нового файла в случае, если файла с указанным именем не существует. Сценарий будет выглядеть так же, как и ранее, с той разницей, что имя файла будет задаваться в переменной:
try:
file = open(filename)
data = file.readfile()
except FileNotFoundError:
file = open(filename, 'w')
Чтобы запустить приведенный этот скрипт на выполнение, мы должны указать имя файла:
filename = 'my_data.dat'
try :
[ ... ]
Если вы запустите этот код, то заметите, что он ведет себя точно так, как ожидалось. Однако, если вы укажете пустое имя файла:
filename = ''
try:
[...]
Вы увидите выведенное на экран сообщение с большим количеством информации о возникшей ошибке, содержащей лишь одну важную строку:
During handling of the above exception, another exception occurred:
Если вы её проанализируете, то увидите, что во время обработки вышеупомянутого исключения было возбуждено другое исключение. К сожалению, это обычная ситуация, особенно когда речь идет о пользовательском вводе.
Решить возникшую причину можно, вложив в наш блок except еще один блок инструкций try/except или же предварительно проверять валидность значения переменной filename перед вызовом инструкции open. Но самый правильный способ избежать возникновения этой ситуации мы рассмотрим ниже.
Обработка нескольких исключений
До сих пор мы рассматривали случаи возбуждения только одного типа исключений, например FileNotFoundError. Тем не менее, листинг кода, который мы уже рассматривали выше, вызывает появление двух исключений различных типов, а точнее FileNotFoundError и AttributeError. Рассмотрим приемы работы с несколькими типами исключений на практике.
Конечно же вы можете специально создавать ситуации, приводящие к возбуждению исключений. Например, если вы запустите на выполнение следующий код:
file = open('my_data.dat', 'a')
file.readfile()
То получите сообщение:
AttributeError: '_io.TextIOWrapper' object has no attribute 'readfile'
Первая часть полученного сообщения (а точнее до символа :) — это имя класса возбужденного исключения, то есть AttributeError, а вот вторая часть — это информация о причине, вызвавшей инициализацию полученного исключения. Отметим, что исключения одного типа могут иметь разное содержимое второй части, сообщения об ошибке, а значит и причины инициализации исключения, а следовательно подробнее описывают то, что его вызвало.
Для решения нашей задачи необходимо перехватить исключения 2 типов: AttributeError и FileNotFound. Поэтому наш код будет иметь вид:
filename = 'my_data.dat'
try:
file = open(filename)
data = file.readfile()
except FileNotFoundError:
file = open(filename, 'w')
print('Created file')
except AttributeError:
print('Attribute Error')
Теперь мы знаем как можно обрабатывать в программе несколько типов исключений. Отметим, что если в какой-либо строке кода внутри блока try возникает исключение, то остальная часть кода в этом блоке не будет выполнена. То есть если файла my_data.dat не существует то, следующая строка кода, то есть data = file.readfile() не будет выполняться.
Далее поток выполнения интерпретатора Python будет последовательно обходить все except. И если будет найдено соответствие типа возбужденного исключения с классом исключений справа от каждой инструкции except, то код внутри этого блока будет выполнен. Поэтому всегда единовременно будет возбуждено только одно исключение определенного типа.
В нашем же случае при первом запуске кода файла my_data.dat не существует, то есть будет инициализироваться исключение типа — FileNotFoundError. Файл будет создан и в консоли мы получим сообщение Created file. При повторном запуске нашего кода будет возбуждено исключение класса AttributeError. Так файл существует, но созданный объект file не имеет метода readfile(), то попытка его вызвать завершится возбуждением соответствующего исключения.
Отметим, что мы можем добавить в конце нашего кода еще один блок except без наименования класса исключения справа для того, чтобы перехватывать все другие исключения, возникающие в ходе выполнения нашей программы:
filename = 'my_data.dat'
try:
file = open(filename)
data = file.read()
important_data = data[0]
except FileNotFoundError:
file = open(filename, 'w')
print('Created file')
except AttributeError:
print('Attribute Error')
except:
print('Unhandled exception')
В случае если файл my_data.dat существует, но он пуст, у нас возникнет еще одна проблема при попытке доступа к содержимому data[0] (получить первый символ строки, в которую мы прочитали содержимое файла). Мы не готовы к обработке этого исключения и поэтому напечатаем лишь сообщение о необработанном исключении (Unhandled exception). Тем не менее, было бы более полезно сообщать пользователю, какое же исключение было возбуждено. Для этого мы можем использовать следующий приём:
filename = 'my_data.dat'
try:
file = open(filename)
data = file.read()
important_data = data[0]
except Exception as e:
print('Unhandled exception')
print(e)
Результатом выполнения этого кода будет следующее сообщение:
Unhandled exception string index out of range
Так как исключения имеют свой определённый тип type, соответствующий наименованию предопределенных классов исключений (официальная документация), то его также можно использовать. Например, следующим образом:
filename = 'my_data.dat'
try:
file = open(filename)
data = file.read()
important_data = data[0]
except Exception as e:
print('Unhandled exception')
if isinstance(e, IndexError):
print(e)
data = 'Information'
important_data = data[0]
print(important_data)
После запуска этого кода на выполнение, он напечатает в консоли первую букву строки Information, то есть I.
Отметим, что изучение этого примера кода имеет своей целью продемонстрировать возможности использования информации о возбужденном исключении, в ущерб практической значимости. Как мы можем видеть, его главный недостаток заключается в том, что переменная important_data будет в конечном итоге не определена. Это произойдет в случае если файл my_data.dat не существует. И поэтому мы получим соответствующее сообщение об ошибке:
NameError: name 'important_data' is not defined
Чтобы не допустить таких ситуаций мы можем добавить еще один блок в последовательность блоков-перехватчиков except, это блок с инструкцией finally.
Блок finally
Код в блоке с инструкцией finally будет выполняться всегда независимо от того, возбуждались ли исключения в блоке try или нет.
filename = 'my_data.dat'
try:
file = open(filename)
data = file.read()
important_data = data[0]
except Exception as e:
if isinstance(e, IndexError):
print(e)
data = 'Information'
important_data = data[0]
else:
print('Unhandled exception')
finally:
important_data = 'A'
print(important_data)
Приведенный выше пример кода очень прост, но совершенно не применим на практике, так как мы специально устанавливаем значение переменной important_data. Тем не менее он наглядно поясняет принцип использования оператора finally . Таким образом если необходимо в коде производить какие либо действия с данными или внешними устройствами, и вы хотите быть абсолютно уверены, что они будут выполнены в любом случае (при возникновении любых ошибок или сбоев), то вы можете включить код этих операций в блок инструкции finally.
Используя блок finally можно быть уверенным, что вы закроете соединение с устройством или файл, открытый для записи или чтения и т. д. Или в общем говоря, корректно освободите все ресурсы, задействованные при работе с вашим программным обеспечением.
И наконец, поведение блока finally, в частности и в нашем примере, будет разным, в зависимости от того сколько раз мы его запустим на исполнение. Давайте рассмотрим следующий пример:
filename = 'my_data.dat'
try:
print('In the try block')
file = open(filename)
data = file.read()
important_data = data[0]
except FileNotFoundError:
print('File not found, creating one')
file = open(filename, 'w')
finally:
print('Finally, closing the file')
file.close()
important_data = 'A'
print(important_data)
Сначала запустим код, для ситуации когда файла my_data.dat не существует. И увидим следующий результат его выполнения:
In the try block File not found, creating one Finally, closing the file
Итак, мы видим , что код последовательно выполнялся в блоках: сначала в try, затем во всех блоках except и наконец в finally. Если вы снова запустите код, то файл уже будет существовать, и, следовательно, результат его выполнения будет совершенно другим:
In the try block
Finally, closing the file
Traceback (most recent call last):
File "JJ_exceptions.py", line 7, in
important_data = data[0]
IndexError: string index out of range
Из полученного сообщения мы видим, что когда возникает необработанное исключение, следующий блок, который будет выполнен, — это finally . Поэтому у нас появляется возможность корректно закрыть наш файл до аварийного завершения программы (освободить ресурсы).
Этот подход удобен тем, что предотвращает любой конфликт с кодом ниже. Вы открываете, а затем при возникновении ошибки закрываете файл, при этом остальная часть нашей программы решает проблему обработки исключения типа IndexError. Если вы хотите запустить наш пример без инициализации исключений, просто напишите что либо в файл my_data.dat, открыв его в простом текстовом редакторе, и вы увидите результат выполнения нашей программы без ошибок и соответственно возбуждения исключений.
Блок else
Изучая вопросы обработки и инициализации исключений, необходимо рассмотреть еще одну инструкцию, которую можно использовать совместно с уже рассмотренными — это инструкция else . Основная идея её использования заключается в том, что код внутри её блока выполняется, если в блоке try не возникло ошибок, значит не инициировалось возбуждение исключений . Из следующего примера, можно очень легко понять как это работает:
filename = 'my_data.dat'
try:
file = open(filename)
except FileNotFoundError:
print('File not found, creating one')
file = open(filename, 'w')
else:
data = file.read()
important_data = data[0]
Самое сложное — это понять полезность использования блока else . И в принципе, код, который мы включили в блок else, мог быть помещен сразу после строки кода, в которой мы открываем файл, как мы это делали ранее. Тем не менее, мы можем использовать блок else для предотвращения перехвата исключений, которые не относятся к коду в блоке try .
Не понятно? Тогда рассмотрим следующий немножко надуманный, но наглядный пример кода. Представьте, что вам необходимо прочитать имя файла из другого файла, а затем открыть его для чтения/записи. Наш код для решения этой задачи будет выглядеть следующим образом:
try:
file = open(filename)
new_filename = file.readline()
except FileNotFoundError:
print('File not found, creating one')
file = open(filename, 'w')
else:
new_file = open(new_filename)
data = new_file.read()
Поскольку мы открываем по очереди два файла, то вполне возможно, что проблема будет в том, что второго файла с указанным именем не существует. Если бы мы поместили этот код в блок try, то мы в конечном итоге в блоке except перехватим исключение, инициированное из-за ошибки открытия второго файла, даже если нам нужно перехватить ошибку открытия первого. Конечно этот пример может быть не совсем правдоподобен, но он наглядно поясняет суть использования инструкции else.
Теперь объединим всё, что мы узнали о приемах обработки и инициализации исключений вместе:
try:
file = open(filename)
new_filename = file.readline()
except FileNotFoundError:
print('File not found, creating one')
file = open(filename, 'w')
else:
new_file = open(new_filename)
data = new_file.read()
finally:
file.close()
Проаназируйте его самостоятельно. Настоятельно рекомендую позже поиграть с примерами кода, представленными в этой статье и посмотреть на практике работу рассмотренных приёмов использования каждого блока инструкций. Если вы еще не достаточно хорошо знаете Python, то возможно, вы столкнетесь с чем то для вас непонятным, и это будет связано с инициализацией и обработкой исключений. Это заставит вас заново запускать скрипты и анализировать полученные результаты снова и снова.
Теперь вы знаете, что использование механизма инициализации и обработки исключений, может применяться на практике разными способами. Отличным ресурсом, содержащим все те материалы, что мы с вами рассмотрели в этой статье, является, конечно же, официальная документация использования исключений в Python.
Работа с traceback (трассировка)
Как вы, наверное, уже могли видеть, когда инициализируется исключение, то на экран консоли выводится большое количество различной информации, описывающей что же все-таки произошло. Например, если вы попытаетесь открыть несуществующий файл, то вы получите следующее сообщение:
Traceback (most recent call last):
File "P_traceback.py", line 13, in
file = open(filename)
FileNotFoundError: [Errno 2] No such file or directory: 'my_data.dat'
Интерпретация получаемых после возбуждения исключений сообщений требует наличия некоторой практики, но для простых случаев это достаточно легко сделать даже начинающим.
Во-первых, в сообщении приведен traceback, или простыми словами, история всех действий интерпретатора, результат выполнения которых привёл к инициализации исключения. И конечно сам процесс детальной расшифровка traceback требует написания отдельного поста.
Во-вторых из нашего примера сообщения сразу можно определить путь к файлу, который стал причиной возникшей ошибки, а также номер строки исходного кода скрипта, выполнение которой привело к ошибке. Если затем вы откроете файл исходного кода в текстовом редакторе и перейдете к этой строке, то увидите, что это строка, содержащую следующие инструкции: file = open(filename). И наконец из сообщения, вы можете узнать тип возникшего исключения FileNotFoundError, также как мы это делали ранее.
В последнем примере с выведенным на экран сообщением о возбужденном исключения мы пренебрегали использованием модуля traceback из состава стандартной библиотеки Python. Что позволило бы нам более точно определить источник ошибок, приведший к возбуждению исключений. К счастью, Python и возможности его стандартной библиотеки позволяют легко получить доступ к информации traceback и осуществлять трассировку выполнения скрипта в ходе отладки. Немного изменив наш пример с открытием файла, получим:
import traceback
filename = 'my_data.dat'
try:
file = open(filename)
data = file.read()
except FileNotFoundError:
traceback.print_exc()
Если вы снова запустите код, то увидите на экране ту же информацию как и в примере сообщения об исключении выше, но при этом импортируемый модуль traceback предоставляет больше возможностей для трассировки вашей программы. Работа с пошаговыми трассировками выполнения вашего кода очень удобна для отладки.
Примеры, которые мы рассмотрели в этой статье, очень просты, но когда у вас проект с очень сложным кодом, с большим числом вложений, например, когда одна функция вызывает другую, которая в свою очередь создает объект, и запускает его метод и т. д. В этом случае узнать, что же вызвало возбуждение исключения и в каком месте вашего кода, становится сложной нетривиальной задачей.
Применение пользовательских исключений
Если вы будете заниматься разработкой пакетов, часто бывает полезно определить собственные типы исключений. Это дает большую гибкость вашим приложениям, поскольку позволяет другим разработчикам корректно обрабатывать их по своему усмотрению. И так давайте рассмотрим эту идею на следующем примере.
Представьте, что вы разрабатываете код, содержащий функцию, которая вычисляет среднее двух чисел, но вы хотите, чтобы оба эти числа были положительными. Это тот же пример иллюстрирует паттерн проектирования, известный как декоратор.
Начнем с определения нашей функции:
def average(x, y):
return (x + y)/2
Далее мы хотим возбуждать исключение Exception, в случае если любой из входных аргументов функции отрицателен. Для этого сделаем следующее:
def average(x, y):
if x<=0 or y<=0:
raise Exception('Both x and y should be positive')
return (x + y)/2
Если вы попробуете это вызвать нашу функцию с отрицательным параметром, в консоли вы увидите следующее:
Exception: Both x and y should be positive
Как видно, мы получили то, что хотели. Однако, если вы создаете пакет и ожидаете, что другие разработчики будут его использовать, было бы лучше определить пользовательское исключение, которое затем можно будет явно перехватить. С учётом сказанного наш код может выглядеть следующим образом:
class NonPositiveError(Exception):
pass
def average(x, y):
if x <= 0 or y <= 0:
raise NonPositiveError('Both x and y should be positive')
return (x + y) / 2
Объявляем класс нашего исключения, который будет наследовать от общего класса Exception. На данном этапе, мы просто будем выполнять инструкцию pass в теле нашего класса исключения.
Если мы запустим приведенный выше код с отрицательным значением входного параметра функции, то получим:
NonPositiveError: Both x and y should be positive
Теперь если вы захотите далее в коде перехватывать ваше пользовательское исключение типа NonPositiveError, то будете делать так как мы делали это ранее. Единственным отличием будет то, что пользовательские исключения по умолчанию недоступны, и их следует импортировать. Например, следующим образом:
from exceptions import NonPositiveError
from tools import average
try:
avg = average(1, -2)
except NonPositiveError:
avg = 0
Если вы достаточно долго работали с пакетами, то возможно уже сталкивались с большим разнообразием видов пользовательских исключений, подобных уже нами рассмотренным. Они являются отличным инструментом, позволяющим пользователю точно указать, что случилось при выполнении кода пакета, и далее действовать соответствующим образом. А значит мы должны быть готовы к обработке исключений различных типов: как пользовательских, так и общих, определенных в Python. Отметим, что в сообществе разработчиков Python приветствуется использование в своих пакетах и модулях пользовательских исключений, что облегчает их поддержку и использование.
Примеры хороших практик использования пользовательских исключений
Как мы уже говорили выше, при разработке пакета, очень удобно определять собственные пользовательские исключения, которые относятся только к выполнению кода пакета. Это значительно облегчает в дальнейшем разработку вашего приложения и дает другим разработчикам эффективный инструмент для определения проблем при выполнении кода в вашем пакете. Представьте, например, что вы работаете с приложением, использующим в качестве зависимости ваш пакет и хотите записывать какую-либо информацию в файл каждый раз, когда возбуждается исключение в коде вашего пакета.
Это достаточно легко, так из официальной документации известно, что типы всех исключений могут наследоваться от одного базового класса. Приведенный ниже пример кода достаточно большой, но включает в себя код всех примеров, рассмотренных нами выше, и поэтому его анализ будет несложен:
class MyException(BaseException):
pass
class NonPositiveIntegerError(MyException):
pass
class TooBigIntegerError(MyException):
pass
def average(x, y):
if x<=0 or y<=0: raise NonPositiveIntegerError('Either x or y is not positive') if x>10 or y>10:
raise TooBigIntegerError('Either x or y is too large')
return (x+y)/2
try:
average(1, -1)
except MyException as e:
print(e)
try:
average(11, 1)
except MyException as e:
print(e)
try:
average('a', 'b')
except MyException as e:
print(e)
print('Done')
Сначала определим свой класс исключений MyException, которой станет нашим базовым классом. Затем определим два класса исключений NonPositiveIntegerError и TooBigIntegerError, которые наследуют от MyException . Далее определим функцию average, но на этот раз в ней будет инициализироваться два разных типа исключений соответствующих случаям: если одно или оба из чисел, передаваемых в качестве аргумента, отрицательны или больше 10.
Далее в нашем примере представлены варианты вызова функции average с различными значениями аргументов. Отметим, что в блоке try/except мы всегда будем перехватывать исключение типа MyException, соответствующего нашему базовому классу, а не одно из конкретных типов исключений.
В первых двух примерах, передавая числа -1 и 11 в качестве аргументов, мы успешно выводим на экран сообщение об ошибке, и программа продолжает работать. Однако, если мы попытаемся вычислить среднее значение между двумя буквами (строками), возбужденное исключение будет иметь другую причину инициализации и не будет перехвачено блоком Exception. Поэтому программа аварийно завершит работу и вы увидите на экране следующее сообщение:
TypeError: '<=' not supported between instances of 'str' and 'int'
Таким образом, основным преимуществом использования классов для обработки пользовательских исключений заключается в возможности указания базового класса для перехвата всех исключений соответствующих классов-потомков.
Добавляем к исключениям аргументы
Иногда удобно использовать синтаксис аргументов в дополнении к инструкциям исключений, для предоставления пользователям более информативного форматированного вывода сообщений об ошибках. На примере нашей функции для вычисления среднего определим класс исключения NonPositiveIntegerError c использованием аргументов:
class MyException(BaseException):
pass
class NonPositiveIntegerError(MyException):
def __init__(self, x, y):
super(NonPositiveIntegerError, self).__init__()
if x<=0 and y<=0:
self.msg = 'Both x and y are negative: x={}, y={}'.format(x, y)
elif x<=0:
self.msg = 'Only x is negative: x={}'.format(x)
elif y<=0:
self.msg = 'Only y is negative: y={}'.format(y)
def __str__(self):
return self.msg
def average(x, y):
if x<=0 or y<=0:
raise NonPositiveIntegerError(x, y)
return (x+y)/2
try:
average(1, -1)
except MyException as e:
print(e)
Как видно из этого примера, инструкция возбуждения исключения принимает два аргумента, x и y, и генерирует на их основе форматированное сообщение. Отметим, что в нашем примере сообщение об ошибке может содержать информацию о том, что аргументы, переданные в функцию average, могут быть как оба отрицательны, так и о каждом непосредственно.
То есть использование аргументов при возбуждении и обработки исключений, предоставляет не только общую информацию об ошибке, но и более детальную о причине ее появления. И это очень удобно.
Ключевая часть в объявлении нашего пользовательского класса исключений находится в конце его объявления — это метод __str__. Этот метод отвечает непосредственно за то, что появляется на экране, когда вы используете инструкцию print(e) в блоке except . В нашем примере мы просто возвращаем сообщение, генерированное методом __init__, но многие разработчики предпочитают генерировать сообщение в методе __str__ на основе параметров, переданных в конструктор класса.
Выводы
Исключения в консоли — это то, что никто не хочет видеть в ходе разработки и отладки проекта, но на практике без них никак. Возможно, вы попытаетесь прочитать файл, который не существует, или пользователь, использующий вашу программу, ввёл в неё недопустимые значения, или же матрица данных, которые вы пытаетесь обработать, содержит число измерений, отличное от ожидаемых вами и т. д.
Обработка исключений является достаточной деликатной темой, поскольку она может привести к еще большему количеству проблем. Исключение — это сообщение вам о том, что с вашим кодом происходит что-то не так, и если вы не исправите ошибку должным образом, дальше станет еще хуже.
В тоже время обработка исключений может помочь вам избежать несоответствия входных данных ожидаемым, не корректно освобождать ресурсы, закрывать соединения со внешними устройствами, соединения по сети или корректно закрывать файлы с данными и т. д.
Использование инструкций try/except очень удобно если вы точно знаете, какие могут возбуждаться исключения и как их затем обработать. Поэтому при работе с ними необходимо предусмотреть все возможные ситуации и спланировать перехват возбужденных исключений таким образом, чтобы работа программы не завершилась аварийно и не произошло утечек ресурсов и потери данных.
Как и в любой другой теме, посвященной Python или другому языку программирования, лучший способ изучить его — внимательно посмотреть на код другого и проанализировать его. Не все пакеты определяют свои собственные исключения и не обрабатывают их одинаково. Если вы ищете вдохновение, вы можете посмотреть ошибки Pint , в его небольшом простом пакете, или исключения Django, как пример гораздо более сложного проекта.
Код, и текст статьи доступны по ссылкам и если у вас есть какие-либо комментарии или предложения по его улучшению, пишите.
5.7. Перехват исключений с использованием try и except
Ранее мы рассматривали код, где использовались функции raw_input и int.
Мы также видели их ненадежное исполнение:
>>> speed = raw_input(prompt) What...is the airspeed velocity of an unladen swallow? What do you mean, an African or a European swallow? >>> int(speed) ValueError: invalid literal for int() >>>
Когда мы запускали эти инструкции в интерпретаторе Python, то получали
строку приглашения, затем набирали наш текст.
Пример простой программы, которая переводит температуру по Фаренгейту в
температуру по Цельсию:
inp = raw_input('Enter Fahrenheit Temperature:')
fahr = float(inp)
cel = (fahr - 32.0) * 5.0 / 9.0
print cel
Если мы запустим этот код и введем некорректные данные, то получим
недружелюбное сообщение об ошибке:
Enter Fahrenheit Temperature:72 22.2222222222 Enter Fahrenheit Temperature:fred Traceback (most recent call last): File "fahren.py", line 2, in <module> fahr = float(inp) ValueError: invalid literal for float(): fred
Существует структура условного выполнения, встроенная в Python, которая
обрабатывает эти типы ожидаемых и неожиданных ошибок, она называется
«try / except«. Идея try и except заключается в следующем: вы знаете, что
некоторая последовательность инструкций может иметь проблемы, и вы
хотите добавить некоторые инструкции, которые бы выполнялись в случае
возникновения ошибки. Эти дополнительные инструкции (блок except)
игнорируются, если ошибок не произошло.
Вы можете представить try и except как страховой полис для
последовательности инструкций.
Перепишем нашу программу о температуре следующим образом:
inp = raw_input('Enter Fahrenheit Temperature:')
try:
fahr = float(inp)
cel = (fahr - 32.0) * 5.0 / 9.0
print cel
except:
print 'Please enter a number'
Python начинает выполнение с последовательности инструкций в блоке try.
Если все выполняется без ошибок, то блок except пропускается. Если
произошло исключение (exception) в блоке try, то Python покидает блок try и
выполняет последовательность инструкций внутри блока except.
Enter Fahrenheit Temperature:72 22.2222222222 Enter Fahrenheit Temperature:fred Please enter a number
Обработка исключения с помощью инструкции try называется перехватом
(catching) исключения. В рассмотренном примере, блок except выводит на
экран сообщение об ошибке. В общем, перехват исключения предоставляет
вам шанс решить проблему, попытаться заново или хотя бы красиво
завершить работу программы.
5.10. Словарь
Тело (body): последовательность инструкций в составной инструкции.
Логическое выражение (boolean expression): выражение, значением которого
может быть либо True, либо False.
Ветка (branch): одна из возможных последовательностей инструкций в
условной инструкции.
Цепочное условие (chained conditional): условная инструкция с несколькими
возможными ветками.
Оператор сравнения (comparison operator): один из операторов, который
сравнивает операнды: ==, !=, >, <, >= и <=.
Условная инструкция (conditional statement): инструкция, которая
контролирует поток выполнения в зависимости от некоторого условия.
Условие (condition): логическое выражение в условной инструкции, которое
определяет, какая ветка выполнится.
Составная инструкция (compound statement): инструкция, которая содержит
заголовок и тело. Заголовок заканчивается (:). Тело смещается относительно
заголовка.
Логический оператор (logical operator): один из операторов, которые
объединяют логические выражения: and, or и not.
Вложенное условие (nested conditional): условная инструкция, которая
встречается в одной из веток другой условной инструкции.
 К сожалению, многие программисты не склонны тратить время на то, чтобы застраховать свой код PL/SQL от всех возможных неожиданностей. У большинства из нас хватает проблем с написанием кода, реализующего положительные аспекты приложения: управление данными клиентов, построение счетов и т. д.; вдобавок это увеличивает объем работы. Всегда бывает дьявольски сложно — как с психологической точки зрения, так и в отношении расходования ресурсов — сосредоточиться на негативных аспектах работы системы: что, если пользователь нажмет не ту клавишу? А что делать, если база данных Oracle недоступна?
К сожалению, многие программисты не склонны тратить время на то, чтобы застраховать свой код PL/SQL от всех возможных неожиданностей. У большинства из нас хватает проблем с написанием кода, реализующего положительные аспекты приложения: управление данными клиентов, построение счетов и т. д.; вдобавок это увеличивает объем работы. Всегда бывает дьявольски сложно — как с психологической точки зрения, так и в отношении расходования ресурсов — сосредоточиться на негативных аспектах работы системы: что, если пользователь нажмет не ту клавишу? А что делать, если база данных Oracle недоступна?
В результате мы пишем приложения PL/SQL, предназначенные для работы в «идеальном мире», где в программах не бывает ошибок, пользователи вводят лишь правильные данные, а все системы — и аппаратные и программные — всегда в полном порядке.
Конечно, жестокая реальность устанавливает свои правила: как бы вы ни старались, в приложении все равно отыщется еще одна ошибка. А ваши пользователи всегда постараются отыскать последовательность нажатий клавиш, от которых форма перестанет работать. Проблема проста: либо вы выделяете время на отладку и защиту своих программ, либо вам придется вести бесконечные бои в отступлении, принимая отчаянные звонки от пользователей и пытаясь потушить разгорающееся пламя.
К счастью, PL/SQL предоставляет достаточно мощный и гибкий механизм перехвата и обработки ошибок. И вполне возможно написать на языке PL/SQL такое приложение, которое полностью защитит от ошибок и всех пользователей, и базу данных Oracle.
Основные концепции и терминология обработки исключений
В языке PL/SQL ошибки всех видов интерпретируются как исключения — ситуации, которые не должны возникать при нормальном выполнении программы.
К числу исключений относятся:
- ошибки, генерируемые системой (например, нехватка памяти или повторяющееся значение индекса);
- ошибки, вызванные действиями пользователя;
- предупреждения, выдаваемые приложением пользователю.
PL/SQL перехватывает ошибки и реагирует на них при помощи так называемых обработчиков исключений. Механизм обработчиков исключений позволяет четко отделить код обработки ошибок от основной логики программы, а также дает возможность реализовать обработку ошибок, управляемую событиями (в отличие от старой линейной модели). Независимо от того, как и по какой причине возникло конкретное исключение, оно всегда обрабатывается одним и тем же обработчиком в разделе исключений.
При возникновении ошибки — как системной, так и ошибки в приложении — в PL/SQL инициируется исключение. В результате выполнение блока прерывается, и управление передается для обработки в раздел исключений текущего блока, если он имеется. После обработки исключения возврат в тот блок, где исключение было инициировано, невозможен, поэтому управление передается во внешний блок.
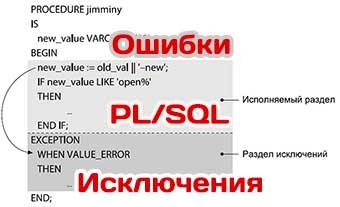
Схема передачи управления при возникновении исключения показана на рис. 1.

Рис. 1. Архитектура обработки исключений
Существует два типа исключений:
- Системное исключение определяется в Oracle и обычно инициируется исполняемым ядром PL/SQL, обнаружившим ошибку. Одним системным исключениям присваиваются имена (например,
NO_DATA_FOUND), другие ограничиваются номерами и описаниями. - Исключение, определяемое программистом, актуально только для конкретного приложения. Имя исключения можно связать с конкретной ошибкой Oracle с помощью директивы компилятора
EXCEPTION_INITили же назначить ошибке номер и описание процедуройRAISE_APPLICATION_ERROR.
В этом блоге будут использоваться следующие термины:
- Раздел исключений — необязательный раздел блока PL/SQL (анонимного блока, процедуры, функции, триггера или инициализационного раздела пакета), содержащий один или несколько обработчиков исключений. Структура раздела исключений очень похожа на структуру команды
CASE, о которой рассказывалось в этом блоге. - Инициировать исключение — значит остановить выполнение текущего блока PL/SQL, оповещая исполняемое ядро об ошибке. Исключение может инициировать либо Oracle, либо ваш собственный программный код при помощи команды
RAISEили процедурыRAISE_APPLICATION_ERROR. - Обработать исключение — значит перехватить ошибку, передав управление обработчику исключения. Написанный программистом обработчик может содержать код, который в ответ на исключение выполняет определенные действия (например, записывает информацию об ошибке в журнал, выводит сообщение для пользователя или передает исключение во внешний блок).
- Область действия — часть кода (конкретный блок или весь раздел), в котором может инициироваться исключение, а также часть кода, инициируемые исключения которого могут перехватываться и обрабатываться соответствующим разделом исключений.
- Передача исключения — процесс передачи исключения во внешний блок, если в текущем блоке это исключение не обработано.
- Необработанное исключение — исключение, которое передается без обработки из «самого внешнего» блока PL/SQL. После этого управление передается исполнительной среде, которая уже сама определяет, как отреагировать на исключение (выполнить откат транзакции, вывести сообщение об ошибке, проигнорировать ее и т. д.).
- Анонимное исключение — исключение, с которым связан код ошибки и описание. Такое исключение не имеет имени, которое можно было бы использовать в команде
RAISEили секцииWHENобработчика исключений. - Именованное исключение — исключение, которому имя присвоено либо Oracle (в одном из встроенных пакетов), либо разработчиком. В частности, для этой цели можно использовать директиву компилятора
EXCEPTION_INIT(в таком случае имя можно будет применять и для инициирования, и для обработки исключения).
Определение исключений
Прежде чем исключение можно будет инициировать и обрабатывать, его необходимо определить. В Oracle заранее определены тысячи исключений, большинство из которых имеют только номера и пояснительные сообщения. Имена присваиваются только самым распространенным исключениям.
Имена присваиваются в пакете STANDARD (одном из двух пакетов по умолчанию PL/SQL; другой пакет — DBMS_STANDARD), а также в других встроенных пакетах, таких как UTL_FILE и DBMS_SQL. Код, используемый Oracle для определения исключений (таких, как NO_DATA_FOUND), не отличается от кода, который вы будете использовать для определения или объявления ваших собственных исключений.
Это можно сделать двумя способами, описанными ниже.
Объявление именованных исключений
Исключения PL/SQL, объявленные в пакете STANDARD и в других встроенных пакетах, представляют внутренние (то есть системные) ошибки. Однако многие проблемы, с которыми будет сталкиваться пользователь приложения, актуальны только в этом конкретном приложении. Возможно, вашей программе придется перехватывать и обрабатывать такие ошибки, как «отрицательный баланс счета» или «дата обращения не может быть меньше текущей даты». Хотя эти ошибки имеют иную природу, нежели, скажем, ошибки «деления на нуль», они также относятся к разряду исключений, связанных с нормальной работой программы, и должны обрабатываться этой программой.
Одной из самых полезных особенностей обработки исключений PL/SQL является отсутствие структурных различий между внутренними ошибками и ошибками конкретных приложений. Любое исключение может и должно обрабатываться в разделе исключений независимо от типа ошибки.
Конечно, для обработки исключения необходимо знать его имя. Поскольку в PL/SQL имена пользовательским исключениям автоматически не назначаются, вы должны делать это самостоятельно, определяя исключения в разделе объявлений блока PL/SQL. При этом задается имя исключения, за которым следует ключевое слово EXCEPTION:
имя_исключения EXCEPTION;Следующий раздел объявлений процедуры calc_annual_sales содержит два объявления исключений, определяемых программистом:
PROCEDURE calc_annual_sales(company_id_in IN company.company_id%TYPE)
IS
invalid_company_id EXCEPTION;
negative_balance EXCEPTION;
duplicate_company BOOLEAN;
BEGIN
... исполняемые команды ...
EXCEPTION
WHEN NO_DATA_FOUND -- системное исключение
THEN
...
WHEN invalid_company_id
THEN
WHEN negative_balance
THEN
...
END;По своему формату имена исключений схожи с именами других переменных, но ссылаться на них можно только двумя способами:
- В команде RAISE, находящейся в исполняемом разделе программы (для инициирования исключения):
RAISE invalid_company_id;
- В секции WHEN раздела исключений (для обработки инициированного исключения):
WHEN invalid_company_id THEN
Связывание имени исключения с кодом ошибки
В Oracle, как уже было сказано, имена определены лишь для самых распространенных исключений. Тысячи других ошибок в СУБД имеют лишь номера и снабжены пояснительными сообщениями. Вдобавок инициировать исключение с номером ошибки (в диапазоне от –20 999 до –20 000) может и разработчик приложения, воспользовавшись для этой цели процедурой RAISE_APPLICATION_ERROR (см. далее раздел «Инициирование исключений»).
Наличие в программном коде исключений без имен вполне допустимо, но такой код малопонятен и его трудно сопровождать. Допустим, вы написали программу, при выполнении которой Oracle выдает ошибку, связанную с данными, например ORA-01843: not a valid month. Для перехвата этой ошибки в программу включается обработчик следующего вида:
EXCEPTION
WHEN OTHERS THEN
IF SQLCODE = -1843 THENНо код получается совершенно непонятным. Чтобы сделать смысл этого кода более очевидным, следует воспользоваться директивой EXCEPTION_INIT.
Встроенная функция SQLCODE возвращает номер последней сгенерированной ошибки. Она будет рассмотрена далее в разделе «Обработка исключений» этой статьи.
Директива EXCEPTION_INIT
Директива компилятора EXCEPTION_INIT (команда, выполняемая во время компиляции) связывает идентификатор, объявленный с ключевым словом EXCEPTION, с внутренним кодом ошибки. Установив такую связь, можно инициировать исключение по имени и указать это имя в условии WHEN обработчика ошибок.
С директивой EXCEPTION_INIT условие WHEN, использованное в предыдущем примере, приводится к следующему виду:
PROCEDURE my_procedure
IS
invalid_month EXCEPTION;
PRAGMA EXCEPTION_INIT (invalid_month, −1843);
BEGIN
...
EXCEPTION
WHEN invalid_month THENЖесткое кодирование номера ошибки становится излишним; имя ошибки говорит само за себя.
Директива EXCEPTION_INIT должна располагаться в разделе объявлений блока. Указанное в ней исключение должно быть объявлено либо в том же блоке, либо во внешнем, либо в спецификации пакета. Синтаксис директивы в анонимном блоке:
DECLARE
имя_исключения EXCEPTION;
PRAGMA EXCEPTION_INIT (имя_исключения, целое_число);Здесь имя_исключения — имя исключения, объявляемого программистом, а целое_число — номер ошибки Oracle, которую следует связать с данным исключением. Номером ошибки может служить любое число со следующими ограничениями:
- Номер ошибки не может быть равен –1403 (один из двух кодов ошибок
NO_DATA_FOUND). Если вы по какой-либо причине захотите связать свое именованное исключение с этой ошибкой, передайте директивеEXCEPTION_INITзначение 100. - Номер ошибки не может быть равен 0 или любому положительному числу, кроме 100.
- Номер ошибки не может быть отрицательным числом, меньшим –1 000 000.
Рассмотрим пример возможного объявления исключения. В приведенном ниже программном коде я объявляю и связываю исключение со следующим номером:
ORA-2292 integrity constraint (OWNER.CONSTRAINT) violated -
child record found.Ошибка происходит при попытке удаления родительской записи, у которой в таблице имеются дочерние записи (то есть записи с внешним ключом, ссылающимся на родительскую запись):
PROCEDURE delete_company (company_id_in IN NUMBER)
IS
/* Объявление исключения. */
still_have_employees EXCEPTION;
/* Имя исключения связывается с номером ошибки. */
PRAGMA EXCEPTION_INIT (still_have_employees, 2292);
BEGIN
/* Попытка удаления информации о компании. */
DELETE FROM company
WHERE company_id = company_id_in;
EXCEPTION
/* При обнаружении дочерних записей инициируется это исключение! */
WHEN still_have_employees
THEN
DBMS_OUTPUT.PUT_LINE
('Пожалуйста, сначала удалите данные о служащих компании.');
END;Рекомендации по использованию EXCEPTION_INIT
Директиву EXCEPTION_INIT целесообразно использовать в двух ситуациях:
- при необходимости присвоить имя безымянному системному исключению, задействованному в программе (следовательно, если в Oracle не определено имя для некоторой ошибки, это еще не означает, что с ней можно работать только по номеру);
- когда нужно присвоить имя специфическому для приложения исключению, инициируемому процедурой
RAISE_APPLICATION_ERROR(см. далее раздел «Инициирование исключений»). Это позволяет обрабатывать данное исключение по имени, а не по номеру.
В обоих случаях все директивы EXCEPTION_INIT желательно объединить в пакет, чтобы определения исключений не были разбросаны по всему коду приложения. Допустим, вы интенсивно используете динамический SQL, и при выполнении запросов часто возникает ошибка «invalid column name» (неверное имя столбца). Запоминать код ошибки не хочется, но и определять директивы имя для исключения в 20 разных программах тоже неразумно. Поэтому имеет смысл определить собственные «системные исключения» в отдельном пакете для работы с динамическим SQL:
CREATE OR REPLACE PACKAGE dynsql
IS
invalid_table_name EXCEPTION;
PRAGMA EXCEPTION_INIT (invalid_table_name, -903);
invalid_identifier EXCEPTION;
PRAGMA EXCEPTION_INIT (invalid_identifier, -904);Теперь перехват этих ошибок в программе может производиться следующим образом:
WHEN dynsql.invalid identifier THEN ...Аналогичный подход рекомендуется использовать при работе с кодами ошибок –20NNN, передаваемыми процедуре RAISE_APPLICATION_ERROR (см. далее в этой заметке моего блога). Создайте пакет, в котором этим кодам будут присваиваться имена. Он может выглядеть примерно так:
PACKAGE errnums
IS
en_too_young CONSTANT NUMBER := -20001;
exc_too_young EXCEPTION;
PRAGMA EXCEPTION_INIT (exc_too_young, -20001);
en_sal_too_low CONSTANT NUMBER := -20002;
exc_sal_too_low EXCEPTION;
PRAGMA EXCEPTION_INIT (exc_sal_too_low , -20002);
END errnums;При наличии такого пакета можно использовать код следующего вида, не указывая номер ошибки в коде:
PROCEDURE validate_emp (birthdate_in IN DATE)
IS
min_years CONSTANT PLS_INTEGER := 18;
BEGIN
IF ADD_MONTHS (SYSDATE, min_years * 12 * -1) < birthdate_in
THEN
RAISE_APPLICATION_ERROR
(errnums.en_too_young,
'Возраст работника должен быть не менее ' || min_years || ' лет.');
END IF;
END;Именованные системные исключения
В Oracle для относительно небольшого количества исключений определены стандартные имена, задаваемые директивой компилятора EXCEPTION_INIT во встроенных пакетах. Самые важные и часто применяемые из них определены в пакете STANDARD. Так как это один из двух используемых по умолчанию пакетов PL/SQL, на определенные в нем исключения можно ссылаться без префикса с именем пакета. Например, если потребуется инициировать в программе исключение NO_DATA_FOUND, это можно сделать любой из следующих команд:
WHEN NO_DATA_FOUND THEN
WHEN STANDARD.NO_DATA_FOUND THENОпределения стандартных именованных исключений встречаются и в других встроенных пакетах — например, в пакете DBMS_LOB, предназначенном для работы с большими объектами. Пример одного такого определения из указанного пакета:
invalid_argval EXCEPTION;
PRAGMA EXCEPTION_INIT(invalid_argval, -21560);Поскольку пакет DBMS_LOB не используется по умолчанию, перед ссылкой на это исключение необходимо указать имя пакета:
WHEN DBMS_LOB.invalid_argval THEN... Многие исключения, определенные в пакете STANDARD, перечислены в табл. 1. Для каждого из них приводится номер ошибки Oracle, значение, возвращаемое при вызове SQLCODE (встроенная функция SQLCODE, которая возвращает текущий код ошибки — см. раздел «Встроенные функции ошибок»), и краткое описание. Значение, возвращаемое SQLCODE, совпадает с кодом ошибки Oracle, с одним исключением: определяемый стандартом ANSI код ошибки NO_DATA_FOUND равен 100.
| Имя исключения/Ошибка Oracle/SQLCODE | Описание |
| CURSOR_ALREADY_OPEN ORA-6511 SQLCODE = –6511 | Попытка открытия курсора, который был открыт ранее. Перед повторным открытием курсор необходимо сначала закрыть |
| DUP_VAL_ON_INDEX ORA-00001 SQLCODE = −1 | Команда INSERT или UPDATE пытается сохранить повторяющиеся значения в столбцах, объявленных с ограничением UNIQUE |
| INVALID_CURSOR ORA-01001 SQLCODE = −1001 | Ссылка на несуществующий курсор. Обычно ошибка встречается при попытке выборки данных из неоткрытого курсора или закрытия курсора до его открытия |
| INVALID_NUMBER ORA-01722 SQLCODE = −1722 | Выполняемая SQL-команда не может преобразовать символьную строку в число. Это исключение отличается от VALUE_ERROR тем, что оно инициируется только из SQL-команд |
| LOGIN_DENIED ORA-01017 SQLCODE = −1017 | Попытка программы подключиться к СУБД Oracle с неверным именем пользователя или паролем. Исключение обычно встречается при внедрении кода PL/SQL в язык 3GL |
| NO_DATA_FOUND ORA-01403 SQLCODE = +100 | Исключение инициируется в трех случаях: (1) при выполнении инструкции SELECT INTO (неявный курсор), которая не возвращает ни одной записи; (2) при ссылке на неинициализированную запись локальной таблицы PL/SQL; (3) при попытке выполнить операцию чтения после достижения конца файла при использовании пакета UTL_FILE |
| NOT_LOGGED ON ORA-01012 SQLCODE = −1012 | Программа пытается обратиться к базе данных (обычно из инструкции DML) до подключения к СУБД Oracle |
| PROGRAM_ERROR ORA-06501 SQLCODE = −6501 | Внутренняя программная ошибка PL/SQL. В сообщении об ошибке обычно предлагается обратиться в службу поддержки Oracle |
| STORAGE_ERROR ORA-06500 SQLCODE = −6500 | Программе PL/SQL не хватает памяти или память по какой-то причине повреждена |
| TIMEOUT_ON_RESOURCE ORA-00051 SQLCODE = −51 | Тайм-аут СУБД при ожидании ресурса |
| TOO_MANY_ROWS ORA-01422 SQLCODE = −1422 | Команда SELECT INTO возвращает несколько записей, хотя должна возвращать лишь одну (в таких случаях инструкция SELECT включается в явное определение курсора, а записи выбираются по одной) |
| TRANSACTION_BACKED_OUT ORA-00061 SQLCODE = −61 | Удаленная часть транзакции отменена либо при помощи явной инструкции ROLLBACK, либо в результате какого-то другого действия (например, неудачного выполнения команды SQL или DML в удаленной базе данных) |
| VALUE_ERROR ORA-06502 SQLCODE = −6502 | Ошибка связана с преобразованием, усечением или проверкой ограничений числовых или символьных данных. Это общее и очень распространенное исключение. Если подобная ошибка содержится в инструкции SQL или DML, то в блоке PL/SQL инициируется исключение INVALID_NUMBER |
| ZERO_DIVIDE ORA-01476 SQLCODE = −1476 | Попытка деления на ноль |
Рассмотрим пример использования этой таблицы исключений. Предположим, ваша программа инициирует необрабатываемое исключение для ошибки ORA-6511. Заглянув в таблицу, вы видите, что она связана с исключением CURSOR_ALREADY_OPEN. Найдите блок PL/SQL, в котором произошла ошибка, и добавьте в него обработчик исключения
CURSOR_ALREADY_OPEN:
EXCEPTION
WHEN CURSOR_ALREADY_OPEN
THEN
CLOSE my_cursor;
END;Конечно, еще лучше было бы проанализировать весь программный код и заранее определить, какие из стандартных исключений в нем могут инициироваться. В таком случае вы сможете решить, какие исключения следует обрабатывать конкретно, какие следует включить в конструкцию WHEN OTHERS (см. далее), а какие оставить необработанными.
Область действия исключения
Областью действия исключения называется та часть программного кода, к которой оно относится, то есть блок, где данное исключение может быть инициировано. В следующей таблице указаны области действия исключений четырех разных типов.
| Тип исключения | Область действия |
| Именованное системное исключение | Исключение является глобальным, то есть не ограничивается каким-то конкретным блоком кода. Системные исключения могут инициироваться и обрабатываться в любом блоке |
| Именованное исключение, определяемое программистом | Исключение может инициироваться и обрабатываться только в исполнительном разделе и разделе исключений, входящих в состав блока, где объявлено данное исключение (или в состав любого из вложенных в него блоков). Если исключение определено в спецификации пакета, то его областью действия являются все те программы, владельцы которых обладают для этого пакета привилегией EXECUTE |
| Анонимное системное исключение | Исключение может обрабатываться в секции WHEN OTHERS любого раздела исключений PL/SQL. Если присвоить ему имя, то его область действия будет такой же, как у именованного исключения, определяемого программистом |
| Анонимное исключение, определяемое программистом | Исключение определяется в вызове процедуры RAISE_APPLICATION_ERROR, а затем передается в вызывающую программу |
Рассмотрим пример исключения overdue_balance, объявленного в процедуре check_account (таким образом, область его действия ограничивается указанной процедурой):
PROCEDURE check_account (company_id_in IN NUMBER)
IS
overdue_balance EXCEPTION;
BEGIN
... исполняемые команды ...
LOOP
...
IF ... THEN
RAISE overdue_balance;
END IF;
END LOOP;
EXCEPTION
WHEN overdue_balance THEN ...
END;С помощью команды RAISE исключение overdue_balance можно инициировать в процедуре check_account, но не в программе, которая ее вызывает. Например, для следующего анонимного блока компилятор выдает ошибку:
DECLARE
company_id NUMBER := 100;
BEGIN
check_account (100);
EXCEPTION
WHEN overdue_balance /* В PL/SQL такая ссылка недопустима. */
THEN ...
END;
PLS-00201: identifier "OVERDUE_BALANCE" must be declaredДля приведенного выше анонимного блока процедура check_account является «черным ящиком». Все объявленные в ней идентификаторы, в том числе идентификаторы исключения, не видны для внешнего программного кода.
Инициирование исключений
Исключение может быть инициировано приложением в трех случаях:
- Oracle инициирует исключение при обнаружении ошибки;
- приложение инициирует исключение командой
RAISE; - исключение инициируется встроенной процедурой
RAISE_APPLICATION_ERROR.
Как Oracle инициирует исключения, вы уже знаете. Теперь давайте посмотрим, как это может сделать программист.
Команда RAISE
Чтобы программист имел возможность самостоятельно инициировать именованные исключения, в Oracle поддерживается команда RAISE. С ее помощью можно инициировать как собственные, так и системные исключения. Команда имеет три формы:
RAISE имя_исключения;
RAISE имя_пакета.имя_исключения;
RAISE;Первая форма (без имени пакета) может инициировать исключения, определенные в текущем блоке (или в содержащем его блоке), а также системные исключения, объявленные в пакете STANDARD. Далее приводятся два примера, в первом из которых инициируется исключение, определенное программистом:
DECLARE
invalid_id EXCEPTION; -- Все идентификаторы должны начинаться с буквы 'X'.
id_value VARCHAR2(30);
BEGIN
id_value := id_for ('SMITH');
IF SUBSTR (id_value, 1, 1) != 'X'
THEN
RAISE invalid_id;
END IF;
...
END;При необходимости вы всегда можете инициировать системное исключение:
BEGIN
IF total_sales = 0
THEN
RAISE ZERO_DIVIDE; -- Определено в пакете STANDARD
ELSE
RETURN (sales_percentage_calculation (my_sales, total_sales));
END IF;
END;Если исключение объявлено в пакете (но не в STANDARD) и инициируется извне, имя исключения необходимо уточнить именем пакета:
IF days_overdue (isbn_in, borrower_in) > 365
THEN
RAISE overdue_pkg.book_is_lost;
END IF; Третья форма RAISE не требует указывать имя исключения, но используется только в условии WHEN раздела исключений. Ее синтаксис предельно прост:
RAISE;Используйте эту форму для повторного инициирования (передачи) перехваченного исключения:
EXCEPTION
WHEN NO_DATA_FOUND
THEN
-- Используем общий пакет для сохранений всей контекстной
-- информации: код ошибки, имя программы и т. д.
errlog.putline (company_id_in);
-- А теперь исключение NO_DATA_FOUND передается
-- в родительский блок без обработки.
RAISE;Эта возможность особенно полезна в тех случаях, когда информацию об ошибке нужно записать в журнал, а сам процесс обработки возложить на родительский блок. Таким образом выполнение родительских блоков завершается без потери информации об ошибке.
Процедура RAISE_APPLICATION_ERROR
Для инициирования исключений, специфических для приложения, Oracle предоставляет процедуру RAISE_APPLICATION_ERROR (определенную в используемом по умолчанию пакете DBMS_STANDARD). Ее преимущество перед командой RAISE (которая тоже может инициировать специфические для приложения явно объявленные исключения) заключается в том, что она позволяет связать с исключением сообщение об ошибке.
При вызове этой процедуры выполнение текущего блока PL/SQL прекращается, а любые изменения аргументов OUT и IN OUT (если таковые имеются) отменяются. Изменения, внесенные в глобальные структуры данных (с помощью команды INSERT, UPDATE, MERGE или DELETE), такие как переменные пакетов и объекты баз данных, не отменяются. Для отката DML-команд необходимо явно указать в разделе обработки исключений команду ROLLBACK.
Заголовок этой процедуры (определяемый в пакете DBMS_STANDARD) выглядит так:
PROCEDURE RAISE_APPLICATION_ERROR (
num binary_integer,
msg varchar2,
keeperrorstack boolean default FALSE);Здесь num — номер ошибки из диапазона от –20 999 до –20 000 (только представьте: все остальные отрицательные числа Oracle резервирует для собственных исключений!); msg — сообщение об ошибке, длина которого не должна превышать 2048 символов (символы, выходящие за эту границу, игнорируются); аргумент keeperrorstack указывает, хотите ли вы добавить ошибку к уже имеющимся в стеке (TRUE), или заменить существующую ошибку (значение по умолчанию — FALSE).
Oracle выделяет диапазон номеров от –20 999 до –20 000 для пользовательских ошибок, но учтите, что в некоторых встроенных пакетах, в том числе в DBMS_OUTPUT и DBMS_DESCRIBE, номера от –20 005 до –20 000 все равно присваиваются системным ошибкам. За дополнительной информацией обращайтесь к документации пакетов.
Рассмотрим пример полезного применения этой встроенной процедуры. Допустим, мы хотим, чтобы сообщения об ошибках выдавались пользователям на разных языках. Создадим для них таблицу error_table и определим в ней язык каждого сообщения значением столбца string_language. Затем создается процедура, которая генерирует заданную ошибку, загружая соответствующее сообщение из таблицы с учетом языка текущего сеанса:
PROCEDURE raise_by_language (code_in IN PLS_INTEGER)
IS
l_message error_table.error_string%TYPE;
BEGIN
SELECT error_string
INTO l_message
FROM error_table
WHERE error_number = code_in
AND string_language = USERENV ('LANG');
RAISE_APPLICATION_ERROR (code_in, l_message);
END;Обработка исключений
Как только в программе возникает исключение, нормальное выполнение блока PL/SQL останавливается, и управление передается в раздел исключений. Затем исключение либо обрабатывается обработчиком исключений в текущем блоке PL/SQL, либо передается в родительский блок.
Чтобы обработать или перехватить исключение, нужно написать для него обработчик. Обработчики исключений располагаются после всех исполняемых команд блока, но перед завершающим ключевым словом END. Начало раздела исключений отмечает ключевое слово EXCEPTION:
DECLARE
... объявления ...
BEGIN
... исполняемые команды ...
[ EXCEPTION
... обработчики исключений ... ]
END;
Синтаксис обработчика исключений может быть таким:
WHEN имя_исключения [ OR имя_исключения ... ]
THEN
исполняемые команды
или таким:
WHEN OTHERS
THEN
исполняемые командыВ одном разделе исключений может быть несколько их обработчиков. Структура обработчиков напоминает структуру условной команды CASE.
| Свойство | Описание |
| EXCEPTION WHEN NO_DATA_FOUND THEN исполняемые_команды1; | Если инициировано исключение NO_DATA_FOUND, выполнить первый набор команд |
| WHEN payment_overdue THEN исполняемые_команды2; | Если просрочена оплата, выполнить второй набор команд |
| WHEN OTHERS THEN исполняемые_команды3; END; | Если инициировано иное исключение, выполнить третий набор команд |
Если имя, заданное в условии WHEN, совпадает с инициированным исключением, то это исключение обрабатывается соответствующим набором команд. Обратите внимание: исключения перехватываются по именам, а не по кодам ошибок. Но если инициированное исключение не имеет имени или его имя не соответствует ни одному из имен, указанных в условиях WHEN, тогда оно обрабатывается командами, заданными в секции WHEN OTHERS (если она имеется). Любая ошибка может быть перехвачена только одним обработчиком исключений. После выполнения команд обработчика управление сразу же передается из текущего блока в родительский или вызывающий блок.
Секция WHEN OTHERS не является обязательной. Когда она отсутствует, все необработанные исключения немедленно передаются в родительский блок, если таковой имеется. Секция WHEN OTHERS должна быть последним обработчиком исключений в блоке. Если разместить после нее еще одну секцию WHEN, компилятор выдаст сообщение об ошибке.
Встроенные функции ошибок
Прежде чем переходить к изучению тонкостей обработки ошибок, мы сначала вкратце познакомимся со встроенными функциями Oracle, предназначенными для идентификации, анализа и реагирования на ошибки, возникающие в приложениях PL/SQL.
SQLCODE
Функция SQLCODE возвращает код ошибки последнего исключения, инициированного в блоке. При отсутствии ошибок SQLCODE возвращает 0. Кроме того, SQLCODE возвращает 0 при вызове за пределами обработчика исключений.
База данных Oracle поддерживает стек значений SQLCODE. Допустим, к примеру, что функция FUNC инициирует исключение VALUE_ERROR (–6502). В разделе исключений FUNC вызывается процедура PROC, которая инициирует исключение DUP_VAL_ON_INDEX (–1). В разделе исключений PROC функция SQLCODE возвращает значение –1. Но когда управление передается в раздел исключений FUNC, SQLCODE будет возвращать –6502.
SQLERRM
Функция SQLERRM возвращает сообщение об ошибке для заданного кода ошибки. Если вызвать SQLERRM без указания кода ошибки, функция вернет сообщение, связанное со значением, возвращаемым SQLCODE. Например, если SQLCODE возвращает 0, функция SQLERRM вернет следующую строку:
ORA-0000: normal, successful completionЕсли же SQLCODE возвращает 1 (обобщенный код ошибки для исключения, определяемого пользователем), SQLERRM вернет строку:
User-Defined Exception
Пример вызова SQLERRM для получения сообщения об ошибке для конкретного кода:
1 BEGIN
2 DBMS_OUTPUT.put_line (SQLERRM (-1403));
3* END;
SQL> /
ORA-01403: no data foundМаксимальная длина строки, возвращаемой SQLERRM, составляет 512 байт (в некоторых ранних версиях Oracle — 255 байт). Из-за этого ограничения Oracle Corporation рекомендует вызывать функцию DBMS_UTILITY.FORMAT_ERROR_STACK, чтобы гарантировать вывод полной строки (эта встроенная функция не усекает текст до 2000 байт).
DBMS_UTILITY.FORMAT_ERROR_STACK
Эта встроенная функция, как и SQLERRM, возвращает сообщение, связанное с текущей ошибкой (то есть значение, возвращаемое SQLCODE). Ее отличия от SQLERRM:
- Она возвращает до 1899 символов сообщения, что позволяет избежать проблем с усечением.
- Этой функции не может передаваться код ошибки; соответственно, она не может использоваться для получения сообщения, соответствующего произвольному коду.
Как правило, эта функция вызывается в логике обработчика исключения для получения полного сообщения об ошибке.
Хотя в имя функции входит слово «stack», она не возвращает информацию о стеке ошибок, приведшем к строке, в которой изначально была инициирована ошибка. Эту задачу решает DBMS_UTILITY.FORMAT_ERROR_BACKTRACE.
DBMS_UTILITY.FORMAT_ERROR_BACKTRACE
Эта функция, появившаяся в Oracle10g, возвращает отформатированную строку с содержимым стека программ и номеров строк. Ее выходные данные позволяют отследить строку, в которой изначально была инициирована ошибка.
Тем самым заполняется весьма существенный пробел в функциональности PL/SQL. В Oracle9i и предшествующих версиях после обработки исключения в блоке PL/ SQL было невозможно определить строку, в которой произошла ошибка (возможно, самая важная информация для разработчика). Если программист хотел получить эту информацию, он должен был разрешить прохождение необработанного исключения, чтобы полная трассировочная информация ошибки была выведена на экран. Ситуация более подробно описана в следующем разделе.
DBMS_UTILITY.FORMAT_CALL_STACK
Функция возвращает отформатированную строку со стеком вызовов в приложении PL/SQL. Практическая полезность функции не ограничивается обработкой ошибок; она также пригодится для трассировки выполнения вашего кода.
В Oracle Database 12c появился пакет UTL_CALL_STACK, который также предоставляет доступ к стеку вызовов, стеку ошибок и информации обратной трассировки.
Подробнее о DBMS_UTILITY.FORMAT_ERROR_BACKTRACE
Функцию DBMS_UTILITY.FORMAT_ERROR_BACKTRACE следует вызывать в обработчике исключения. Она выводит содержимое стека выполнения в точке инициирования исключения. Таким образом, вызов DBMS_UTILITY.FORMAT_ERROR_BACKTRACE в разделе исключений на верхнем уровне стека позволит узнать, где именно в стеке вызовов произошла ошибка. Рассмотрим следующий сценарий: мы определяем процедуру proc3, которая вызывает процедуру proc2, а последняя, в свою очередь, вызывает proc1. Процедура proc1 инициирует исключение:
CREATE OR REPLACE PROCEDURE proc1 IS
BEGIN
DBMS_OUTPUT.put_line ('выполнение proc1');
RAISE NO_DATA_FOUND;
END;
/
CREATE OR REPLACE PROCEDURE proc2 IS
l_str VARCHAR2 (30) := 'вызов proc1';
BEGIN
DBMS_OUTPUT.put_line (l_str);
proc1;
END;
/
CREATE OR REPLACE PROCEDURE proc3 IS
BEGIN
DBMS_OUTPUT.put_line ('вызов proc2');
proc2;
EXCEPTION
WHEN OTHERS
THEN
DBMS_OUTPUT.put_line ('Стек ошибок верхнего уровня:');
DBMS_OUTPUT.put_line (DBMS_UTILITY.format_error_backtrace);
END;
/Единственной программой с обработчиком ошибок является внешняя процедура proc3. Вызов функции трассировки включен в обработчик WHEN OTHERS процедуры proc3. При выполнении этой процедуры будет получен следующий результат:
SQL> SET SERVEROUTPUT ON
SQL> BEGIN
2 DBMS_OUTPUT.put_line ('Proc3 -> Proc2 -> Proc1 backtrace');
3 proc3;
4 END;
5 /
Proc3 -> Proc2 -> Proc1 backtrace
вызов proc2
вызов proc1
выполнение proc1
Error stack at top level:
ORA-06512: at "SCOTT.PROC1", line 4
ORA-06512: at "SCOTT.PROC2", line 5
ORA-06512: at "SCOTT.PROC3", line 4Как видите, функция трассировки выводит в начале стека номер строки proc1, в которой произошла исходная ошибка.
Часто исключение происходит где-то в глубине стека вызовов. Если вы хотите, чтобы оно было передано во внешний блок PL/SQL, вероятно, вам придется заново инициировать его в каждом обработчике стека блоков. Функция DBMS_UTILITY.FORMAT_ERROR_BACKTRACE выдает трассировку исполнения вплоть до последней команды RAISE в сеансе пользователя. Учтите, что вызов RAISE для конкретного исключения или повторное инициирование текущего исключения приводит к инициализации стека, выдаваемого DBMS_UTILITY.FORMAT_ERROR_BACKTRACE. Таким образом, если вы хотите использовать эту функцию, возможны два пути:
- Вызовите функцию в разделе исключений блока, в котором была инициирована ошибка. Это позволит вам получить (и сохранить в журнале) номер ошибки, даже если исключение было заново инициировано в дальнейшей позиции стека.
- Обойдите обработчики исключений в промежуточных программах вашего стека и вызовите функцию в разделе исключений внешней программы в стеке.
Только номер строки, пожалуйста
В реальном приложении трассировка ошибок может быть очень длинной. Как правило, специалиста, занимающегося отладкой или поддержкой, не интересует весь стек — достаточно только последнего элемента. Возможно, разработчику приложения стоит вывести эту важную информацию, чтобы пользователь мог немедленно и точно описать суть проблемы группе поддержки.
В такой ситуации необходимо разобрать строку с данными трассировки и извлечь из нее последний элемент. Я написал для этого специальную программу и оформил ее в пакет BT. В этом пакете реализован простой, понятный интерфейс:
PACKAGE bt
IS
TYPE error_rt IS RECORD (
program_owner all_objects.owner%TYPE
, program_name all_objects.object_name%TYPE
, line_number PLS_INTEGER
);
FUNCTION info (backtrace_in IN VARCHAR2)
RETURN error_rt;
PROCEDURE show_info (backtrace_in IN VARCHAR2);
END bt;Тип записи error_rt содержит отдельное поле для каждого возвращаемого элемента трассировки (владелец программного модуля, имя программного модуля и номер строки в программе). Затем вместо того, чтобы вызывать функцию трассировки в каждом разделе исключения и разбирать ее результаты, я вызываю функцию bt.info и вывожу конкретную информацию об ошибке.
Полезные применения SQLERRM
Вы можете использовать DBMS_UTILITY.FORMAT_ERROR_STACK вместо SQLERRM, но это не означает, что функция SQLERRM совершенно неактуальна. В частности, она поможет вам получить ответ на следующие вопросы:
- Является ли заданное число действительным кодом ошибки Oracle?
- Какое сообщение соответствует коду ошибки?
Как упоминалось ранее в нашей статье, функция SQLERRM возвращает сообщение об ошибке для заданного кода. Но если передать SQLERRM недействительный код, исключение не инициируется. Вместо этого возвращается строка в одном из двух форматов:
- Если число отрицательно:
ORA-NNNNN: Message NNNNN not found; product=RDBMS; facility=ORA
- Если число положительно или меньше −65535:
-N: non-ORACLE exception
Этим обстоятельством можно воспользоваться для построения функций, возвращающих точную информацию о том коде, с которым вы работаете в настоящее время. Ниже приведена спецификация пакета с этими программами:
PACKAGE oracle_error_info
IS
FUNCTION is_app_error (code_in IN INTEGER)
RETURN BOOLEAN;
FUNCTION is_valid_oracle_error (
code_in IN INTEGER
, app_errors_ok_in IN BOOLEAN DEFAULT TRUE
, user_error_ok_in IN BOOLEAN DEFAULT TRUE
)
RETURN BOOLEAN;
PROCEDURE validate_oracle_error (
code_in IN INTEGER
, message_out OUT VARCHAR2
, is_valid_out OUT BOOLEAN
, app_errors_ok_in IN BOOLEAN DEFAULT TRUE
, user_error_ok_in IN BOOLEAN DEFAULT TRUE
);
END oracle_error_info;Объединение нескольких исключений в одном обработчике
В одном условии WHEN можно оператором OR объединить несколько исключений — подобно тому, как этим оператором объединяются логические выражения:
WHEN invalid_company_id OR negative_balance
THENВ одном обработчике также можно комбинировать имена пользовательских и системных исключений:
WHEN balance_too_low OR ZERO_DIVIDE OR DBMS_LDAP.INVALID_SESSION
THEN Впрочем, применять оператор AND в такой комбинации нельзя, потому что в любой момент времени может быть инициировано только одно исключение.
 PL/SQL")
Необработанные исключения
Исключение, инициированное в программе, но не обработанное в соответствующем разделе текущего или родительского блока PL/SQL, называется необработанным. PL/ SQL возвращает сообщение об ошибке, вызвавшей необработанное исключение, в ту среду, где была запущена данная программа. Эта среда (ею может быть SQL*Plus. Oracle Forms, программа на языке Java и т. д.) действует по ситуации. В частности, SQL*Plus осуществляет откат всех DML-инструкций, выполненных в родительском блоке.
Одним из важнейших моментов, связанных с проектированием архитектуры приложения, является вопрос о том, разрешается ли в нем использовать необработанные исключения. Такие исключения разными средами обрабатываются по-разному, и не всегда это делается корректно. Если ваша программа PL/SQL вызывается не из PL/SQL-среды, в ее «самом внешнем» блоке можно запрограммировать следующие действия:
- перехват всех исключений, которые могли быть переданы до текущей точки;
- запись информации об ошибке в журнал, с тем чтобы впоследствии ее мог проанализировать разработчик;
- возврат кода состояния, описания и другой информации, необходимой управляющей среде для выбора оптимального варианта действий.
Передача необработанного исключения
Блок, в котором может быть инициировано исключение, определяется правилами области действия исключений. В программе инициированное исключение распространяется в соответствии с определенными правилами.
Сначала PL/SQL ищет обработчик исключения в текущем блоке (анонимном блоке, процедуре или функции). Если такового нет, исключение передается в родительский блок. Затем PL/SQL пытается обработать исключение, инициировав его еще раз в родительском блоке. И так происходит в каждом внешнем по отношению к другому блоке до тех пор, пока все они не будут исчерпаны (рис. 2). После этого PL/SQL возвращает необработанное исключение в среду приложения, выполнившего «самый внешний» блок PL/SQL. И только теперь исключение может прервать выполнение основной программы.

Рис. 2. Передача исключений во вложенных блоках PL/SQL
Потеря информации об исключении
Структура процесса обработки локальных, определяемых программистом исключений в PL/SQL такова, что можно легко потерять информацию об исключении (то есть о том, какая именно произошла ошибка). Пример:
BEGIN
<<local_block>>
DECLARE
case_is_not_made EXCEPTION;
BEGIN
...
END local_block;Допустим, мы забыли включить в этот блок раздел исключений. Область действия исключения case_is_not_made ограничена блоком local_block. Если исключение не обрабатывается в данном блоке, оно передается в родительский, где нет никакой информации о нем. Известно только то, что произошла ошибка, а какая именно — неизвестно. Ведь все пользовательские исключения имеют один и тот же номер ошибки 1 и одно и то же сообщение «User Defined Exception» — если только вы не воспользуетесь директивой EXCEPTION_INIT, чтобы связать с объявленным исключением другой номер, и не присвоите ему другое сообщение об ошибке при вызове RAISE_APPLICATION_ERROR.
Таким образом, локально объявленные (и инициированные) исключения всегда следует обрабатывать по имени.
Примеры передачи исключения
Рассмотрим несколько примеров передачи исключений через внешние блоки. На рис. 3 показано, как исключение too_many_faults, инициированное во внутреннем блоке, обрабатывается в следующем — внешнем — блоке. Внутренний блок содержит раздел исключений, так что PL/SQL сначала проверяет, обрабатывается ли в этом разделе инициированное исключение too_many_faults.

Рис. 3. Передача исключений во вложенных блоках PL/SQL
А поскольку оно не обрабатывается, PL/SQL закрывает этот блок и инициирует исключение too_many_faults во внешнем блоке, обозначенном на рисунке как вложенный блок 1. (Используемые команды, расположенные после вложенного блока 2, не выполняются.) Затем просматривается раздел исключений этого блока с целью поиска обработчика исключения too_many_faults, который обрабатывает его и передает управление процедуре list_my_faults.
Обратите внимание: если исключение NO_DATA_FOUND будет инициировано в «самом внутреннем» блоке, то оно будет обработано в разделе исключений этого же блока. Затем управление передается во вложенный блок 1 и будут выполнены исполняемые команды, расположенные после вложенного блока 2.
На рис. 4 представлен пример обработки в «самом внешнем» блоке исключения, инициированного во внутреннем блоке. В изображенной ситуации раздел исключений присутствует только во внешнем блоке, поэтому когда во вложенном блоке 2 инициируется исключение too_many_faults, PL/SQL прекращает выполнение этого блока и инициирует данное исключение в его родительском блоке, то есть вложенном блоке 1. Но поскольку и у него нет раздела исключений, управление передается «самому внешнему» блоку, процедуре list_my_faults. В этой процедуре имеется раздел исключений, поэтому PL/ SQL проверяет его, находит обработчик исключения too_many_faults, выполняет имеющийся там код и передает управление программе, вызвавшей процедуру list_my_faults.

Рис. 4. Исключение, инициированное во вложенном блоке,
обрабатывается в «самом внешнем» блоке
Продолжение выполнения после исключений
Когда в блоке PL/SQL инициируется исключение, нормальная последовательность выполнения программы прерывается, а управление передается в раздел исключений. Вернуться к исполняемому разделу блока после возникновения в нем исключения уже не удастся. Впрочем, в некоторых ситуациях требуется именно это — продолжить выполнение программы после обработки исключения.
Рассмотрим следующий сценарий: требуется написать процедуру, которая применяет серию операций DML к разным таблицам (удаление из одной таблицы, обновление другой, вставка в последнюю таблицу). На первый взгляд код мог бы выглядеть примерно так:
PROCEDURE change_data IS
BEGIN
DELETE FROM employees WHERE ... ;
UPDATE company SET ... ;
INSERT INTO company_history SELECT * FROM company WHERE ... ;
END;Безусловно, процедура содержит все необходимые команды DML. Однако одно из требований к программе заключается в том, что при последовательном выполнении этих команд они должны быть логически независимы друг от друга. Другими словами, даже если при выполнении DELETE произойдет сбой, программа должна выполнить UPDATE и INSERT.
В текущей версии change_data ничто не гарантирует, что программа хотя бы попытается выполнить все три операции DML. Если при выполнении DELETE произойдет исключение, например, то выполнение всей программы прервется, а управление будет передано в раздел исключений (если он имеется). Остальные команды SQL при этом выполняться не будут.
Как обеспечить обработку исключения без прерывания программы? Для этого DELETE следует поместить в собственный блок PL/SQL. Рассмотрим следующую версию программы change_data:
PROCEDURE change_data
IS
BEGIN
BEGIN
DELETE FROM employees WHERE ... ;
EXCEPTION
WHEN OTHERS THEN log_error;
END;
BEGIN
UPDATE company SET ... ;
EXCEPTION
WHEN OTHERS THEN log_error;
END;
BEGIN
INSERT INTO company_history SELECT * FROM company WHERE ... ;
EXCEPTION
WHEN OTHERS THEN log_error;
END;
END;В новом варианте программы, если при выполнении DELETE произойдет исключение, управление немедленно передается в раздел исключений. Но поскольку команда DELETE теперь находится в собственном блоке, она может иметь собственный раздел исключений. Условие WHEN OTHERS этого раздела обрабатывает ошибку без повторного инициирования этой или другой ошибки, после чего управление возвращается за пределы блока DELETE внешней процедуре change_data. Так как «активное» исключение отсутствует, выполнение продолжается во внешнем блоке со следующей команды процедуры. Программа входит в новый анонимный блок для команды UPDATE. Если при выполнении UPDATE произойдет ошибка, она будет перехвачена условием WHEN OTHERS раздела исключений UPDATE. Далее управление будет возвращено процедуре change_data, которая перейдет к выполнению команды INSERT (также содержащейся в собственном блоке).
На рис. 5 показано, как выполняется этот процесс для двух последовательно выполняемых команд DELETE.

Рис. 5. Последовательное выполнение DELETE с разными областями действия
Подведем итог: исключение, инициированное в исполняемом разделе, всегда обрабатывается в текущем блоке (при наличии подходящего обработчика). Любую команду можно заключить в «виртуальный блок», заключив ее между ключевыми словами BEGIN и END с определением раздела EXCEPTION. Это позволяет ограничить область действия сбоев в программе посредством определения «буферных» анонимных блоков.
Эту стратегию можно развить с выделением изолируемого кода в отдельные процедуры и функции. Конечно, именованные блоки PL/SQL тоже могут иметь собственные разделы исключений и предоставлять ту же защиту от общих сбоев. Важнейшее преимущество процедур и функций заключается в том, что они скрывают все команды BEGIN-EXCEPTION-END от основной программы. Программа лучше читается, код проще сопровождать и повторно использовать в других контекстах.
Существуют и другие способы продолжить выполнение после исключения DML — например, можно использовать конструкцию SAVE EXCEPTIONS с FORALL и LOG ERRORS в сочетании с DBMS_ERRORLOG.
Написание раздела WHEN OTHERS
Условие WHEN OTHERS включается в раздел исключений для перехвата всех исключений, не обработанных предшествующими обработчиками. Так как конкретный тип исключения изначально неизвестен, в WHEN OTHERS очень часто используются встроенные функции для получения информации о возникшей ошибке (такие, как SQLCODE и DBMS_UTILITY. FORMAT_ERROR_STACK).
В сочетании с WHEN OTHERS функция SQLCODE представляет средства для обработки разных видов исключений без применения директивы EXCEPTION_INIT. В следующем примере перехватываются два исключения категории «родитель/потомок», −1 и −2292, и для каждой ситуации выполняется подходящее действие:
PROCEDURE add_company (
id_in IN company.ID%TYPE
, name_in IN company.name%TYPE
, type_id_in IN company.type_id%TYPE
)
IS
BEGIN
INSERT INTO company (ID, name, type_id)
VALUES (id_in, name_in, type_id_in);
EXCEPTION
WHEN OTHERS
THEN
/*
|| Анонимный блок в обработчике исключения позволяет объявить
|| локальные переменные для хранения информации о кодах ошибок.
*/
DECLARE
l_errcode PLS_INTEGER := SQLCODE;
BEGIN
CASE l_errcode
WHEN −1 THEN
-- Дублирующееся значение уникального индекса. Повторяется либо
-- первичный ключ, либо имя. Сообщить о проблеме
-- и инициировать исключение заново.
DBMS_OUTPUT.put_line
( 'идентификатор или имя компании уже используется. ID = '
|| TO_CHAR (id_in)
|| ' name = '
|| name_in
);
RAISE;
WHEN −2291 THEN
-- Родительский ключ не найден. Сообщить о проблеме
-- и инициировать исключение заново.
DBMS_OUTPUT.put_line (
'Недопустимый идентификатор типа компании: ' || TO_CHAR (type_id_in));
RAISE;
ELSE
RAISE;
END CASE;
END; -- Конец анонимного блока.
END add_company;Будьте осторожны при использовании WHEN OTHERS — этот раздел способен «поглощать» ошибки, скрывая их от внешних блоков и пользователя. А точнее, обращайте внимание на обработчики WHEN OTHERS, которые не инициируют текущее исключение заново и не заменяют его другим исключением. Если WHEN OTHERS не передает исключение наружу, внешние блоки вашей программы не узнают о возникшей ошибке.
В Oracle Database 11g появилось новое предупреждение, которое помогает выявлять программы, игнорирующие ошибки или поглощающие их:
PLW-06009: procedure "string" OTHERS handler does not end in RAISE or RAISE_
APPLICATION_ERRORПример использования этого предупреждения:
SQL> ALTER SESSION SET plsql_warnings = 'enable:all'
2 /
SQL> CREATE OR REPLACE PROCEDURE plw6009_demo
2 AS
3 BEGIN
4 DBMS_OUTPUT.put_line ('I am here!');
5 RAISE NO_DATA_FOUND;
6 EXCEPTION
7 WHEN OTHERS
8 THEN
9 NULL;
10 END plw6009_demo;
11 /
SP2-0804: Procedure created with compilation warnings
SQL> SHOW ERRORS
Errors for PROCEDURE PLW6009_DEMO:
LINE/COL ERROR
-------- -----------------------------------------------------------------
7/9 PLW-06009: procedure "PLW6009_DEMO" OTHERS handler does not end
in RAISE or RAISE_APPLICATION_ERROR Построение эффективной архитектуры управления ошибками
Механизм инициирования и обработки ошибок в PL/SQL отличается мощью и гибкостью, но он не лишен недостатков, которые могут создать проблемы для групп разработки, желающих реализовать надежную, последовательную, содержательную архитектуру управления ошибками. В частности, вы столкнетесь со следующими проблемами:
EXCEPTION— особая разновидность структуры данных PL/SQL. Переменные, объявленные с типомEXCEPTION, можно только инициировать и обрабатывать. Исключение нельзя передать в аргументе программы, с ним нельзя связать дополнительные атрибуты.- Повторное использование кода обработки исключений сильно затруднено. Из предыдущего пункта непосредственно следует другой факт: раз исключение нельзя передать в аргументе, разработчику приходится копировать код обработчика — конечно, такой способ написания кода никак не назовешь оптимальным.
- Не существует формализованного способа объявления исключений, которые могут инициироваться программой. Например, в Java эта информация становится частью спецификации программы. Как следствие, разработчику приходится обращаться к коду реализации и искать в нем информацию о потенциальных исключениях — или же надеяться на лучшее.
- Oracle не предоставляет средств организации и классификации исключений, относящихся к конкретному приложению, а просто резервирует (в основном) 1000 кодов в диапазоне от −20 999 до −20 000. Управлять этими значениями должен сам разработчик.
Давайте посмотрим, как преодолеть большинство из перечисленных трудностей.
Определение стратегии управления ошибками
Очень важно, чтобы еще до написания кода была выработана последовательная стратегия и архитектура обработки ошибок в приложении. Вот лишь некоторые вопросы, на которые необходимо ответить для этого:
- Как и когда сохранять информацию об ошибках для последующего просмотра и исправления? Куда выводить информацию — в файл, в таблицу базы данных? выводить на экран?
- Как и где сообщать об ошибках пользователю? Какую информацию должен получать пользователь? Как «перевести» часто невразумительные сообщения об ошибках, выдаваемые базой данных, на язык, понятный пользователям?
С этими общими вопросами тесно связаны более конкретные проблемы:
- Следует ли включать раздел обработки исключений в каждый блок PL/SQL?
- Следует ли включать раздел обработки исключений только в блок верхнего уровня или внешние блоки?
- Как организовать управление транзакциями при возникновении ошибок? Сложность обработки исключений отчасти связана с тем, что на все эти вопросы не существует единственно правильного ответа. Все зависит (по крайней мере частично) от архитектуры приложения и режима его использования (например, пакетное выполнение или транзакции, управляемые пользователем). Но если вы сможете ответить на эти вопросы для своего приложения, я рекомендую «запрограммировать» стратегию и правила обработки ошибок в стандартном пакете (см. далее «Стандартизация обработки ошибок»).
Некоторые общие принципы, которые стоит принять во внимание:
- Когда в коде происходит ошибка, получите как можно больше информации о контексте ее возникновения. Избыток информации — лучше, чем ее нехватка. Далее исключение можно передавать во внешние блоки, собирая дополнительную информацию по мере продвижения.
- Избегайте применения обработчиков вида
WHENошибкаTHEN NULL; (или еще хуже,WHEN OTHERS THEN NULL;). Возможно, для написания такого хода у вас имеются веские причины, но вы должны твердо понимать, что это именно то, что вам нужно, и документировать такое использование, чтобы о нем знали другие. - Там, где это возможно, используйте механизмы обработки ошибок PL/SQL по умолчанию. Избегайте написания программ, возвращающих коды состояния управляющей среде или вызывающим блокам. Применять коды состояния следует только в одной ситуации: если управляющая среда не способна корректно обрабатывать ошибки Oracle (в таком случае стоит подумать о смене управляющей среды!).
Стандартизация обработки разных типов исключений
Исключение всегда свидетельствует о критической ситуации? Вовсе нет. Некоторые исключения (например, ORA-00600) сообщают о том, что в базе данных возникли очень серьезные низкоуровневые проблемы. Другие исключения, такие как NO_DATA_FOUND, встречаются так часто, что мы воспринимаем их не как ошибки, а как условную логическую конструкцию («Если строка не существует, то выполнить следующие действия…»). Нужно ли различать эти категории исключений?
Коллеги-программисты научил меня очень полезной системе классификации исключений.
- Преднамеренные исключения. Архитектура кода сознательно использует особенности работы исключения. Это означает, что разработчик должен предвидеть исключение и запрограммировать его обработку. Пример —
UTL_FILE.GET_LINE. - Нежелательные исключения. Происходит ошибка, но ее возможность была предусмотрена заранее. Возможно, исключение даже не свидетельствует о возникновении проблемы. Пример команда
SELECT INTO, инициирующая исключениеNO_DATA_FOUND. - Непредвиденные исключения. Серьезные ошибки, указывающие на возникновение проблемы в приложении. Пример — команда
SELECT INTO, которая должна вернуть строку для заданного первичного ключа, но вместо этого инициирует исключениеTOO_MANYROWS.
Давайте поближе познакомимся с примерами всех категорий, а затем поговорим о том, какую пользу вы можете извлечь из знания этих категорий.
Преднамеренные исключения
Разработчики PL/SQL могут использовать процедуру UTL_FILE.GET_LINE для чтения содержимого файла по строкам. Когда GET_LINE выходит за границу файла, инициируется исключение NO_DATA_FOUND. Так работает эта процедура. Итак, если я хочу прочитать все содержимое файла и сделать «что-то полезное», программа может выглядеть так:
PROCEDURE read_file_and_do_stuff (
dir_in IN VARCHAR2, file_in IN VARCHAR2
)
IS
l_file UTL_FILE.file_type;
l_line VARCHAR2 (32767);
BEGIN
l_file := UTL_FILE.fopen (dir_in, file_in, 'R', max_linesize => 32767);
LOOP
UTL_FILE.get_line (l_file, l_line);
do_stuff;
END LOOP;
EXCEPTION
WHEN NO_DATA_FOUND
THEN
UTL_FILE.fclose (l_file);
more_stuff_here;
END;У этого цикла есть одна особенность: он не содержит команды EXIT. Кроме того, в разделе исключений выполняется дополнительная логика приложения (more_stuff_here). Цикл можно переписать в следующем виде:
LOOP
BEGIN
UTL_FILE.get_line (l_file, l_line);
do_stuff;
EXCEPTION
WHEN NO_DATA_FOUND
THEN
EXIT;
END;
END LOOP;
UTL_FILE.flcose (l_file);
more_stuff_here;Теперь цикл содержит команду EXIT, но код стал более громоздким.
Подобные конструкции приходится использовать при работе с кодом, намеренно инициирующем исключения в своей архитектуре. Дополнительная информация о том, как следует поступать в подобных случаях, приводится в следующих разделах.
Нежелательные и непредвиденные исключения
Я рассматриваю эти две категории вместе, потому что приводимые примеры (NO_DATA_FOUND и TOO_MANY_ROWS) тесно связаны между собой. Предположим, я хочу написать функцию, возвращающую полное имя работника (в формате фамилия запятая имя) для заданного значения первичного ключа. Проще всего это сделать так:
FUNCTION fullname (
employee_id_in IN employees.employee_id%TYPE
)
RETURN VARCHAR2
IS
retval VARCHAR2 (32767);
BEGIN
SELECT last_name || ',' || first_name
INTO retval
FROM employees
WHERE employee_id = employee_id_in;
RETURN retval;
END fullname;Если вызвать эту программу с кодом работника, отсутствующим в таблице, база данных инициирует исключение NO_DATA_FOUND. Если же вызвать ее с кодом работника, встречающимся в нескольких строках таблицы, будет инициировано исключение TOO_MANY_ROWS. Один запрос, два разных исключения — нужно ли рассматривать их одинаково? Вероятно, нет. Описывают ли эти два исключения похожие группы проблем? Давайте посмотрим:
NO_DATA_FOUND— совпадение не найдено. Исключение может указывать на наличие серьезной проблемы, но не обязательно. Возможно, в большинстве обращений к базе данных совпадение не будет обнаруживаться, и я буду вставлять в базу данные нового работника. В общем, исключение нежелательно, но в данном случае оно даже не указывает на возникновение ошибки.TOO_MANY_ROWS— в базе данных возникла серьезная проблема с ограничением первичного ключа. Трудно представить себе ситуацию, в которой это было бы нормально или просто «нежелательно». Нет, нужно прервать работу программы и привлечь внимание пользователя к совершенно непредвиденной, критической ошибке.
Как извлечь пользу из этой классификации
Надеюсь, вы согласитесь, что такая классификация полезна. Приступая к построению нового приложения, постарайтесь по возможности определиться со стандартным подходом, который будет применяться вами (и всеми остальными участниками группы) для каждого типа исключений. Затем для каждого исключения (которое необходимо обработать или хотя бы учитывать заранее при написании кода) решите, к какой категории относится, и примените уже согласованный подход. Все это поможет сделать ваш код более последовательным, и повысит эффективность вашей работы. Приведу несколько рекомендаций для трех типов исключений.
- Преднамеренные исключения. Пишите код, учитывающий возможность возникновения таких исключений. Прежде всего постарайтесь избежать размещения логики приложения в разделе исключений. Раздел исключений должен содержать только код, относящийся к обработке ошибки: сохранение информации об ошибке в журнале, повторное инициирование исключения и т. д. Программисты не ожидают увидеть логику приложения в разделе исключений, поэтому им будет намного труднее разобраться в таком коде и обеспечить его сопровождение.
- Нежелательные исключения. Если в каких-то обстоятельствах пользователь кода, инициировавшего исключения, не будет интерпретировать ситуацию как ошибку, не передавайте исключения наружу без обработки. Вместо этого верните значение или флаг состояния, показывающий, что исключение было обработано. Далее пользователь программы может сам решить, должна ли программа завершиться с ошибкой. А еще лучше — почему бы не разрешить стороне, вызывающей вашу программу, решить, нужно ли инициировать исключение, и если не нужно — какое значение должно передаваться для обозначения возникшего исключения?
- Непредвиденные исключения. А теперь начинается самое неприятное. Все непредвиденные ошибки должны быть сохранены в журнале с максимумом возможной контекстной информации, которая поможет понять причины возникновения ошибки. Затем программа должна завершиться с необработанным исключением (обычно тем же), инициированным из программы; для этого можно воспользоваться командой
RAISE. Исключение заставит вызвавшую программу прервать работу и обработать ошибку.
Коды ошибок, связанные с конкретным приложением
Используя команду RAISE_APPLICATION_ERROR для инициирования ошибок, относящихся к конкретному приложению, вы несете полную ответственность за управление кодами ошибок и сообщениями. Это быстро становится хлопотным и непростым делом («Так, какой бы код мне выбрать? Пожалуй, –20 774 — вроде бы такого еще не было?»).
Чтобы упростить управление кодами ошибок и предоставить последовательный интерфейс, через который разработчики смогут обрабатывать серверные ошибки, постройте таблицу со всеми используемыми кодами ошибок −20 NNN, сопутствующими именами исключений и сообщениями об ошибках.
Разработчик может просмотреть уже определенные ошибки на экране и выбрать ту из них, которая лучше всего подходит для конкретной ситуации.
Также можно попытаться полностью избегать диапазон −20 NNN для ошибок приложений. Почему бы не воспользоваться положительными числами? Из положительного цело-численного поддиапазона Oracle использует только 1 и 100. Теоретически возможно, что когда-нибудь Oracle будет использовать и другие положительные числа, но это весьма маловероятно. В распоряжении разработчиков остается великое множество кодов ошибок.
В частности, я пошел по этому пути при проектировании Quest Error Manager (QEM) — бесплатной программы управления ошибками. В Quest Error Manager вы можете определять свои ошибки в специальной таблице. Ошибка определяется именем и/ или кодом. Коды ошибок могут быть положительными или отрицательными. Если код ошибки положителен, при инициировании исключения QEM использует команду RAISE_APPLICATION_ERROR для инициирования обобщенного исключения (обычно −20 000). Информация о текущем коде ошибки приложения встраивается в сообщение об ошибке, которое может быть расшифровано программой-получателем.
Упрощенная реализация этого подхода представлена в пакете обработки ошибок errpkg. pkg, описанном в следующем разделе блога.
Стандартизация обработки ошибок
Обязательным элементом любого профессионально написанного приложения является надежная и согласованная схема обработки ошибок. Согласованность в этом вопросе важна как для пользователя, так и для разработчика. Если при возникновении ошибки пользователю предоставляется понятная, хорошо структурированная информация, он сможет более подробно рассказать об ошибке службе поддержки и будет более уверенно чувствовать себя при работе с приложением. Если приложение всегда обрабатывает и протоколирует ошибки определенным образом, программистам, занимающимся его поддержкой и сопровождением, будет легче их найти и устранить.
Все кажется вполне очевидным, не так ли? К сожалению, на практике (и особенно в больших группах разработчиков) все происходит несколько иначе. Очень часто каждый разработчик идет своим путем, следуя личным принципам и приемам, сохраняя информацию в произвольно выбранном формате и т. д. Одним словом, без стандартизации отладка и сопровождение приложений оборачиваются сущим кошмаром. Рассмотрим типичный пример:
EXCEPTION
WHEN NO_DATA_FOUND
THEN
v_msg := 'Нет компании с идентификатором '||TO_CHAR (v_id);
v_err := SQLCODE;
v_prog := 'fixdebt';
INSERT INTO errlog VALUES
(v_err,v_msg,v_prog,SYSDATE,USER);
WHEN OTHERS
THEN
v_err := SQLCODE;
v_msg := SQLERRM;
v_prog := 'fixdebt';
INSERT INTO errlog VALUES
(v_err,v_msg,v_prog,SYSDATE,USER);
RAISE;На первый взгляд код выглядит вполне разумно. Если компания с заданным идентификатором не найдена, мы получаем значение SQLCODE, задаем имя программы и сообщение и записываем строку с информацией об ошибке в таблицу ошибок. Выполнение родительского блока продолжается, поскольку ошибка не критична. Если происходит любая другая ошибка, получаем ее код и соответствующее сообщение, задаем имя программы и записываем строку с информацией об ошибке в таблицу ошибок, а затем передаем исключение в родительский блок, чтобы остановить его выполнение (поскольку неизвестно, насколько критична эта ошибка).
Что же здесь не так? Чтобы подробно объяснить суть проблемы, достаточно взглянуть на код. В нем жестко закодированы все действия по обработке ошибок. В результате (1) код получается слишком объемистым, (2) его придется полностью переписывать при изменении схемы обработки ошибок. Обратите внимание еще и на тот факт, что информация об ошибке записывается в таблицу базы данных. Это означает, что запись в журнале становится частью логической транзакции. И если потребуется выполнить откат транзакции, записи в журнале ошибок будут утеряны.
Существует несколько способов избежать потери информации: можно записывать данные в файл или использовать автономные транзакции для сохранения журнала вне основной транзакции. Но как бы то ни было, код в случае его изменения придется исправлять в сотнях разных мест.
А теперь посмотрите, как этот же раздел исключений оформляется при использовании стандартизированного пакета:
EXCEPTION
WHEN NO_DATA_FOUND
THEN
errpkg.record_and_continue (
SQLCODE, 'Нет компании с идентификатором ' || TO_CHAR (v_id));
WHEN OTHERS
THEN
errpkg.record_and_stop;
END;Такой пакет обработки ошибок скрывает все подробности реализации; вы просто решаете, какая из процедур-обработчиков должна использоваться в конкретном случае, просматривая спецификацию пакета. Если требуется сохранить информацию об ошибке и продолжить работу, вызывается программа record_and_continue. Если же нужно сохранить информацию об ошибке и прервать выполнение родительского блока, вызывается программа record_and_stop. Мы не знаем, как эти программы сохраняют информацию об ошибке, как они останавливают работу родительского блока, то есть передают исключение, но для нас это и не важно. Главное, что все происходит так, как определено стандартами приложения.
Это дает вам возможность уделить больше времени разработке более интересных элементов приложения и не заниматься административной рутиной.
Имеется файл errpkg.pkg с прототипом стандартизированного пакета обработки ошибок. Правда, прежде чем использовать его в приложениях, вам необходимо будет завершить его реализацию; это поможет составить ясное представление о том, как конструируются подобные утилиты.
Вы также можете воспользоваться намного более мощным (и тоже бесплатным) средством обработки ошибок Quest Error Manager. Важнейшая концепция, заложенная в основу QEM, заключается в возможности перехвата и протоколирования экземпляров ошибок, не только ошибок Oracle. QEM состоит из пакета PL/SQL и четырех таблиц для хранения информации об ошибках, возникающих в приложениях.
Работа с «объектами» исключений
Реализация типа данных EXCEPTION в Oracle имеет свои ограничения, о которых было рассказано выше. Исключение состоит из идентификатора (имени), с которым связывается числовой код и сообщение. Исключение можно инициировать, его можно обработать… и все. Теперь представьте, как та же ситуация выглядит в Java: все ошибки являются производными от единого класса Exception. Этот класс можно расширить, дополняя его новыми характеристиками, которые вы хотите отслеживать (стек ошибок, контекстные данные и т. д.). Объект, созданный на основе класса Exception, ничем не отличается от любых других объектов Java. Разумеется, он может передаваться в аргументах методов.
PL/SQL не позволяет делать ничего подобного со своими исключениями. Впрочем, этот факт не мешает вам реализовать свой «объект» исключения. Для этого можно воспользоваться объектными типами Oracle или реляционной таблицей, содержащей информацию об ошибке. Независимо от выбранной реализации очень важно различать определение ошибки (код ошибки –1403, имя «данные не найдены», причина — «неявный курсор не нашел ни одной записи») и ее конкретный экземпляр (я попытался найти компанию с указанным именем, ни одной строки не найдено). Иначе говоря, существует всего одно определение исключения NO_DATA_FOUND, которое может существовать во множестве экземпляров. Oracle не различает эти два представления ошибки, но для нас это безусловно необходимо.
Пример простой иерархии объектов исключений продемонстрирует этот момент. Начнем с базового объектного типа всех исключений:
CREATE TYPE exception_t AS OBJECT (
name VARCHAR2(100),
code INTEGER,
description VARCHAR2(4000),
help_text VARCHAR2(4000),
recommendation VARCHAR2(4000),
error_stack CLOB,
call_stack CLOB,
created_on DATE,
created_by VARCHAR2(100)
)
NOT FINAL;
/Затем базовый тип исключения расширяется для ошибок динамического SQL посредством добавления атрибута sql_string. При обработке ошибок динамического SQL очень важно сохранить строку, создавшую проблемы, для анализа в будущем:
CREATE TYPE dynsql_exception_t UNDER exception_t (
sql_string CLOB )
NOT FINAL;
/А вот другой подтип exception_t, на этот раз относящийся к конкретной сущности приложения — работнику. Исключение, инициируемое для ошибок, относящихся к работникам, будет включать идентификатор работника и внешний ключ нарушенного правила:
CREATE TYPE employee_exception_t UNDER exception_t (
employee_id INTEGER,
rule_id INTEGER );
/Полная спецификация иерархии объектов ошибок включает методы супертипа исключения, предназначенные для вывода информации об ошибках или ее записи в репозиторий. Вы можете самостоятельно завершить иерархию, определенную в файле exception.ot.
Если вы не хотите работать с объектными типами, попробуйте использовать подход, использованный мной в QEM: я определяю таблицу определений ошибок (Q$ERROR) и другую таблицу экземпляров ошибок (Q$ERROR_INSTANCE), которая содержит информацию о конкретных экземплярах ошибок. Все контекстные данные экземпляра ошибки сохраняются в таблице Q$ERROR_CONTEXT.
Пример кода, который мог бы быть написан для QEM API:
WHEN DUP_VAL_ON_INDEX
THEN
q$error_manager.register_error (
error_name_in => 'DUPLICATE-VALUE'
,err_instance_id_out => l_err_instance_id
);
q$error_manager.add_context (
err_instance_id_in => l_err_instance_id
,name_in => 'TABLE_NAME', value_in => 'EMPLOYEES'
);
q$error_manager.add_context (
err_instance_id_in => l_err_instance_id
,name_in => 'KEY_VALUE', value_in => l_employee_id
);
q$error_manager.raise_error_instance (
err_instance_id_in => l_err_instance_id);
END;Если ошибка повторяющегося значения была вызвана ограничением уникального имени, я получаю идентификатор экземпляра ошибки DUPLICATE-VALUE. (Да, все верно: я использую имена ошибок, полностью обходя все проблемы, связанные с номерами ошибок.) Затем я добавляю контекстную информацию экземпляра (имя таблицы и значение первичного ключа, вызвавшее проблему). В завершение инициируется экземпляр ошибки, в результате чего исключение передается в следующий наружный блок.
По аналогии с передачей данных из приложения в репозиторий ошибок через API, вы также можете получить информацию об ошибке при помощи процедуры get_error_info.
Пример:
BEGIN
run_my_application_code;
EXCEPTION
WHEN OTHERS
THEN
DECLARE
l_error q$error_manager.error_info_rt;
BEGIN
q$error_manager.get_error_info (l_error);
DBMS_OUTPUT.put_line ('');
DBMS_OUTPUT.put_line ('Error in DEPT_SAL Procedure:');
DBMS_OUTPUT.put_line ('Code = ' || l_error.code);
DBMS_OUTPUT.put_line ('Name = ' || l_error.NAME);
DBMS_OUTPUT.put_line ('Text = ' || l_error.text);
DBMS_OUTPUT.put_line ('Error Stack = ' || l_error.error_stack);
END;
END;Это лишь два из многих способов преодоления ограничений типа EXCEPTION в PL/SQL. Мораль: ничто не заставляет вас мириться с ситуацией по умолчанию, при которой с экземпляром ошибки связывается только код и сообщение.
Создание стандартного шаблона для обобщенной обработки ошибок
Невозможность передачи исключений программе сильно усложняет совместное использование разделов обработки ошибок в разных блоках PL/SQL. Одну и ту же логику обработчика нередко приходится записывать снова и снова, особенно при работе с конкретными функциональными областями — скажем, файловым вводом/ выводом с UTL_FILE. В таких ситуациях стоит выделить время на создание шаблонов обработчиков.
Давайте поближе познакомимся с UTL_FILE. До выхода Oracle9i Database Release 2 в спецификации пакета UTL_FILE определялся набор исключений. Однако компания Oracle не стала предоставлять коды этих исключений через директиву EXCEPTION_INIT. А без обработки исключений UTL_FILE по имени SQLCODE не сможет разобраться, что пошло не так. Вероятно, в такой ситуации для программ UTL_FILE можно создать шаблон, часть которого выглядит так:
DECLARE
l_file_id UTL_FILE.file_type;
PROCEDURE cleanup (file_in IN OUT UTL_FILE.file_type
,err_in IN VARCHAR2 := NULL)
IS
BEGIN
UTL_FILE.fclose (file_in);
IF err_in IS NOT NULL
THEN
DBMS_OUTPUT.put_line ('Обнаружена ошибка UTL_FILE:');
DBMS_OUTPUT.put_line (err_in);
END IF;
END cleanup;
BEGIN
-- Здесь размещается тело программы.
-- Перед выходом необходимо прибрать за собой ...
cleanup (l_file_id);
EXCEPTION
WHEN UTL_FILE.invalid_path
THEN
cleanup (l_file_id, 'invalid_path');
RAISE;
WHEN UTL_FILE.invalid_mode
THEN
cleanup (l_file_id, 'invalid_mode');
RAISE;
END;Основные элементы шаблона:
- Программа выполнения завершающих действий, пригодная для повторного использования; гарантирует, что текущий файл будет закрыт до потери дескриптора файла.
- Преобразование именованного исключения в строку, которую можно сохранить в журнале или вывести на экран, чтобы пользователь точно знал, какая ошибка была инициирована.
Рассмотрим еще один пример шаблона, который удобно использовать при работе с UTL_FILE. В Oracle9i Database Release 2 появилась программа FREMOVE для удаления файлов. Пакет UTL_FILE предоставляет исключение DELETE_FAILED, инициируемое тогда, когда FREMOVE не удается удалить файл. После тестирования программы я обнаружил, что FREMOVE может инициировать несколько возможных исключений, в числе которых:
UTL_FILE.INVALID_OPERATION— удаляемый файл не существует.UTL_FILE.DELETE_FAILED— у вас (или у процесса Oracle) недостаточно привилегий для удаления файла, или попытка завершилась неудачей по другой причине.
Начиная с Oracle9i Database Release 2, UTL_FILE назначает коды ошибок всем своим исключениям, но вы все равно должны проследить за тем, чтобы при возникновении ошибки файлы были закрыты, и организовать последовательную обработку ошибок.
Итак, при использовании UTL_FILE.FREMOVE следует включать раздел обработчика исключения, который различает эти две ошибки:
BEGIN
UTL_FILE.fremove (dir, filename);
EXCEPTION
WHEN UTL_FILE.delete_failed
THEN
DBMS_OUTPUT.put_line (
'Ошибка при попытке удаления: ' || filename || ' в ' || dir);
-- Выполнение соответствующих действий...
WHEN UTL_FILE.invalid_operation
THEN
DBMS_OUTPUT.put_line (
'Не удалось найти и удалить: ' || filename || ' в ' || dir);
-- Выполнение соответствующих действий...
END;Оптимальная организация обработки ошибок в PL/SQL
Без унифицированной качественной методологии обработки ошибок очень трудно написать приложение, которое было бы удобным в использовании и одновременно простым в отладке.
Архитектура обработки ошибок в Oracle PL/SQL предоставляет очень гибкие средства для определения, инициирования и обработки ошибок. Однако у нее имеются свои ограничения, вследствие чего встроенную функциональность обычно приходится дополнять таблицами и кодами ошибок, специфическими для конкретного приложения.
Для решения проблемы обработки ошибок рекомендуется предпринять следующие действия:
- Тщательно разберитесь в системе инициирования и обработки ошибок в PL/SQL. Далеко не во ее аспекты интуитивно понятны. Простейший пример: исключение, инициированное в секции объявлений, не будет обрабатываться секцией исключений текущего блока.
- Выберите общую схему обработки ошибок в вашем приложении. Где и как будут обрабатываться ошибки? Какая информация об ошибке будет сохраняться и как это будет сделано? Как исключения будут передаваться в управляющую среду? Как будут обрабатываться намеренные и непредвиденные ошибки?
- Постройте стандартную инфраструктуру, которая будет использоваться всеми разработчиками проекта. Инфраструктура должна включать таблицы, пакеты и, возможно, объектные типы, а также четко определенный процесс использования всех перечисленных элементов. Не останавливайтесь на ограничениях PL/ SQL. Найдите обходные пути, расширяя модель обработки ошибок.
- Создайте шаблоны, которые могут использоваться всеми участниками вашей группы. Всегда проще следовать готовому стандарту, чем самостоятельно писать код обработки ошибок.
Жду отклика на статью. Что понравилось? Что нет?
Вас заинтересует / Intresting for you:
Эта глава посвящена обработке исключительных ситуаций. Исключительная ситуация (или исключение) — это ошибка, которая возникает во время выполнения программы. Используя С++-подсистему обработки исключительных ситуаций, с такими ошибками вполне можно справляться. При их возникновении во время работы программы автоматически вызывается так называемый обработчик исключений. Теперь программист не должен обеспечивать проверку результата выполнения каждой конкретной операции или функции вручную. В этом-то и состоит принципиальное преимущество системы обработки исключений, поскольку именно она «отвечает» за код обработки ошибок, который прежде приходилось «вручную» вводить в и без того объемные программы.
В этой главе мы также возвращаемся к С++-операторам динамического распределения памяти: new и delete. Как разъяснялось выше в этой книге, если оператор new не может выделить требуемую память, он генерирует исключение. И здесь мы узнаем, как именно обрабатывается такое исключение. Кроме того, вы научитесь перегружать операторы new и delete, что позволит вам определять собственные схемы выделения памяти.
Основы обработки исключительных ситуаций
Обработка исключений — это системные средства, с помощью которых программа может справиться с ошибками времени выполнения.
Управление С++-механизмом обработки исключений зиждется на трех ключевых словах: try, catch и throw. Они образуют взаимосвязанную подсистему, в которой использование одного из них предполагает применение другого. Для начала будет полезно получить общее представление о роли, которую они играют в обработке исключительных ситуаций. Если кратко, то их работа состоит в следующем. Программные инструкции, которые вы считаете нужным проконтролировать на предмет исключений, помещаются в try-блок. Если исключение (т.е. ошибка) таки возникает в этом блоке, оно дает знать о себе выбросом определенного рода информации (с помощью ключевого слова throw). Это выброшенное исключение может быть перехвачено программным путем с помощью catch-блока и обработано соответствующим образом. А теперь подробнее.
Инструкция throw генерирует исключение, которое перехватывается catchинструкцией.
Итак, код, в котором возможно возникновение исключительных ситуаций, должен выполняться в рамках try-блока. (Любая функция, вызываемая из этого try-блока, также подвергается контролю.) Исключения, которые могут быть выброшены контролируемым кодом, перехватываются catch-инструкцией, непосредственно следующей за try-блоком, в котором фиксируются эти «выбросы» исключений. Общий формат try— и catch-блоков выглядит так.
try {
// try-блок (блок кода, подлежащий проверке на наличие ошибок)
}
catch (type1 arg) {
// catch-блок (обработчик исключения типа type1)
}
catch {type2 arg) {
// catch-блок (обработчик исключения типа type2)
}
catch {type3 arg) {
// catch-блок (обработчик исключения типа type3)
}
// …
catch (typeN arg) {
// catch-блок (обработчик исключения типа typeN)
}
Блок try должен содержать код, который, по вашему мнению, должен проверяться на предмет возникновения ошибок. Этот блок может включать лишь несколько инструкций некоторой функции либо охватывать весь код функции main() (в этом случае, по сути, «под колпаком» системы обработки исключений будет находиться вся программа).
После «выброса» исключение перехватывается соответствующей инструкцией catch, которая выполняет его обработку. С одним try-блоком может быть связана не одна, а несколько catch-инструкций. Какая именно из них будет выполнена, определяется типом исключения. Другими словами, будет выполнена та catch-инструкция, тип исключения которой (т.е. тип данных, заданный в catch-инструкции) совпадает с типом сгенерированного исключения (а все остальные будут проигнорированы). После перехвата исключения параметр arg примет его значение. Таким путем могут перехватываться данные любого типа, включая объекты классов, созданных программистом.
Чтобы исключение было перехвачено, необходимо обеспечить его «выброс» в try-блоке.
Общий формат инструкции throw выглядит так:
throw exception;
Здесь с помощью элемента exception задается исключение, сгенерированное инструкцией throw. Если это исключение подлежит перехвату, то инструкция throw должна быть выполнена либо в самом блоке try, либо в любой вызываемой из него функции (т.е. прямо или косвенно).
На заметку. Если в программе обеспечивается «выброс» исключения, для которого не предусмотрена соответствующая catch-инструкция, произойдет аварийное завершение программы, вызываемое стандартной библиотечной функцией terminate(). По умолчанию функция terminate() вызывает функцию abort() для остановки программы, но при желании можно определить собственный обработчик ее завершения. За подробностями относительно обработки этой ситуации следует обратиться к документации, прилагаемой к вашему компилятору.
Рассмотрим простой пример обработки исключений средствами языка C++.
// Простой пример обработки исключений.
#include <iostream>
using namespace std;
int main()
{
cout << «HAЧAЛОn»;
try {
// начало try-блока
cout << «В trу-блокеn»;
throw 99; // генерирование ошибки
cout << «Эта инструкция не будет выполнена.»;
}
catch (int i) {
// перехват ошибки
cout << «Перехват исключения. Его значение равно: «;
cout << i << «n»;
}
cout << «КОНЕЦ»;
return 0;
}
При выполнении эта программа отображает следующие результаты.
НАЧАЛО В try-блоке
Перехват исключения. Его значение равно: 99
КОНЕЦ
Рассмотрим внимательно код этой программы. Как видите, здесь try-блок содержит три инструкции, а инструкция catch(int i) предназначена для обработки исключения целочисленного типа. В этом try-блоке выполняются только две из трех инструкций: cout и throw. После генерирования исключения управление передается catch-выражению, при этом выполнение try-блока прекращается. Необходимо понимать, что catch-инструкция не вызывается, а просто с нее продолжается выполнение программы после «выброса» исключения. (Стек программы автоматически настраивается в соответствии с создавшейся ситуацией.) Поэтому cout-инструкция, следующая после throw-инструкции, никогда не выполнится.
После выполнения catch-блока управление программой передается инструкции, следующей за этим блоком. Поэтому ваш обработчик исключения должен исправить ошибку, вызвавшую его возникновение, чтобы программа могла нормально продолжить выполнение. В случаях, когда ошибку исправить нельзя, catch-блок обычно завершается обращением к функциям exit() или abort(). (Функции exit() и abort() описаны в разделе «Копнем глубже» ниже в этой главе.)
Как упоминалось выше, тип исключения должен совпадать с типом, заданным в catch— инструкции. Например, если в предыдущей программе тип int, указанный в catch— выражении, заменить типом double, то исключение перехвачено не будет, и произойдет аварийное завершение программы. Вот как выглядят последствия внесения такого изменения.
// Этот пример работать не будет.
#include <iostream>
using namespace std;
int main()
{
cout << «НАЧАЛОn»;
try {
// начало try-блока
cout << «В trу-блокеn»;
throw 99; // генерирование ошибки
cout << «Эта инструкция не будет выполнена.»;
}
catch (double i) {
// Перехват исключения типа int не состоится.
cout << «Перехват исключения. Его значение равно: «;
cout << i << «n»;
}
cout << «КОНЕЦ»;
return 0;
}
Такие результаты выполнения этой программы объясняются тем, что исключение целочисленного типа не перехватывается инструкцией catch (double i).
НАЧАЛО
В try-блоке
Abnormal program termination
Функции exit() и abort()
Функции exit() и abort() входят в состав стандартной библиотеки C++ и часто используются в программировании на C++. Обе они обеспечивают завершение программы, но по-разному.
Вызов функции exit() немедленно приводит к «правильному» прекращению программы. («Правильное» окончание означает выполнение стандартной последовательности действий по завершению работы.) Обычно этот способ завершения работы используется для остановки программы при возникновении неисправимой ошибки, которая делает дальнейшее ее выполнение бессмысленным или опасным. Для использования функции exit() требуется включить в программу заголовок <cstdlib>. Ее прототип выглядит так.
void exit(int status);
Поскольку функция exit() вызывает немедленное завершение программы, она не передает управление вызывающему процессу и не возвращает никакого значения. Тем не менее вызывающему процессу в качестве кода завершения передается значение параметра status. По соглашению нулевое значение параметра status говорит об успешном окончании работы программы. Любое другое его значение свидетельствует о завершении программы по ошибке. Для индикации успешного окончания можно также использовать константу EXIT_SUCCESS, а для индикации ошибки— константу EXIT_FAILURE. Эти константы определены в заголовке <cstdlib>.
Прототип функции abort() выглядит так:
void abort();
Аналогично exit() функция abort() вызывает немедленное завершение программы. Но в отличие от функции exit() она не возвращает операционной системе никакой информации о статусе завершения и не выполняет стандартной («правильной») последовательности действий при остановке программы. Для использования функции abort() требуется включить в программу заголовок <cstdlib>. Функцию abort() можно назвать аварийным «стоп-краном» для С++-программы. Ее следует использовать только после возникновения неисправимой ошибки.
Последнее сообщение об аварийном завершении программы (Abnormal program termination) может отличаться от приведенного в результатах выполнения предыдущего примера. Это зависит от используемого вами компилятора.
Исключение, сгенерированное функцией, вызванной из try-блока, может быть перехвачено этим же try-блоком. Рассмотрим, например, следующую вполне корректную программу.
/* Генерирование исключения из функции, вызываемой из try-блока.
*/
#include <iostream>
using namespace std;
void Xtest(int test)
{
cout << «В функции Xtest(), значение test равно: «<< test << «n»;
if(test) throw test;
}
int main()
{
cout << «НАЧАЛОn»;
try {
// начало try-блока
cout << «В trу-блокеn»;
Xtest (0);
Xtest (1);
Xtest (2);
}
catch (int i) {
// перехват ошибки
cout << «Перехват исключения. Его значение равно: «;
cout << i << «n»;
}
cout << «КОНЕЦ»;
return 0;
}
Эта программа генерирует такие результаты.
НАЧАЛО В try-блоке
Вфункции Xtest(), значение test равно: 0
Вфункции Xtest(), значение test равно: 1
Перехват исключения. Его значение равно: 1
КОНЕЦ
Блок try может быть локализован в рамках функции. В этом случае при каждом ее выполнении запускается и обработка исключений, связанная с этой функцией. Рассмотрим следующую простую программу.
#include <iostream>
using namespace std;
/* Функционирование блоков try/catch возобновляется при каждом входе в функцию.
*/
void Xhandler(int test)
{
try {
if(test) throw test;
}
catch(int i) {
cout << «Перехват! Исключение №: » << i << ‘n’;
}
}
int main()
{
cout << «HAЧАЛОn «;
Xhandler (1);
Xhandler (2);
Xhandler (0);
Xhandler (3);
cout << «КОНЕЦ»;
return 0;
}
При выполнении этой программы отображаются такие результаты.
НАЧАЛО
Перехват! Исключение №:1
Перехват! Исключение №:2
Перехват! Исключение №:3
КОНЕЦ
Как видите, программа сгенерировала три исключения. После каждого исключения функция Xhandler() передавала управление в функцию main(). Когда она снова вызывалась, возобновлялась и обработка исключения.
В общем случае try-блок возобновляет свое функционирование при каждом входе в него. Поэтому try-блок, который является частью цикла, будет запускаться при каждом повторении этого цикла.
Перехват исключений классового типа
Исключение может иметь любой тип, в том числе и тип класса, созданного программистом. В реальных программах большинство исключений имеют именно тип класса, а не встроенный тип. Вероятно, тип класса больше всего подходит для описания ошибки, которая потенциально может возникнуть в программе. Как показано в следующем примере, информация, содержащаяся в объекте класса исключений, позволяет упростить обработку исключений.
// Использование класса исключений.
#include <iostream>
#include <cstring>
using namespace std;
class MyException {
public:
char str_what[80];
MyException() { *str_what =0; }
MyException(char *s) { strcpy(str_what, s);}
};
int main()
{
int a, b;
try {
cout << «Введите числитель и знаменатель: «;
cin >> а >> b;
if( !b) throw MyException(«Делить на нуль нельзя!»);
else
cout << «Частное равно » << a/b << «n»;
}
catch (MyException e) {
// перехват ошибки
cout << e.str_what << «n»;
}
return 0;
}
Вот один из возможных результатов выполнения этой программы.
Введите числитель и знаменатель: 10 0
Делить на нуль нельзя!
После запуска программы пользователю предлагается ввести числитель и знаменатель. Если знаменатель равен нулю, создается объект класса MyException, который содержит информацию о попытке деления на нуль. Таким образом, класс MyException инкапсулирует информацию об ошибке, которая затем используется обработчиком исключений для уведомления пользователя о случившемся.
Безусловно, реальные классы исключений гораздо сложнее класса MyException. Как правило, создание классов исключений имеет смысл в том случае, если они инкапсулируют информацию, которая бы позволила обработчику исключений эффективно справиться с ошибкой и по возможности восстановить работоспособность программы.
Использование нескольких catch-инструкций
Как упоминалось выше, с try-блоком можно связывать не одну, а несколько catch— инструкций. В действительности именно такая практика и является обычной. Но при этом все catch-инструкции должны перехватывать исключения различных типов. Например, в приведенной ниже программе обеспечивается перехват как целых чисел, так и указателей на символы.
#include <iostream>
using namespace std;
// Здесь возможен перехват исключений различных типов.
void Xhandler(int test)
{
try {
if(test) throw test;
else throw «Значение равно нулю.»;
}
catch (int i) {
cout << «Перехват! Исключение №: » << i << ‘n’;
}
catch(char *str) {
cout << «Перехват строки: «;
cout << str << ‘n’;
}
}
int main()
{
cout << «НАЧАЛОn»;
Xhandler(1);
Xhandler(2);
Xhandler(0);
Xhandler(3);
cout << «КОНЕЦ»;
return 0;
}
Эта программа генерирует такие результаты.
НАЧАЛО
Перехват! Исключение №: 1
Перехват! Исключение №: 2
Перехват строки: Значение равно нулю.
Перехват! Исключение №: 3
КОНЕЦ
Как видите, каждая catch-инструкция отвечает только за исключение «своего» типа. В общем случае catch-выражения проверяются в порядке следования, и выполняется только тот catch-блок, в котором тип заданного исключения совпадает с типом сгенерированного исключения. Все остальные catch-блоки игнорируются.
Перехват исключений базового класса
Важно понимать, как выполняются catch-инструкции, связанные с производными классами. Дело в том, что catch-выражение для базового класса «отреагирует совпадением» на исключение любого производного типа (т.е. типа, выведенного из этого базового класса). Следовательно, если нужно перехватывать исключения как базового, так и производного типов, в catch-последовательности catch-инструкцию для производного типа необходимо поместить перед catch-инструкцией для базового типа. В противном случае catch— выражение для базового класса будет перехватывать (помимо «своих») и исключения всех производных классов. Рассмотрим, например, следующую программу:
// Перехват исключений базовых и производных типов.
#include <iostream>
using namespace std;
class В {
};
class D: public В {
};
int main()
{
D derived;
try {
throw derived;
}
catch(B b) {
cout << «Перехват исключения базового класса.n»;
}
catch(D d) {
cout << «Этот перехват никогда не произойдет.n»;
}
return 0;
}
Поскольку здесь объект derived — это объект класса D, который выведен из базового класса В, то исключение типа derived будет всегда перехватываться первым catch— выражением; вторая же catch-инструкция при этом никогда не выполнится. Одни компиляторы отреагируют на такое положение вещей предупреждающим сообщением. Другие могут выдать сообщение об ошибке. В любом случае, чтобы исправить ситуацию, достаточно поменять порядок следования этих catch-инструкций на противоположный.
Варианты обработки исключений
Помимо рассмотренных, существуют и другие С++-средства обработки исключений, которые создают определенные удобства для программистов. О них и пойдет речь в этом разделе.
Перехват всех исключений
Иногда имеет смысл создать обработчик для перехвата всех исключений, а не исключений только определенного типа. Для этого достаточно использовать такой формат catch-блока.
catch (…) {
// Обработка всех исключений
}
Здесь заключенное в круглые скобки многоточие обеспечивает совпадение с любым типом данных.
Использование формата catch(…) иллюстрируется в следующей программе.
// В этой программе перехватываются исключения всех типов.
#include <iostream>
using namespace std;
void Xhandler(int test)
{
try {
if(test==0) throw test; // генерирует int-исключение
if(test==1) throw ‘a’; // генерирует char-исключение
if(test==2) throw 123.23; // генерирует double-исключение
}
catch (…) { // перехват всех исключений
cout << «Перехват!n»;
}
}
int main()
{
cout << «НАЧАЛОn»;
Xhandler (0);
Xhandler (1);
Xhandler (2);
cout << «КОНЕЦ»;
return 0;
}
Эта программа генерирует такие результаты.
НАЧАЛО
Перехват!
Перехват!
Перехват!
КОНЕЦ
Как видите, все три throw-исключения перехвачены с помощью одной-единственной
catch-инетрукции.
Зачастую имеет смысл использовать инструкцию catch(…) в качестве последнего «рубежа» catch-последовательности. В этом случае она обеспечивает перехват исключений «всех остальных» типов (т.е. не предусмотренных предыдущими catch-выражениями). Например, рассмотрим еще одну версию предыдущей программы, в которой явным образом обеспечивается перехват исключений целочисленного типа, а перехват всех остальных возможных исключений «взваливается на плечи» инструкции catch(…).
/* Использование формата catch (…) в качестве варианта «все остальное».
*/
#include <iostream>
using namespace std;
void Xhandler(int test)
{
try {
if(test==0) throw test; // генерирует int-исключение
if(test==1) throw ‘a’; // генерирует char-исключение
if(test==2) throw 123.23; // генерирует double-исключение
}
catch(int i) {
// перехватывает int-исключение
cout << «Перехват » << i << ‘n’;
}
catch(…) {
// перехватывает все остальные исключения
cout << «Перехват-перехват!n»;
}
}
int main()
{
cout << «НАЧАЛОn»;
Xhandler(0);
Xhandler(1);
Xhandler(2);
cout << «КОНЕЦ»;
return 0;
}
Результаты, сгенерированные при выполнении этой программы, таковы.
НАЧАЛО
Перехват 0
Перехват-перехват!
Перехват-перехват!
КОНЕЦ
Как подтверждает этот пример, использование формата catch(…) в качестве «последнего оплота» catch-последовательности— это удобный способ перехватить все исключения, которые вам не хочется обрабатывать в явном виде. Кроме того, перехватывая абсолютно все исключения, вы предотвращаете возможность аварийного завершения программы, которое может быть вызвано каким-то непредусмотренным (а значит, необработанным) исключением.
Ограничения, налагаемые на тип исключений, генерируемых функциями
Существуют средства, которые позволяют ограничить тип исключений, которые может генерировать функция за пределами своего тела. Можно также оградить функцию от генерирования каких бы то ни было исключений вообще. Для формирования этих ограничений необходимо внести в определение функции throw-выражение. Общий формат определения функции с использованием throw-выражения выглядит так.
тип имя_функции(список_аргументов) throw(список_имен_типов)
{
// . . .
}
Здесь элемент список_имен_типов должен включать только те имена типов данных, которые разрешается генерировать функции (элементы списка разделяются запятыми). Генерирование исключения любого другого типа приведет к аварийному окончанию программы. Если нужно, чтобы функция вообще не могла генерировать исключения, используйте в качестве этого элемента пустой список.
На заметку. При попытке сгенерировать исключение, которое не поддерживается функцией, вызывается стандартная библиотечная функция unexpected(). По умолчанию она вызывает функцию abort(), которая обеспечивает аварийное завершение программы. Но при желании можно задать собственный обработчик процесса завершения. За подробностями обращайтесь к документации, прилагаемой к вашему компилятору.
На примере следующей программы показано, как можно ограничить типы исключений, которые способна генерировать функция.
/* Ограничение типов исключений, генерируемых функцией.
*/
#include <iostream>
using namespace std;
/* Эта функция может генерировать исключения только типа int, char и double.
*/
void Xhandler(int test) throw(int, char, double)
{
if(test==0) throw test; // генерирует int-исключение
if(test==1) throw ‘a’; // генерирует char-исключение
if(test==2) throw 123.23; // генерирует double-исключение
}
int main()
{
cout << «НАЧАЛОn»;
try {
Xhandler(0); // Попробуйте также передать функции Xhandler() аргументы 1 и 2.
}
catch(int i) {
cout << «Перехват int-исключения.n»;
}
catch(char c) {
cout << «Перехват char-исключения.n»;
}
catch(double d) {
cout << «Перехват double-исключения.n»;
}
cout << «КОНЕЦ»;
return 0;
}
В этой программе функция Xhandler() может генерировать исключения только типа int, char и double. При попытке сгенерировать исключение любого другого типа произойдет аварийное завершение программы (благодаря вызову функции unexpected()). Чтобы убедиться в этом, удалите из throw-списка, например, тип int и перезапустите программу.
Важно понимать, что диапазон исключений, разрешенных для генерирования функции, можно ограничивать только типами, генерируемыми ею в try-блоке, из которого была вызвана. Другими словами, любой try-блок, расположенный в теле самой функции, может генерировать исключения любого типа, если они перехватываются в теле той же функции. Ограничение применяется только для ситуаций, когда «выброс» исключений происходит за пределы функции.
Следующее изменение помешает функции Xhandler() генерировать любые изменения.
// Эта функция вообще не может генерировать исключения!
void Xhandler(int test) throw()
{
/* Следующие инструкции больше не работают. Теперь они могут вызвать лишь аварийное завершение программы. */
if(test==0) throw test;
if(test==1) throw ‘a’;
if(test==2) throw 123.23;
}
На заметку. На момент написания этой книги среда Visual C++ не обеспечивала для функции запрет генерировать исключения, тип которых не задан в throw-выражении. Это говорит о нестандартном поведении данной среды. Тем не менее вы все равно можете задавать «ограничивающее» throw-выражение, но оно в этом случае будет играть лишь уведомительную роль.
Повторное генерирование исключения
Для того чтобы повторно сгенерировать исключение в его обработчике, воспользуйтесь throw-инструкцией без указания типа исключения. В этом случае текущее исключение будет передано во внешнюю try/catch-последовательность. Чаще всего причиной для такого выполнения инструкции throw служит стремление позволить доступ к одному исключению нескольким обработчикам. Например, первый обработчик исключений будет сообщать об
одном аспекте исключения, а второй — о другом. Исключение можно повторно сгенерировать только в catch-блоке (или в любой функции, вызываемой из этого блока). При повторном генерировании исключение не будет перехватываться той же catch-инструкцией. Оно распространится на ближайшую try/catch-последовательность.
Повторное генерирование исключения демонстрируется в следующей программе (в данном случае повторно генерируется тип char *).
// Пример повторного генерирования исключения.
#include <iostream>
using namespace std;
void Xhandler()
{
try {
throw «Привет»; // генерирует исключение типа char *
}
catch(char *) { // перехватывает исключение типа char *
cout << «Перехват исключения в функции Xhandler.n»;
throw; // Повторное генерирование исключения типа char *, которое будет перехвачено вне функции Xhandler.
}
}
int main()
{
cout << «НАЧАЛОn»;
try {
Xhandler();
}
catch(char *) {
cout << «Перехват исключения в функции main().n»;
}
cout << «КОНЕЦ»;
return 0;
}
При выполнении эта программа генерирует такие результаты.
НАЧАЛО
Перехват исключения в функции Xhandler.
Перехват исключения в функции main().
КОНЕЦ
Обработка исключений, сгенерированных оператором new
В главе 9 вы узнали, что оператор new генерирует исключение, если не удается удовлетворить запрос на выделение памяти. Поскольку тема исключений рассматривается только в этой главе, описание обработки исключений этого типа было отложено «на потом». Вот теперь настало время об этом поговорить.
Для начала необходимо отметить, что в этом разделе описывается поведение оператора new в соответствии со стандартом C++. Как было отмечено в главе 9, действия, выполняемые системой при неуспешном использовании оператора new, с момента изобретения языка C++ изменялись уже несколько раз. Сначала оператор new возвращал при неудаче значение null. Позже такое поведение было заменено генерированием исключения. Кроме того, несколько раз менялось имя этого исключения. Наконец, было решено, что оператор new будет генерировать исключения по умолчанию, но в качестве альтернативного варианта он может возвращать и нулевой указатель. Следовательно, оператор new в разное время был реализован различными способами. И хотя все современные компиляторы реализуют оператор new в соответствии со стандартом C++, компиляторы более «почтенного» возраста могут содержать отклонения от него. Если приведенные здесь примеры программ не работают с вашим компилятором, обратитесь к документации, прилагаемой к компилятору, и поинтересуйтесь, как именно он реализует
функционирование оператора new.
Согласно стандарту C++ при невозможности удовлетворить запрос на выделение памяти, требуемой оператором new, генерируется исключение типа bad_alloc. Если ваша программа не перехватит его, она будет досрочно завершена. Хотя такое поведение годится для коротких примеров программ, в реальных приложениях необходимо перехватывать это исключение и разумно обрабатывать его. Чтобы получить доступ к исключению типа bad_alloc, нужно включить в программу заголовок <new>.
Рассмотрим пример использования оператора new, заключенного в try/catch-блок для отслеживания неудачных результатов запроса на выделение памяти.
// Обработка исключений, генерируемых оператором new.
#include <iostream>
#include <new>
using namespace std;
int main()
{
int *p, i;
try {
p = new int[32]; // запрос на выделение памяти для 32элементного int-массива
}
catch (bad_alloc ха) {
cout << «Память не выделена.n»;
return 1;
}
for(i=0; i<32; i++) p[i] = i;
for(i=0; i<32; i++ ) cout << p[i] << » «;
delete [] p; // освобождение памяти
return 0;
}
При неудачном выполнении оператора new исключение в этой программе будет перехвачено catch-инструкцией. Этот же подход можно использовать для отслеживания любых ошибок, связанных с использованием оператора new: достаточно заключить каждую new-инструкцию в try-блок.
Альтернативная форма оператора new — nothrow
Стандарт C++ при неудачной попытке выделения памяти вместо генерирования исключения также позволяет оператору new возвращать значение null. Эта форма использования оператора new особенно полезна при компиляции старых программ с применением современного С++-компилятора. Это средство также очень полезно при замене вызовов функции malloc() оператором new. (Это обычная практика при переводе С- кода на язык C++.) Итак, этот формат оператора new выглядит следующим образом.
p_var = new(nothrow) тип;
Здесь элемент p_var— это указатель на переменную типа тип. Этот nothrow-формат оператора new работает подобно оригинальной версии оператора new, которая использовалась несколько лет назад. Поскольку оператор new (nothrow) возвращает при неудаче значение null, его можно «внедрить» в старый код программы, не прибегая к обработке исключений. Однако в новых программах на C++ все же лучше иметь дело с исключениями.
В следующем примере показано, как используется альтернативный вариант new (nothrow). Нетрудно догадаться, что перед вами вариация на тему предыдущей программы.
// Использование nothrow-версии оператора new.
#include <iostream>
#include <new>
using namespace std;
int main()
{
int *p, i;
p = new(nothrow) int[32]; // использование nothrow-версии
if(!p) {
cout << «Память не выделена.n»;
return 1;
}
for(i=0; i<32; i++) p[i] = i;
for(i=0; i<32; i++ ) cout << p[i] << » «;
delete [] p; // освобождение памяти
return 0;
}
Здесь при использовании nothrow-версии после каждого запроса на выделение памяти необходимо проверять значение указателя, возвращаемого оператором new.
Перегрузка операторов new и delete
Поскольку new и delete — операторы, их также можно перегружать. Несмотря на то что перегрузку операторов мы рассматривали в главе 13, тема перегрузки операторов new и delete была отложена до знакомства с темой исключений, поскольку правильно перегруженная версия оператора new (та, которая соответствует стандарту C++) должна в случае неудачи генерировать исключение типа bad_alloc. По ряду причин вам имеет смысл создать собственную версию оператора new. Например, создайте процедуры выделения памяти, которые, если область кучи окажется исчерпанной, автоматически начинают использовать дисковый файл в качестве виртуальной памяти. В любом случае реализация перегрузки этих операторов не сложнее перегрузки любых других.
Ниже приводится скелет функций, которые перегружают операторы new и delete.
// Выделение памяти для объекта.
void *operator new(size_t size)
{
/* В случае невозможности выделить память генерируется исключение типа bad_alloc. Конструктор вызывается автоматически. */
return pointer_to_memory;
}
// Удаление объекта.
void operator delete(void *p)
{
/* Освобождается память, адресуемая указателем р. Деструктор вызывается автоматически. */
}
Тип size_t специально определен, чтобы обеспечить хранение размера максимально возможной области памяти, которая может быть выделена для объекта. (Тип size_t, по сути,
—это целочисленный тип без знака.) Параметр size определяет количество байтов памяти, необходимых для хранения объекта, для которого выделяется память. Другими словами, это объем памяти, который должна выделить ваша версия оператора new. Перегруженная функция new должна возвращать указатель на выделяемую ею память или генерировать исключение типа bad_alloc в случае возникновении ошибки. Помимо этих ограничений, перегруженная функция new может выполнять любые нужные действия. При выделении памяти для объекта с помощью оператора new (его исходной версии или вашей собственной) автоматически вызывается конструктор объекта.
Функция delete получает указатель на область памяти, которую необходимо освободить. Затем она должна вернуть эту область памяти системе. При удалении объекта автоматически вызывается его деструктор.
Чтобы выделить память для массива объектов, а затем освободить ее, необходимо использовать следующие форматы операторов new и delete.
// Выделение памяти для массива объектов.
void *operator new[](size_t size)
{
/* В случае невозможности выделить память генерируется исключение типа bad_alloc. Каждый конструктор вызывается автоматически. */
return pointer_to_memory;
}
// Удаление массива объектов.
void operator delete[](void *p)
{
/* Освобождается память, адресуемая указателем р. При этом автоматически вызывается деструктор для каждого элемента массива. */
}
При выделении памяти для массива автоматически вызывается конструктор каждого объекта, а при освобождении массива автоматически вызывается деструктор каждого объекта. Это значит, что для выполнения этих действий не нужно явным образом программировать их.
Операторы new и delete, как правило, перегружаются относительно класса. Ради простоты в следующем примере используется не новая схема распределения памяти, а перегруженные функции new и delete, которые просто вызывают С-ориентированные функции выделения памяти malloc() и free(). (В своем собственном приложении вы вольны реализовать любой метод выделения памяти.)
Чтобы перегрузить операторы new и delete для конкретного класса, достаточно сделать эти перегруженные операторные функции членами этого класса. В следующем примере программы операторы new и delete перегружаются для класса three_d. Эта перегрузка позволяет выделить память для объектов и массивов объектов, а затем освободить ее.
// Демонстрация перегруженных операторов new и delete.
#include <iostream>
#include <new>
#include <cstdlib>
using namespace std;
class three_d {
int x, y, z; // 3-мерные координаты
public:
three_d() {
x = у = z = 0;
cout << «Создание объекта 0, 0, 0n»;
}
three_d(int i, int j, int k) {
x = i;
у = j;
z = k;
cout << «Создание объекта » << i << «, «;
cout << j << «, » << k;
cout << ‘n’;
}
~three_d() { cout << «Разрушение объектаn»; }
void *operator new(size_t size);
void *operator new[](size_t size);
void operator delete(void *p);
void operator delete[](void *p);
void show();
};
// Перегрузка оператора new для класса three_d.
void *three_d::operator new(size_t size)
{
void *p;
cout <<«Выделение памяти для объекта класса three_d.n»;
р = malloc(size);
// Генерирование исключения в случае неудачного выделения памяти.
if(!р) {
bad_alloc ba;
throw ba;
}
return р;
}
// Перегрузка оператора new для массива объектов типа three_d.
void *three_d::operator new[](size_t size)
{
void *p;
cout <<«Выделение памяти для массива three_d-oбъeктoв.»;
cout << «n»;
// Генерирование исключения при неудаче.
р = malloc(size);
if(!р) {
bad_alloc ba;
throw ba;
}
return p;
}
// Перегрузка оператора delete для класса three_d.
void three_d::operator delete(void *p)
{
cout << «Удаление объекта класса three_d.n»;
free(p);
}
// Перегрузка оператора delete для массива объектов типа three_d.
void three_d::operator delete[](void *p)
{
cout << «Удаление массива объектов типа three_d.n»;
free(р);
}
// Отображение координат X, Y, Z.
void three_d::show()
{
cout << x << «, «;
cout << у << «, «;
cout << z << «n»;
}
int main()
{
three_d *p1, *p2;
try {
p1 = new three_d[3]; // выделение памяти для массива
р2 = new three_d(5, 6, 7); // выделение памяти для объекта
}
catch (bad_alloc ba) {
cout << «Ошибка при выделении памяти.n»;
return 1;
}
p1[1].show();
p2->show();
delete [] p1; // удаление массива
delete р2; // удаление объекта
return 0;
}
При выполнении эта программа генерирует такие результаты.
Выделение памяти для массива three_d-oбъeктoв.
Создание объекта 0, 0, 0
Создание объекта 0, 0, 0
Создание объекта 0, 0, 0
Выделение памяти для объекта класса three_d.
Создание объекта 5, 6, 7
0, 0, 0
5, б, 7
Разрушение объекта
Разрушение объекта
Разрушение объекта
Удаление массива объектов типа three_d.
Разрушение объекта
Удаление объекта класса three_d.
Первые три сообщения Создание объекта 0, 0, 0 выданы конструктором класса three_d (который не имеет параметров) при выделении памяти для трехэлементного массива. Как упоминалось выше, при выделении памяти для массива автоматически вызывается конструктор каждого элемента. Сообщение Создание объекта 5, б, 7 выдано конструктором класса three_d (который принимает три аргумента) при выделении памяти для одного объекта. Первые три сообщения Разрушение объекта выданы деструктором в результате удаления трехэлементного массива, поскольку при этом автоматически вызывался деструктор каждого элемента массива. Последнее сообщение Разрушение объекта выдано при удалении одного объекта класса three_d. Важно понимать, что, если операторы new и delete перегружены для конкретного класса, то в результате их использования для данных других типов будут задействованы оригинальные версии операторов new и delete. Это
означает, что при добавлении в функцию main() следующей строки будет выполнена стандартная версия оператора new.
int *f = new int; // Используется стандартная версия оператора new.
И еще. Операторы new и delete можно перегружать глобально. Для этого достаточно объявить их операторные функции вне классов. В этом случае стандартные версии С++- операторов new и delete игнорируются вообще, и во всех запросах на выделение памяти используются их перегруженные версии. Безусловно, если вы при этом определите версию операторов new и delete для конкретного класса, то эти «классовые» версии будут применяться при выделении памяти (и ее освобождении) для объектов этого класса. Во всех же остальных случаях будут использоваться глобальные операторные функции.
Перегрузка nothrow-версии оператора new
Можно также создать перегруженные nothrow-версии операторов new и delete. Для этого используйте такие схемы.
// Перегрузка nothrow-версии оператора new.
void *operator new(size_t size, const nothrow_t &n)
{
// Выделение памяти.
if(success) return pointer_to_memory;
else return 0;
}
// Перегрузка nothrow-версии оператора new для массива.
void *operator new[](size_t size, const nothrow_t &n)
{
// Выделение памяти.
if(success) return pointer_to_memory;
else return 0;
}
// Перегрузка nothrow-версии оператора delete.
void operator delete(void *p, const nothrow_t &n)
{
// Освобождение памяти.
}
// Перегрузка nothrow-версии оператора delete для массива.
void operator delete[](void *p, const nothrow_t &n)
{
// Освобождение памяти.
}
Тип nothrow_t определяется в заголовке <new>. Параметр типа nothrow_t не используется. В качестве упражнения поэкспериментируйте с nothrow-версиями операторов new и delete самостоятельно.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Можно писать программы, которые обрабатывают выбранные исключения. Посмотрите на следующий пример, который запрашивает ввод у пользователя до тех пор, пока не будет введено правильное целое число, но позволяет пользователю прерывать программу, используя Ctrl-C или что-либо поддерживаемое операционной системой. Обратите внимание, что сгенерированное пользователем прерывание сигнализируется возбуждением исключения KeyboardInterrupt.
while True: try: x = int(input("Пожалуйста, введите целое число: ")) break except ValueError: print("Это не целое число. Попробуйте снова...")
Оператор try/except работает следующим образом:
- Сначала выполняется инструкция
try— код между ключевыми словамиtryиexcept. - Если исключение не возникает, инструкция
exceptпропускается и выполнение оператораtryзавершается. - Если во время выполнения кода в инструкции
tryвозникает исключение, остальная часть кода этого блока пропускается. Затем, если тип исключения соответствует исключению, записанному после ключевого словаexcept, блок кода этой инструкцииexceptвыполняется, а затем выполнение программы продолжается после всей конструкцииtry. - Если возникает исключение, которое не соответствует исключению, записанному в инструкции
except, оно передается внешним операторамtry. Если обработчик не найден, то это считается необработанным исключением, следовательно выполнение останавливается с сообщением об ошибке выполнения.
Оператор try может содержать несколько инструкций except, чтобы указать обработчики для различных исключений. В этом случае будет выполнен только один обработчик. Обработчики обрабатывают исключения, возникающие только в соответствующей конструкции try, а не в других обработчиках, например вложенных, того же оператора try. Инструкция except может иметь несколько исключений в виде кортежа, заключенного в скобки, например:
except (RuntimeError, TypeError, NameError): pass
Класс в инструкции except совместим с исключением, если это тот же самый класс или его базовый класс, но не наоборот. Инструкция except, перечисляющая производный класс, не совместима с базовым классом. Например, следующий код будет печатать B, C, D в таком порядке:
class B(Exception): pass class C(B): pass class D(C): pass for cls in [B, C, D]: try: raise cls() except D: print('D') except C: print('C') except B: print('B')
Обратите внимание, что если бы инструкции except были отменены (с первым исключением B), то вывелось бы B, B, B — срабатывает первое совпадающее предложение except.
Последняя инструкция except может опустить имя исключения. Используйте это с крайней осторожностью, таким образом можно легко замаскировать реальную ошибку программирования! Здесь можно использовать sys.exc_info() или модуль traceback для вывода сообщения об ошибке или ее сохранения для дельнейшего анализа, а затем повторно вызвать исключение при помощи оператора raise, что позволяет вызывающей стороне также обработать исключение:
import traceback try: f = open('myfile.txt') s = f.readline() i = int(s.strip()) except OSError as err: print("OS error: {0}".format(err)) except ValueError: print("Не удалось преобразовать данные в целое число.") except: print("Непредвиденная ошибка...") # сохраняем исключение для дальнейшего анализа. with open('trace.txt', 'a') as fp: traceback.print_exc(file=fp) # повторный вызов исключения, если это необходимо. raise
В примере выше, сведения об ошибке сохраняются в файл trace.txt с использованием встроенной функции open(). Лучшей практикой сохранения исключений для дальнейшего анализа в подобных ситуациях является применение модуля logging.
Конструкция try/except может содержать необязательную инструкцию else, которая при наличии должна следовать за всеми инструкциями except. Блок кода в инструкции else будет выполнен в том случае, если код в инструкции try не вызывает исключения. Например:
for arg in sys.argv[1:]: try: f = open(arg, 'r') except OSError: print('не удается открыть', arg) else: print(arg, 'имеет', len(f.readlines()), 'строк') f.close()
Использование инструкции else лучше, чем добавление дополнительного кода в инструкцию try, поскольку позволяет избежать случайного перехвата исключения, которое не было вызвано кодом, защищенным конструкцией try/except.
Когда возникает исключение, оно может иметь связанное значение, также известное как аргумент исключения. Наличие и тип аргумента зависят от типа исключения.
Инструкция except может указывать переменную после имени исключения. Переменная привязывается к экземпляру исключения с аргументами, хранящимися в экземпляре instance.args. Для удобства, экземпляр исключения определяет __str__(), так что аргументы могут быть напечатаны непосредственно без необходимости ссылаться instance.args. Кроме того, можно создать экземпляр исключения прежде, чем вызвать его и добавить любые атрибуты к нему по желанию.
try: raise Exception('spam', 'eggs') except Exception as inst: # экземпляр исключения print(type(inst)) # аргументы, хранящиеся внутри print(inst.args) # __str__ позволяет печатать args напрямую, но может # быть переопределен в подклассах исключений print(inst) # распаковка аргументов x, y = inst.args print('x =', x) print('y =', y) # <class 'Exception'> # ('spam', 'eggs') # ('spam', 'eggs') # x = spam # y = eggs
Если исключение имеет аргументы, они печатаются как последняя часть («деталь») сообщения для необработанных исключений.
Обработчики исключений обрабатывают не только исключения возникающие непосредственно в предложении try, но также если они возникают внутри функций, которые вызываются, даже косвенно, в коде оператора try. Например:
def this_fails(): x = 1/0 try: this_fails() except ZeroDivisionError as err: print('Handling run-time error:', err) #Handling run-time error: division by zero