229
229
14.06.2023 | Время чтения: 49 минут
![]()
Автор: Collaborator

Оглавление
- Новые функции Screaming Frog
- Как найти дублированный контент на сайте
- Как посмотреть процент совпадения контента
- Проверка орфографии и грамматики
- Улучшенные данные ссылок — положение ссылки, тип пути и цель
- Как посмотреть положение ссылки в Screaming Frog
- Проверки безопасности в Screaming Frog Spider: протоколы HTTP и HTTPS
- Как запустить полный парсинг сайта в Screaming Frog SEO
- Как провести сканирование всего сайта
- Как настроить Screaming Frog на проверку одной папки
- Как проверить субдомены и подкаталоги: настраиваем Screaming Frog под себя
- Как собрать все страницы на сайте
- Как получить список всех страниц в отдельном подкаталоге
- Как найти все субдомены на сайте с помощью Screaming Frog и проверить внешние ссылки
- Как сделать анализ интернет-магазина и других крупных сайтов при помощи Screaming Frog Spider
- Как проверить сайт, который хранится на старом сервере
- Как сделать анализ сайта, который требует cookie
- Может ли Screaming Frog проверить страницы, требующие аутентификации?
- Поиск внутренних и внешних ссылок в Screaming Frog
- Как получить информацию про все внутренние и внешние ссылки на сайте
- Как найти битые внутренние ссылки на страницу или на сайт
- Как использовать инструмент Screaming Frog SEO Spider для проверки исходящих ссылок
- Как найти ссылки с редиректом
- Использование SEO Spider при внутренней перелинковке
- Проверяем контент сайта с помощью Screaming Frog
- Как найти страницы с минимальным количество контента
- Как получить список ссылок на изображения на конкретной странице
- Проверка alt для изображений
- Как найти CSS файлы
- Как найти JavaScript файлы
- Как определить все jQuery плагины на сайте и на каких страницах они используются
- Как найти внутренние PDF файлы, на которые есть ссылка
- Как найти страницы с кнопкой «Поделиться» в соцсетях
- Как найти страницы, которые используют фреймы
- Как найти страницы со встроенным видео и аудио контентом
- Проверка мета-данных: как найти дубли title и descriptions
- Как найти страницы с длинными метаданными
- Как найти дубли title и descriptions
- Как найти дублированный контент на сайте?
- Как найти страницы с meta-директивами noindex, nofollow и др.
- Можно ли проверить файл robots.txt?
- Как найти или проверить микроразметку на сайте
- Создание и проверка Sitemap в Screaming Frog
- Как создать Sitemap XML
- Как создать Sitemap XML, загрузив URL
- Как проверить существующий Sitemap XML
- Другие технические проблемы, которые поможет решить Screaming Frog
- Почему конкретный раздел сайта не индексируется или не ранжируется
- Как проверить, был ли перенос сайта успешным
- Как найти страницы с низкой скоростью загрузки
- Как найти вредоносный софт или спам на сайте
- Проверка PPC и аналитика
- Как проверить список PPC URLов
- Очистка информации в Seo Frog Spider
- Как очистить мета данные для списка страниц
- Как очистить сайт от страниц, которые содержат определенную информацию
- Переименование URLов в настройках программы
- Как найти и заменить id сессий или другие параметры на проверенных страницах
- Как переименовать проверенные URLы
- Анализ ключевых слов конкурентов
- Как узнать самые важные страницы моих конкурентов
- Какие анкоры используют мои конкуренты во внутренних ссылках
- Как найти исходящие ссылки сайта и использовать для линкбилдинга
- Как получить список перспективных местоположений для ссылок
- Как найти битые ссылки для возможностей аутрича
- Как проверить обратные ссылки и посмотреть анкорный текст
- Как убедиться, что обратные ссылки были удалены
- Бонусный раунд
- Как редактировать мета-данные
- Как проанализировать сайт на JavaScript
Представляем перевод полного и обновленного гайда по использованию инструмента для SEO-аудита сайта Screaming frog SEO Spider. Ниже вы найдете полный список актуальных на 2021 год рекомендаций о том, как SEO и PPC-специалисты и digital-маркетологи могут использовать Screaming frog для оптимизации рабочего процесса.
Когда мы писали инструкцию, проанализировали, что чаще все пользователи ищут по данной программе:
- Как скачать Screaming Frog?
- Как пользоваться Screaming Frog SEO Spider?
- Как запустить полный парсинг сайта в Screaming Frog SEO?
- Как сделать технический аудит сайта при помощи Screaming Frog SEO?
- Как использовать инструмент Screaming Frog SEO Spider для проверки обратных ссылок?
На эти и многие другие вопросы дадим ответы в статье.
1 июля 2020 года Screaming Frog SEO Spider представил новую версию с кодовым названием «Карантин».
Чтобы найти дублрованный контент, нужно перейти во вкладку «Content», которая содержит фильтры для «Near Duplicates» и «Exact Duplicates».

Несмотря на отсутствие штрафов за дублирование контента, наличие похожих страниц может вызывать проблему неэффективности сканирования и индексации. Похожие страницы нужно свести к минимуму, поскольку высокое сходство — признак некачественных страниц.
Для «Near Duplicates» SEO Spider покажет вам наиболее близкий процент совпадения, а также неочевидные дубли для каждого URL. Фильтр «Exact Duplicates» использует ту же алгоритмическую проверку для идентификации идентичніх страниц, которые ранее назывались «Duplicate» во вкладке «URL».
В новой вкладке «Near Duplicates» используется алгоритм minhash, который позволяет вам настроить почти одинаковое пороговое значение, которое по умолчанию установлено на 90%. Это можно настроить через Config > Content > Duplicates.

Семантические элементы, такие как навигация и нижний колонтитул, автоматически исключаются из анализа содержимого, но вы можете детализировать его, исключив или включив элементы HTML, классы и идентификаторы. Это может помочь сосредоточить анализ на основной области контента, избегая известного шаблонного текста. Он также может быть использован для обеспечения более точного подсчета слов.

Рядом с дубликатами требуется заполнение анализа после сканирования, а более подробную информацию о дубликатах можно увидеть на новой нижней вкладке «Duplicate details». При этом отображаются все идентифицированные почти одинаковые URL-адреса и их совпадения.

Кликнув на «Near Duplicate address» во вкладке «Duplicate details», вы увидите неочевидный дублированный контент, обнаруженный среди страниц.

Близкий к дублирующемуся порог содержания и область контента, используемые в анализе, могут быть обновлены после сканирования.
Вкладка «Content» также включает в себя фильтр «Low Content Pages», который идентифицирует страницы, содержащие менее 200 слов, используя улучшенный подсчет. Это можно настроить в соответствии с вашими предпочтениями в Config > Spider > Preferences, поскольку не существует универсального критерия для минимального количества слов в SEO.
Как проверить орфографию и грамматику при помощи Screaming Frog? Новая вкладка «Content» содержит фильтры для «Spelling Errors» и «Grammar Errors» и отображает счетчики для каждой просканированной страницы.

Вы можете включить проверку орфографии и грамматики Config > Content > Spelling & Grammar.
Хотя это немного отличается от обычных SEO-ориентированных функций Screaming Frog, в основном роль разработчиков заключается в улучшении веб-сайтов для пользователей. Рекомендации Google по оценке качества поиска неоднократно описывают орфографические и грамматические ошибки как одну из характеристик некачественных страниц.

В правой части вкладки сведений также отображается визуальный текст со страницы и найденные ошибки.

На вкладке «Spelling & Grammar» на правой панели отображаются 100 обнаруженных уникальных ошибок и количество URL-адресов, на которые они влияют. Это может быть полезно для поиска ошибок в шаблонах, а также для построения вашего словаря или списка игнорируемых слов.

Новая функция проверки орфографии и грамматики Screaming Frog будет автоматически определять язык, используемый на странице через атрибут языка HTML, но также позволит вам вручную выбирать его при необходимости.

В настройках Screaming Frog SEO Spider можно обновить проверку орфографии и грамматики, чтобы отразить изменения в своем словаре, игнорировать список или правила грамматики без повторного сканирования URL-адресов.

Вы можете экспортировать все данные через меню Bulk Export > Content.

Теперь Screaming Frog SEO Spider записывает некоторые новые атрибуты для каждой ссылки.
Чтобы посмотреть положение каждой ссылки в сканировании, например, в навигации, в содержимом страницы, на боковой панели или в нижнем колонтитуле, посмотрите результаты сканирования. Классификация выполняется с использованием пути каждой ссылки (как XPath) и известных семантических подстрок, которые можно увидеть на вкладках «Inlinks» и «Outlinks».

Если ваш сайт использует семантические элементы HTML5 (или хорошо именованные несемантические элементы, такие как div id = «nav»), SEO Spider сможет автоматически определять различные части веб-страницы и ссылки внутри них.

Но не каждый веб-сайт построен таким образом, поэтому вы можете настроить классификацию позиций ссылок в Config > Custom > Link positions. Это позволяет вам использовать подстроку пути ссылки, чтобы классифицировать ее, как вы хотите.
Например, у нас есть ссылки мобильного меню за пределами элемента nav, которые определены как ссылки c контента. Это неверно, так как они являются дополнительной навигацией по мобильному телефону.

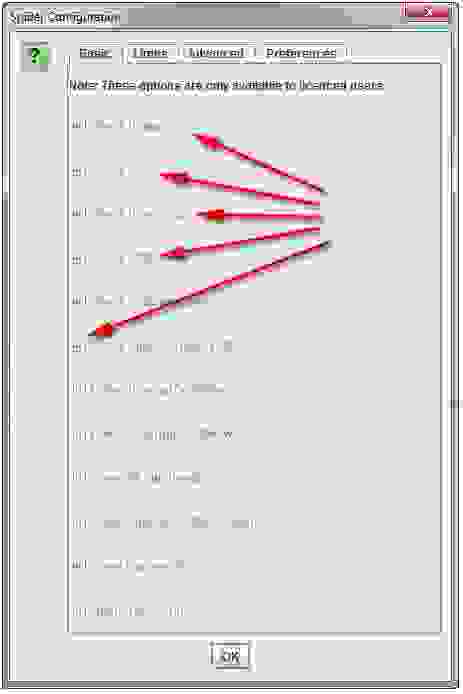
Имя класса «mobile-menu__dropdown» (которое находится в пути ссылки, как показано выше) можно использовать для определения правильной позиции ссылки с помощью функции «Links Positions». Ниже смотрите, как корректно настроить программу Screaming Frog Seo Spider.

Эти ссылки будут затем правильно отнесены к навигационным ссылкам.

Это может помочь определить входящие ссылки на страницу только из содержимого контента, например, игнорируя любые ссылки в основной навигации или нижний колонтитул для лучшего анализа внутренних ссылок.
Как узнать абсолютные и относительные ссылки
Screaming Frog позволяет узнать тип пути ссылки (абсолютный, относительный, протокольный или корневой). Его можно увидеть в ссылках, исходящих ссылках и во всех массовых экспортах.

Это может помочь идентифицировать ссылки, которые должны быть абсолютными, поскольку при некоторых обстоятельствах возникают проблемы с целостностью, безопасностью и производительностью. Вы можете отсортировать и выгрузить только абсолютные ссылки.
Целевой атрибут target ссылки
Кроме того, теперь вы можете посмотреть атрибут «target», чтобы обнаружить ссылки, которые используют «_blank» для открытия в новой вкладке.

Это полезно при анализе удобства использования, а также производительности и безопасности, что приводит нас к следующей функции.
Как поверить безопасность сайта или протоколы http, https? В настройках программы Screaming Frog Spider вкладка «Protocol» была переименована в «Security», и были введены более современные проверки и фильтры, связанные с безопасностью.
Несмотря на то, что SEO Spider уже смог идентифицировать HTTP-URL, смешанный контент и другие небезопасные элементы, отображение в фильтрах помогает легче их обнаружить.
Как найти смешанный контент с помощью Screaming Frog:

Вы можете быстро найти смешанный контент, проблемы с небезопасными формами, небезопасные ссылки на разные источники, относящиеся к протоколу ссылки на ресурсы, отсутствующие заголовки безопасности и многое другое.
Старый незащищенный отчет о содержимом также сохраняется, поскольку он проверяет все элементы (канонические, hreflang и т. д.) на наличие небезопасных элементов и полезен для миграций HTTPS.
Новые введенные проверки безопасности сосредоточены на наиболее распространенных проблемах, связанных с SEO, производительностью и безопасностью сети, но эта функциональность может быть расширена, чтобы охватить дополнительные проверки безопасности на основе отзывов пользователей.
Чтобы запустить полный парсинг сайта в Screaming Frog SEO, неплохо сперва оценить, какую информацию вы хотите получить, насколько большой сайт и какую часть сайта нужно проверить для полноты картины. В случае с большими сайтами лучше ограничить анализируемую зону до подсекции URLов, чтобы получить показательный образец данных. Это сохраняет размер файлов и экспортные данные более управляемыми. Дальше мы еще вернемся к этим деталям.
Для полного парсинга сайта со всеми поддоменами вам нужно будет немного поменять настройки перед началом. Это связано с тем, что по умолчанию Screaming Frog проверяет только поддомены, которые вы ввели. Другие дополнительные будут рассматриваться алгоритмом как внешние ссылки. Чтобы проверить дополнительные поддомены, вам нужно изменить настройки в меню Configuration. Выбрав Spider > Crawl all Subdomains, вы убедитесь, что алгоритм сканирует любые встречающиеся ссылки на поддомены вашего сайта.
Шаг 1 — настраиванием парсинг домена и поддоменов 
Шаг 2 — настраиваем проверку всего сайта
Если вы начали сканирование с конкретной вложенной папки и все еще хотите, чтобы Screaming Frog проверил весь сайт, отметьте «Crawl Outside of Start Folder».

Совет Pro — исключаем сканирование картинок, CSS и Javascript
Чтобы в Screaming Frog отключить сканирование изображений, CSS и Javascript файлов, снимите галочки с ненужных элементов. Это позволит сохранить время и место на диске (уменьшить размер сканируемых файлов).

Чтобы в настройках Screaming Frog Seo Spider ограничить проверку единственной папкой, просто введите URL и нажмите старт без изменения каких-либо настроек по умолчанию. Если вы перезаписали начальные настройки, сбросьте конфигурации по умолчанию в меню File > Configuration > Clear Default Configuration. Смотрите инструкцию ниже.

Если вы хотите начать проверку в конкретной папке, но продолжить в оставшемся поддомене, выберите «Crawl outside of start folder» в меню Configuration перед вводом начального URL. Этот скрин поможет разобраться в настройках.
Чтобы в Screaming Frog ограничить проверку конкретным рядом субдоменов или подкаталогов, вы можете использовать RegEx для установки этих правил в Include или Exclude настройках в меню Configuration.
Исключение
В этом примере мы просканировали каждую страницу на seerinteractive.com, исключая страницу «About» в каждом субдомене.
Шаг 1 — прописываем правила исключения
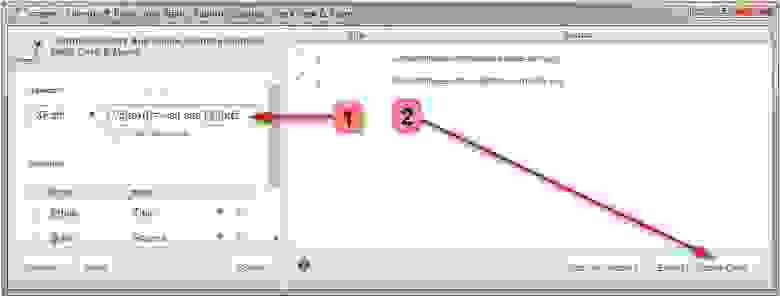
Откройте Configuration > Exclude; используйте шаблонное выражение для идентификации URLов или параметры, которые вы хотите исключить.

Шаг 2 — тестируем, как будет работать исключение
Протестируйте выражение, чтобы убедиться в наличии страниц, которые должны быть исключенными, перед началом проверки.

Включение
В примере ниже мы хотели сделать сканирование командной вложенной папки на seerinteractive.com. Используйте вкладку «Test» для проверки нескольких URLов, чтобы убедиться в корректной настройке RegEx для дополнительного правила.
Это отличный способ проверки крупных сайтов. К тому же, Screaming Frog рекомендовали этот метод, если вам нужно разделить и проверить большой домен.

По умолчанию Screaming Frog проверяет все изображения, JavaScript, CSS и flash файлы.
Чтобы в Screaming Frog собрать все страницы сайта (только HTML), уберите галочку с «Check Images», «Check CSS», «Check JavaScript» и «Check SWF» в меню Configuration.

Когда вы отключите вышеуказанные опции, Screaming Frog Seo Spider соберет все страницы на сайте с внутренними ссылками на них.
Как только проверка закончится, выберите вкладку «Internal» и отфильтруйте результаты по «HTML». Нажмите «Export» и у вас будет полный список страниц в формате CSV. Посмотрите инструкцию, как пользоваться данной фукцией.

Совет Pro — сохраняйте настройки Screaming Frog
Screaming Frog позволят сохранить настройки, которые вы ипользуете для каждой проверки:

В дополнении к сбросу «Check CSS», «Check CSS», «Check JavaScript» и «Check SWF» вы также захотите сбросить «Check links outside folder» в настройках. Если вы отключите эти настройки и выполните сканирование, то дополнительно получите список всех страниц в начальной папке.
Существует несколько способов найти все субдомены на сайте.
Способ 1 — используйте Screaming Frog для распознавания всех субдоменов на указанном сайте.
Перейдите в Configuration > Spider и убедитесь, что опция «Crawl all Subdomains» выбрана. Это поможет проверить любой связанный субдомен во время сканирования. Заметьте, что субдомены, на которые нет ссылок, не найдутся.

Способ 2 — используйте Google, чтобы найти все проиндексированные поддомены.
Используя расширение Scraper Chrome и продвинутых операторов поиска, можно найти все индексируемые субдомены для заданного домена.
Шаг 1 — использование операторов site и inurl
Начните с использования поискового оператора site: в Google чтобы ограничить результаты для конкретного домена. Затем используйте поисковый оператор -inurl, чтобы сузить результаты поиска, удалив основной домен. После этого вы начнете видеть список проиндексированных Google субдоменов, которые не содержат основного домена. 
Шаг 2 — используйте расширение Scraper
Используйте расширение Scraper для извлечения результатов в Google таблицу. Для этого кликните правой кнопкой по ссылке в SERP, выберите «Scrape similar» и экспортируйте в Google Doc.
Шаг 3 — уберите лишние данные
В Google Docs используйте следующую функцию для обрезки URL в субдомене:
=LEFT(A2,SEARCH(«/»,A2,9))
Этот гайд поможет убрать любые подкаталог, страницу или имя файла в конце сайта. Функция указывает таблице или Excel вернуть то, что стоит слева от косой черты. Начальный номер 9 существенный, поскольку мы просим начать поиск косой черты после 9 символа. Это учитывается для протокола https:// длинною в 8 символов.
Дедуплицируйте список и загрузите его в Screaming Frog в режиме списка.

Вы можете вставить список доменов вручную, использовать функцию или загрузить файл CSV.
 Способ 3 — найдите субдомены в Screaming Frog
Способ 3 — найдите субдомены в Screaming Frog
Введите корневой URL домена в инструментарий, который поможет найти сайты на том же IP адресе. В качестве альтернативы используйте специально предназначенные поисковые системы, например FindSubdomains. Создайте бесплатный аккаунт для входа и экспортируйте список субдоменов. Затем выгрузите список в Screaming Frog используя режим списка.
По завершению сканирования, вы сможете увидеть коды состояний, а также любые ссылки на домашние страницы субдоменов, тексты анкоров и дублированные title страниц и т. д.
Подходит ли Screaming Frog для парсинга крупных сайтов? Изначально Screaming Frog не был предназначен для проверки сотен и тысяч страниц, но благодаря некоторым апдейтам, мы приближаемся к этому.
Последняя версия Screaming Frog была обновлена, чтобы использовать хранилище базы данных для проверки. В версии 11.0 Screaming Frog позволил пользователям выбрать сохранение всех данных на диск в базе данных вместо того, чтобы хранить их в оперативной памяти. Это сделало возможным проверку крупных сайтов.
В версии 12.0 алгоритм автоматически сохранял результаты проверки в базу данных. Поэтому они остаются доступными через File > Crawls, на случай, если вы запаникуете и удивитесь, куда делась открытая команда.
Хотя сканирование базы данных помогает Screaming Frog лучше управлять большими проверками, это не единственный способ проверить большой сайт.
Что нужно для парсинга Screaming Frog Spider больших сайтов:
- Вы можете увеличить распределение памяти.
- Разбить проверку на подкаталоги или проверить только конкретные части сайта, используя настройки Include/Exclude.
- Вы можете не выбирать изображения, JavaScript, CSS и flash файлы. Отменив эти опции в настройках Screaming Frog Seo Spider, вы сохраните память для cканирования только HTML.
Совет Pro — приостанавливайте сканирование при необходимости
До недавних пор, Screaming Frog SEO Spider мог приостановить или уронить проверку крупного сайта. Сейчас, с хранением в базе данных по умолчанию вы можете восстановить проверку на том месте, где остановились. К тому же вы имеете доступ к очереди URLов на случай, если вы захотите исключить или добавить дополнительные параметры для проверки большого сайта.

В некоторых случаях старые сервера могут не обрабатывать определенное количество запросов по умолчанию в секунду. К слову, мы рекомендуем установить этот лимит, чтобы соблюдать этикет сервера. Лучше всего дать клиенту знать, когда вы планируете проверку сайта на случай защиты от неизвестных пользовательских агентов. В этом случае они могут внести ваш IP в белый список до того, как вы начнете сканировать сайт. В противной ситуации вы отправите слишком много запросов на сервер и случайно уроните сайт.
Для изменения скорости проверки, откройте Configuration > Speed и во всплывающем окне выберите максимальное количество потоков, которые должны выполняться одновременно. В этом меню вы также можете выбрать максимальное количество запросов URL в секунду. 
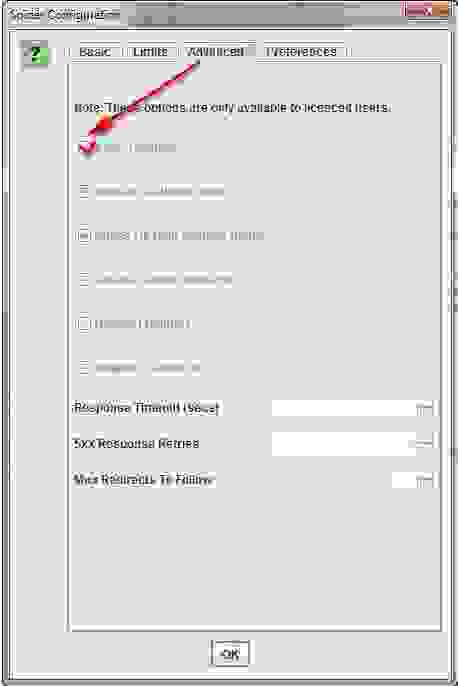
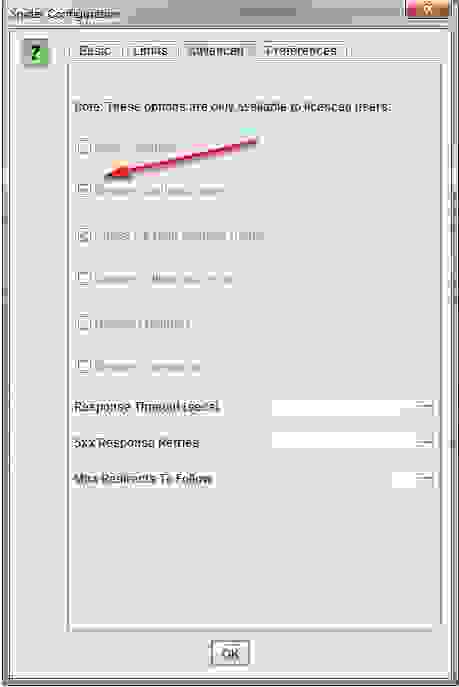
Совет Pro — увеличивайте Response Timeout в настройках
Если результат проверки выдаст много ошибок сервера, перейдите в Configuration > Spider > Advanced в настройках и увеличьте значение «Response Timeout» и «5xx Response Retries», чтобы получить лучшие результаты.

Screaming Frog Seo Spider позволяет сканировать сайты, которые требуют cookies. Хотя поисковые роботы не принимают cookies, если вы сканируете сайт и вам нужно разрешить их, просто перейдите в Configuration > Spider > Advanced и выберите «Allow Cookies».

Да, в настройках Screaming Frog можно управлять аутентификацией. Когда алгоритм Screaming Frog сталкивается с защищенной паролем страницей, появляется всплывающее окно, в котором вы можете ввести требуемые логин и пароль.
Аутентификация на основе форм — это мощная функция, которая может требовать JavaScript для эффективной работы.
Обратите внимание, что аутентификация на основе форм должна использоваться нечасто и только продвинутыми пользователями. Алгоритм запрограммирован так, что он нажимает на каждую ссылку на странице. Так что это потенциально может отразиться на ссылках, которые создают посты или даже удаляют данные.
Для управления аутентификацией, перейдите в Configuration > Authentication.
Чтобы выключить запросы аутентификации перейдите в Configuration > Authentication и снимите отметку с «Standards Based Authentication».

Если вам не нужна информация про JavaScript, CSS и flash файлы, отключите эти опции в меню настроек для экономии времени обработки и памяти.

Как только алгоритм закончит сканирование используйте Bulk Export меню «All links» для экспорта CSV. Вы узнаете про расположение всех ссылок вместе с соответствующими текстами анкоров, директивами и т.д.
Все ссылки могут представлять собой большой отчет. Помните об этом при экспорте. Для больших сайтов экспорт может занять время.
Для быстрого подсчета количества ссылок на каждой странице откройте вкладку «Internal» и выполните фильтрацию по «Outlinks». Все, что окажется больше 100, может потребовать пересмотра.

Screaming Frog Seo Spider позволяет найти битые страницы. Как только алгоритм закончит проверку, отфильтруйте результаты во вкладке «Internal» по «Status Code». Все 404, 301 и страницы с другим статусом будут показаны.
Кликнув по любому отдельному URL в результате проверки, вы увидите изменение информации внизу программного окна. Нажав на вкладку «In Links» внизу окна, вы найдете список страниц, которые привязаны к выбранным URL, вместе с анкорным текстом и директивами, использованными на этих ссылках. Вы можете использовать это свойство для мониторинга страниц, на которых нужно обновить внутренние ссылки.
Для экспорта полного списка страниц с битыми или редиректными ссылками, перейдите в Bulk Export > Response Codes и выберите «Redirection (3xx) In Links», «Client Error (4xx) In Links» или «Server Error (5xx) In Links». Таким образом вы получите экспортированные данные в файле CSV.
Для эскпорта полного списка битых страниц откройте меню Bulk Export. Прокрутите до кодов ответов и посмотрите на следующие отчеты:
- no response inlinks
- redirection (3xx) inlinks
- Redirection (JavaScript) inlinks
- redirection (meta refresh) inlinks
- client error (4xx) inlinks
- server error (5xx) inlinks

Screaming Frog Seo Spider находит все битые ссылки на сайте. Просмотр этих отчетов должен дать представление о том, какие внутренние ссылки нужно обновить. Это даст гарантию того, что они указывают на каноническую версию URL и распределены эффективно.
Screaming Frog SEO Spider поволяет найти внешние ссылки с проверяемого сайта.
Убедитесь, что опция «Check External Links» отмечена в Configuration > Spider.
После того как алгоритм закончил проверку, перейдите во вкладку «External» в верхнем окне. Затем отфильтруйте данные по «Status Code» и вы увидите URLы со всеми кодами, кроме 200. Кликнув по конкретному URL в результате поиска и затем на вкладку «In Links» внизу окна, вы найдете список страниц, которые указывают выбранный URL. Вы можете использовать эту особенность, чтобы выявить страницы, на которых нужно обновить исходящие ссылки.
Для экспорта полного списка исходящих ссылок, перейдите в Bulk Export > External Links.

Для полного списка всех локаций и анкорных текстов исходящих ссылок, Bulk Export > All Outlinks. Этот отчет также содержит исходящие ссылки на ваш субдомен. Если вы хотите исключить ваш домен, опирайтесь на вышеуказанный отчет «External Links».
После того, как алгоритм закончио проверку, выберите вкладку «Response Codes» в основном интерфейсе и отсортируйте по Status Code. Поскольку Screaming Frog использует регулярные выражения для поиска, подтвердите следующие критерии для фильтра: 301|302|307. Это должно представить вам довольно объемный список всех ссылок, которые вернулись с редиректом определенного типа.
Также это позволит вам узнать, был ли контент навсегда перемещен, найден или перенаправлен или временно перенаправлен согласно настройкам HSTS (вероятнее всего это вызвано 307 редиректом в Screaming Frog). Отсортируйте по «Status Code» и вы сможете разбить результаты по типу. Нажмите на вкладку «In Links» внизу окна, чтобы увидеть все страницы, на которых есть редиректные ссылки.
Если вы экспортируете прямо из этой вкладки, вы увидите только данные, показанные вверху окна (оригинальный URL, статус кода и куда направлен редирект).
Для экспортирования полного списка страниц с редиректными ссылками перейдите в Bulk Export > Response Codes и выберите «Redirection (3xx) In Links». Вы получите CSV файл, который содержит месторасположение всех редиректных ссылок. Для отображения только внутреннего редиректа, отфильтруйте колонку «Destination» в CSV, чтобы она включала в себя только ваш домен.
Совет Pro
Используйте VLOOKUP между двумя экспортированными файлами выше, чтобы соединить колонки Source и Destination с расположением финального URL.
Например: =VLOOKUP([@Destination],’response_codes_redirection_(3xx).csv’!$A$3:$F$50,6,
FALSE)(Где ’response_codes_redirection_(3xx).csv’ это файл CSV, который содержит редиректные ссылки, а 50 — это количество строк в этом файле)
Внутренняя перелинковка может принести хороший ROI (окупаемость инвестиций), особенно когда у вас есть стратегия распределения PageRank, ранжирование по ключевым словам и содержащие ключевые слова анкоры.
Screaming Frog позволяет посмотреть несодержательные страницы — страницы с минимальным количеством контента (или без него). Читайте инструкцию, как это сделать.
После того, как алгоритм закончит проверку, откройте вкладку «Internal», отсортируйте по HTML и прокрутите вправо до колонки «Word Count». Отсортируйте колонку «Word count» от наименьшего до наибольшего, чтобы найти страницы с маленьким количеством контента. Вы можете перетянуть колонку «Word Count» влево, чтобы лучше понимать, какие страницы соотносятся с определенным количеством. Нажмите «Export» во вкладке «Internal», если вам удобнее работать с данными в формате CSV.
Советы Pro для сайтов E-commerce
Вышеуказанный метод подсчета слов определяет количество реального текста на странице. Но нет способов конкретизировать — это название продукта или оптимизированный по ключевым словам текстовый блок. Если xPath запросы не ваша сильная сторона, то расширения xPath Helper или Xpather Chrome проделают солидную работу по определению xPath вместо вас.
Если вы уже проверили весь сайт или вложенную папку, просто выберите страницу вверху окна, перейдите во вкладку «Image Info» внизу, чтобы увидеть все найденные на странице изображения. Они будут перечислены в колонке «To».
Совет Pro
Кликните правой кнопкой по любой записи внизу окна, чтобы скопировать или открыть URL.
Как вариант, вы также можете увидеть изображения на странице, сканируя только этот URL. Убедитесь, что установлена глубина сканирования «1». Когда страница просканирована, нажмите на вкладку «Images». Там будут все найденные алгоритмом изображения.
Screaming Frog Seo Spider проверяет атрибуты для изображений: alt. Как проверить альты?
Посмотрите настройки и убедитесь, что «Check Images» отмечено в Configuration > Spider. После окончания проверки откройте вкладку «Images» и отсортируйте по «Missing Alt Text» или «Alt text Over 100 Characters». Вы можете найти страницы с изображениями, перейдя во вкладку «Image Info» внизу окна. Эти страницы будут перечислены в колонке «From».
Если вам удобнее работать с CSV, откройте Bulk Export > All Images или Bulk Export > Images > Images Missing Alt Text Inlinks для просмотра полного списка изображений. Там же вы увидите их расположение, связанный с ними текст alt или проблемы с ним.

В меню Configuration > Spider выберите «Crawl» и «Store» CSS перед проверкой. После завершения отсортируйте результаты по «CSS» во вкладке «Internal». 
В меню настроек выберите «Check JavaScript» перед проверкой. После завершения отсортируйте результаты по «JavaScript» во вкладке «Internal».

Проверьте настройки и убедитесь, что «Check JavaScript» выбрано в меню Configuration > Spider. После завершения проверки отсортируйте результаты во вкладке «Internal» по «JavaScript», а потом ищите «jquery». Таким образом вы получите список плагинов. При необходимости отсортируйте список по «Address» для облегчения просмотра. Затем посмотрите «InLinks» внизу окна или сделайте экспорт в CSV, чтобы найти страницы, где использованы файлы. Они будут отображаться в колонке «From».
Также через меню Bulk Export > All Links вы сможете экспортировать файл CSV и отфильтровать колонку «Destination» для показа URLов только с jQuery.
Совет Pro — как пользоваться Screaming Frog
Не все плагины jQuery вредят SEO. Если вы видите, что сайт использует jQuery, хорошо убедиться, что контент, который вы хотите индексировать, включен в источник страницы и обрабатывается во время загрузки страницы, а не после.
После завершения проверки отсортируйте результаты по «PDF» во вкладке «Internal».

Чтобы найти страницы, которые содержат кнопку «Поделиться», вам нужно настроить пользовательский фильтр перед запуском проверки. Для этого откройте Configuration > Custom. Оттуда введите любой фрагмент кода с источника страницы.  В примере выше мы хотели найти страницы, которые содержат кнопку «Like» в Facebook. Для этого мы создали фильтр для facebook.com/plugins/like.php
В примере выше мы хотели найти страницы, которые содержат кнопку «Like» в Facebook. Для этого мы создали фильтр для facebook.com/plugins/like.php
Чтобы найти страницы, использующие фреймы, установите пользовательский фильтр для iframe через Configuration > Custom перед началом проверки.
Чтобы найти страницы с видео или аудио, установите пользовательский фильтр для фрагмента встроенного кода с Youtube или другого медиа-проигрывателя, который используется на сайте.

Чтобы найти длинные title и description, после завершения проверки откройте вкладку «Page Titles» и отсортируйте по «Over 60 Characters», чтобы увидеть длинные title страниц. Вы можете сделать то же самое во вкладках «Meta Description» и «URL».

Чтобы найти дублрующиеся метаданные title и description, после завершения проверки откройте вкладку «Page Titles», затем отсортируйте по «Duplicate». Вы можете сделать то же самое во вкладках «Meta Description» «URL».

Чтобы найти дублированный контент на сайта (дублирующиеся URL), После завершения проверки откройте вкладку «URL» и отсортируйте по «Underscores», «Uppercase» или «Non ASCII Characters», чтобы увидеть URLы, которые могут быть переписаны под более стандартную структуру. Отсортируйте по «Duplicate» и вы увидите все страницы с несколькими версиями URL. Отсортируйте по «Parameters» и увидите «URL», которые содержат параметры.

Если вы откроете вкладку «Internal», отсортируете по «HTML» и прокрутите до колонки «Hash» вправо, вы увидите уникальную серию букв и цифр для каждой страницы. Если вы кликните «Export», то тогда вы сможете использовать условное форматирование в Excel, чтобы подсветить дублированные значения в этой колонке. Таким образом вы увидите одинаковые страницы.

С помощью Screaming Frog Seo Spider вы можете найти страницы, закрытые от индексации. После завершения проверки перейдите во вкладку «Directives». Чтобы увидеть тип, прокрутите вправо и посмотрите, какая колонка заполнена. Также вы можете воспользоваться фильтром, чтобы найти любой из следующих тэгов:
- index
- noindex
- follow
- nofollow
- noarchive
- nosnippet
- noodp
- noydir
- noimageindex
- notranslate
- unavailable_after
- refresh
Эту информацию можно посмотреть также в правом сайдбаре.

Screaming Frog по умолчанию соответствует файлу robots.txt. Как приоритет, он будет следовать указанию, сделанному специально для пользовательского агента Screaming Frog. Если таких указаний нет, алгоритм следует указаниям Googlebot. Если нет и таких, то алгоритм выполнит глобальные указания для всех пользовательских агентов. Алгоритм будет следовать одному набору указаний, так что если есть набор установленных только для Screaming Frog правил, он будет выполнять только их. Если вы хотите скрыть определенные части сайта от алгоритма, используйте обычный синтаксис robots.txt «Screaming Frog SEO Spider». Если вы хотите игнорировать robots.txt, просто выберите эту опцию в меню настроек: Configuration > robots.txt > Settings.

Чтобы через Screaming Frog найти страницы с разметкой или микроданными, используйте пользовательский фильтр. Перейдите в Configuration > Custom > Search и введите желаемый фрагмент. А вот краткая инструкция.
Чтобы найти страницы с разметкой, добавьте следующий фрагмент кода в пользовательский фильтр: itemtype=http://schema.org
Чтобы найти особый вид разметки, уточните детали. Например, использование пользовательского фильтра выдаст вам все страницы с разметкой для ratings.
Если говорить о Screaming Frog 11.0, SEO алгоритм также предоставляет возможность проверки, извлечения и структурированных данных прямо из результатов поиска. Проверяйте любые JSON-LD, Microdata или RDF структурированные данные в соответствии с рекомендациями Scema.org и спецификациями Google в реальном времени в процессе проверки. Для доступа к инструментам проверки структурированных данных выберите опцию Configuration > Spider > Advanced > Structured Data.
Теперь вы увидите вкладку Structured Data в главном интерфейсе. Она позволит вам переключаться между страницами со структурированными данными, в которых эти данные пропущены. Также они могут содержать ошибки валидации и предупреждения.
Также вы можете массово экспортировать проблемы со структурированными данными со Screaming Frog , посетив Reports > Structured Data > Validation Errors&Warnings.

Чтобы с помощью Screaming Frog Spider создать файл sitemap.xml, после завершения сканирования сайта, перейдите в Sitemaps > Sitemap XML.

Как пользоваться данной опцией?
После открытия настроек Sitemap XML, вы можете включить и исключить страницы по коду ответа, дате изменения, приоритету, частоте изменений и т. д. По умолчанию Screaming Frog включает 2xx URL, но перепроверять дважды — это хорошее правило.

В идеале карта сайта должна содержать страницы со статусом 200, каноническую версию каждого URL без каких-либо повторяющихся факторов. Нажмите OK, чтобы сохранить изменения. Sitemap XML будет загружена на ваше устройство и позволит вам редактировать соглашение о наименовании на ваше усмотрение.
Также вы можете создать Sitemap XML, загрузив URLы из существующего файла или вставив их в Screaming Frog вручную.
Измените режим со Spider на List в Mode и нажмите Upload, чтобы выбрать любой из вариантов.

Нажмите кнопку Start и Screaming Frog проверит загруженные URLы. Как только он это сделает, вы можете совершить вышеуказанные действия.
Вы можете загрузить существующий Sitemap XML для проверки ошибок или расхождений.
Откройте меню «Mode» в Screaming Frog и выберите «List». Затем, нажмите «Upload» вверху экрана и выберите Download Sitemap или Download Sitemap Index, введите URL карты сайта и начните проверку. По завершению, вы сможете найти редиректы, 404 ошибки, дублированные URL и т. д.

Проверка недостающих страниц в Sitemap XML
Вы можете настроить параметры проверки для исследования и сравнения URLов в карте сайта с URL из поиска.
Перейдите в Configuration > Spider в навигации и вам будут доступны несколько опций для Sitemap XML — Auto discover XML sitemaps через файл robots.txt или введите ссылку на Sitemap XML в окне.
Примечание: если ваш файл robots.txt не содержит правильных целевых ссылок на все Sitemaps XML, которые вы хотите просканировать, введите их вручную.

Как только вы обновили настройки проверки карты сайта, откройте «Crawl Analysis», а затем нажмите «Configure» и убедитесь, что кнопка Sitemap отмечена. Если вы сначала захотите сделать сканирование сайат полностью, тогда вернитесь в «Crawl Analysis» и нажмите Start.


По завершению Crawl Analysis, вы сможете увидеть все несоответствия. К примеру, ссылки, которые были выявлены при полном сканировании, но пропущенные в карте сайта.
Пытаетесь выяснить, почему некоторые страницы не индексируются? Сперва убедитесь, что они случайно не попали в robots.txt или не помечены, как noindex. Выше писали, какие отчеты Screaming Frog Seo Spider нужно смотреть.
Следом проверьте, что алгоритмы могут добраться до страниц, проверив внутренние ссылки. Страницы без внутренней перелинковки упоминаются, как Orphaned Pages (страницы-сироты). Чтобы выявить такие страницы, выполните следующие шаги:
- перейдите в Configuration > Spider. Внизу будут несколько опций для sitemap XML. Выполните автопроверку карты сайта через robots.txt или введите ссылку на sitemap XML вручную.
Обратите внимание, что если robots.txt не содержит правильных целевых ссылок на все sitemaps XML, которые вы хотите сканировать, вам нужно ввести их вручную;
- перейдите в Configuration > API Access > Google Analytics. Используя API вы можете получить и посмотреть данные аналитики для конкретного аккаунта. Чтобы найти страницы-сироты из органического поиска, убедитесь в сегментации по «Organic Traffic»;

- также вы можете перейти во вкладку General > Crawl New URLs Discovered in Google Analytics, если хотите, чтобы они были включены в полную проверку сайта. Если этот параметр не включен, вы сможете просматривать только новые URLы из Google Analytics в отчете страниц-сирот;
- перейдите в Configuration > API Access > Google Search Console. Используя API вы можете получить и посмотреть данные аналитики Google Search Console для конкретного аккаунта. Чтобы найти страницы-сироты, вы можете искать получающие клики и показы URLы, которые не были включены в проверку. Совет: также вы можете перейти в General > Crawl New URLs Discovered in Google Search Console, если хотите, чтобы они были включены в полную проверку сайта. Если этот параметр не включен, вы сможете просматривать только новые URLы из Google Search Console в отчете страниц-сирот;
- просканируйте сайт полностью. После завершения, перейдите в Crawl Analysis > Start и подождите его завершения;
- посмотрите сиротские URLы в каждой вкладке или сделайте массовый экспорт URLов, перейдя в Reports > Orphan Pages.



Если вы не имеет доступа в Google Analytics или Search Console, вы можете экспортировать список внутренних URLов как файл CSV, используя фильтр «HTML» во вкладке «Internal».
Откройте файл CSV и на второй странице вставьте список URLов, которыt не проиндексированы или не очень хорошо ранжируются. Используйте VLOOKUP, чтобы увидеть найденные в процессе сканирования URLы на второй странице.
Вы можете использовать Screaming Frog для проверки, были ли старые URLы перенаправлены с использованием режима «List» для проверки статусов кода. Если старые ссылки возвращают ошибку 404, тогда вы поймете, какие URLы должны быть перенаправлены.
Screaming Frog поможет найти страницы с низкой коростью загрузки. После завершения сканирования, откройте вкладку «Response Code» и отсортируйте колонку «Response Time» по убыванию. Таким образом вы можете выявить страницы, которые загружаются медленно.

Сначала вам нужно выявить следы вредоносного софта или спама. Дальше перейдите в Custom > Search в меню настроек и введите фрагмент, который вы ищете.

Вы можете ввести до 10 фрагментов за одно сканирование. Дальше нажмите ОК и продолжите сканирование сайта или списка страниц.
После завершения сканирования выберите вкладку «Custom» вверху окна, чтобы увидеть все страницы, которые содержат заданный фрагмент. Если вы ввели больше одного пользовательского фильтра, вы можете увидеть каждый, изменив его в результатах.
Сохраните список в формате .txt или .csv, затем измените настройки «Mode» на «List.
Выберите файл для загрузки и нажмите Start или вставьте список в Screaming Frog вручную. Посмотрите код статуса каждой страницы во вкладке «Internal».
Итак, у вас есть куча URLов, но вам нужно больше информации о них? Установите режим на «List», затем загрузите список URLов в формате .txt или .csv. После проверки вы можете увидеть статусы кодов, исходящие ссылки, количество слов и мета-данные для каждой страниц в вашем списке.
Перейдите в меню настроек, нажмите Custom > Search или Extraction и введите искомый фрагмент.

Вы можете ввести до 10 разных фрагментов за поиск. Нажмите OK и перейдите к сканированию сайта или списка страниц. В примере ниже мы хотели найти все страницы, которые содержат «Please Call» в разделе цен, так что мы нашли и скопировали код HTML с исходного текста страницы.

По завершению поиска выберите вкладку «Custom» вверху окна и посмотрите все страницы с необходимым фрагментом. Если вы ввели более одного пользовательского фильтра, вы можете посмотреть каждый из них, изменив фильтр результатов.
Совет Pro
Если вы извлекаете данные с сайта клиента, вы можете сэкономить время, попросив клиента выгрузить данные непосредственно с базы данных. Этот способ подходит для сайтов, к которым у вас нет прямого доступа.
Чтобы определить URLы с идентификаторами сеанса или другими параметрами, просто проведите сканирование вашего сайта с настройками по умолчанию. По завершению проверки перейдите во вкладку «URL» и отсортируйте по «Parameters», чтобы посмотреть все ссылки с параметрами.
Для удаления параметров с отображения в проверенных URLах, перейдите в Configuration > URL Rewriting. Затем во вкладке «Remove Parameters» нажмите «Add», чтобы добавить параметры, которые вы хотите удалить из URLов и нажмите OK. Перезапустите проверку с этими настройками для перезаписи.

Если после сканирования сайта Screaming Frog Seo Spider нужно переименовать урлы, для перезаписи любого проверенного URLа, перейдите в Configuration > URL Rewriting. Затем во вкладке «Regex Replace» нажмите «Add», чтобы добавить Reg Ex для того, что вы хотите заменить.

Как только вы добавили все желаемые правила, вы можете протестировать их во вкладке «Test». Для этого введите тестовый URL в «URL before rewriting». «URL after rewriting» будет обновлен автоматически согласно вашим правилам.

Если вы хотите задать правило, чтобы все URLы возвращались в нижнем регистре, установите «Lowercase discovered URLs» во вкладке «Options». Это удалит любое дублирование по заглавным URLам в проверке.

Не забудьте перезапустить проверку с этими настройками для перезаписи.
В общем, конкуренты будут стараться распространить популярность ссылок и привлечь трафик на наиболее ценные страницы, ссылаясь на них изнутри. Любые конкуренты с SEO мышлением вероятнее всего будут ссылаться на важные страницы с блога компании. Найдите ценные страницы ваших конкурентов, сделав сканирование их сайта. Затем отсортируйте колонку «Inlinks» во вкладке «Internal» по убыванию, чтобы увидеть страницы с наибольшим количеством внутренних ссылок.

Чтобы просмотреть страницы, ссылки на которые есть в блоге вашего конкурента, отмените выбор «Check links outside folder» в Configuration > Spider и просканируйте папку блога. Затем, во вкладке «External» отсортируйте результаты, используя поиск по URL основного домена. Прокрутите вправо и отсортируйте список в колонке «Inlinks», чтобы увидеть страницы, на которые ссылались чаще всего.

Совет Pro
Перетащите колонку влево или вправо, чтобы улучшить отображение данных.
Screaming Frog Seo Spider позволяет проанализировать анкоры на своей сайте или анкоры конкурентов.
Перейдите в Bulk Export > All Anchor Text, чтобы экспортировать CSV, который содержит все тексты анкоров на сайте, где они используются и на что ссылаются.

Если вы удалили или создали список URL-адресов, которые необходимо проверить, вы можете загрузить и отсканировать их в режиме «List», чтобы получить больше информации о страницах. По завершению сканирования проверьте коды состояния во вкладке «Response Codes» и просмотрите исходящие ссылки, их типы, тексты анкоров и директивы nofollow во вкладке «Outlinks» в нижнем окне. Это расскажет вам на какие сайты ссылаются эти страницы. Чтобы просмотреть вкладку «Outlinks», убедитесь, что в верхнем окне выбран интересующий вас URL.
Конечно с помощью пользовательского фильтра вы захотите проверить, ссылаются на вас эти страницы или нет.

Вы также можете экспортировать полный список исходящих ссылок, перейдя в меню Bulk export > All outlinks. Это не только предоставит вам ссылки на внешние сайты, но также покажет все внутренние ссылки на отдельных страницах вашего списка.

Итак, вы нашли сайт, с которого хотите получить ссылку? Используйте Screaming Frog, чтобы найти неработающие ссылки на нужной странице или на сайте в целом, затем обратитесь к владельцу сайта, предложив свой ресурс в качестве замены для неработающей ссылки, где это возможно. Ну или просто предложите неработающую ссылку в качестве жеста доброй воли 
Загрузите свой список обратных ссылок и запустите алгоритм в режиме Mode > List. Затем экспортируйте полный список исходящих ссылок, перейдя в Bulk Export > All Outlinks. Это предоставит вам URLы и анкорный/alt текст для всех ссылок на этих страницах. Затем вы можете использовать фильтр в колонке «Destination» в CSV, чтобы определить, ссылаются ли на ваш сайт и какой анкорный/alt текст включен.
Установите пользовательский фильтр, содержащий URL корневого домена, перейдя в Configuration > Custom > Search. Затем загрузите список обратных ссылок и запустите алгоритм в режиме Mode > List. После завершения сканирования, перейдите на вкладку «Custom», чтобы просмотреть все страницы, которые все еще ссылаются на вас.
Знаете ли вы, что при правом клике по любому URLу в верхнем окне результатов, вы можете выполнить любое из следующих действий?
- скопировать или открыть URL
- повторно сканировать или удалить URL
- экспортировать информацию об URL, во входящих и обратных ссылках или информации об изображениях для этой страницы
- проверить индексацию страницы в Google, Bing и Yahoo
- проверить обратные ссылки на страницу в Majestic, OSE, Ahrefs и Blekko
- посмотреть на кэшированную версию и дату кэша страницы
- посмотреть старые версии страницы
- проверить HTML-код страницы
- открыть файл robots.txt для домена, на котором находится страница
- найти другие домены на том же IP

Режим SERP позволяет вам просматривать фрагменты SERP на устройстве, чтобы визуализировать мета-данные в результатах поиска.
- Загрузите URL, titles и мета-описания в Screaming Frog, используя документ CSV или Excel.
Обратите внимание, что если вы уже провели сканирование своего сайта, вы можете экспортировать URLы, выбрав Reports > SERP Summary. Это легко отформатирует URLы и meta, которые вы хотите загрузить и отредактировать.
- Перейдите в Mode > SERP > Upload File.
- Отредактируйте мета-данные в Screaming Frog.
- Сделайте массовый экспорт мета-данных для отправки напрямую разработчикам.

Такие JavaScript фреймворки, как Angular, React и т.д. все чаще используются при создании сайтов. Google рекомендует использовать решение для рендеринга, поскольку Googlebot все еще пытается сканировать содержимое JavaScript. Если вы определили сайт с использованием JavaScript и хотите провести сканирование, следуйте инструкциям ниже:
- перейдите в Configuration > Spider > Rendering > JavaScript;
- измените настройки рендеринга в зависимости от того, что вы ищете. Вы можете настроить время ожидания, размер окна (мобильный, планшет, десктоп);
- нажмите ОК и начните сканирование.

В нижней части навигации щелкните вкладку «Rendered Page», чтобы увидеть, как страница отображается. Если она не отображается должным образом, проверьте наличие заблокированных ресурсов или увеличьте лимит времени ожидания в настройках конфигурации. Если ни один из вариантов не поможет решить это, возникнет более серьезная проблема.
Вы можете просмотреть и массово экспортировать любые заблокированные ресурсы, которые могут повлиять на сканирование и рендеринг вашего сайта, перейдя в Bulk Export > Response Codes.

Надеемся, этот гайд поможет вам разобраться в настройках Screaming Frog Seo Spider. В данной инструкции мы собрали основные возможност Screaming Frog: как сделать техический аудит, как найти дубли метаданных, как проверить исходящие ссылки, как проверить битые ссылки и редиректы, как с помощью Скриминг Фрога упросить линкбиндинг и другие нюансы работы с программой.
Оригинал статьи взят с сайта Collaborator

Основные настройки сканирования сайта
Для большинства специалистов общий аудит сайта – непростая задача, однако с таким инструментом, как Screaming Frog SEO Spider (СЕО Паук), она может стать значительно более простой для профессионалов и даже для новичков. Удобный интерфейс Screaming Frog позволяет работать легко и быстро: с его помощью можно проверить позиции сайта, просканировать все страницы, найти внутренние ссылки и проблемы с контентом. Однако многообразие вариантов конфигурации, сложность в настройке и функциональности может усложнить знакомство с программой.
Инструкция ниже призвана продемонстрировать способы использования Screaming Frog как для аудита сайтов, так и других задач необходимых для продвижения сайта.
Важно! Скачивать лучше последнюю версию программы, регулярно обновляя ее. Данный гайд рассчитан на версию 16.7. Если у вас более старая версия или, наоборот, новая, вы можете столкнуться с неточностями в описании или другим видом интерфейса программы.
Настройки парсера

Перечень базовых настроек перед стартом работ
Memory
Здесь указываем предел оперативной памяти для парсинга. Опираемся на параметры своего ПК: учтите, что при запуске краулера этот объем RAM будет полностью зарезервирован и доступен только ему. Слишком маленький объем буфера может привести к зависанию паука при сканировании очень больших сайтов.
Storage
В данном разделе указывается, куда будут сохраняться отчеты – в папку «Программы» либо по указанному пути (по умолчанию в /User).
Proxy
Указывается прокси, с помощью которых будет происходить парсинг (используется, если выбран чекбокс).
Embedded Browser
Если чекбокс активен, парсер использует встроенный в программу браузер (на базе Chromium) для сканирования.
Режимы сканирования — Mode
Выбираем режимы сканирования сайта.
*Кстати, вы можете в любой момент приостановить сканирование, сохранить проект и закрыть программу, а при следующем запуске продолжить с того же места.
Spider – классический парсинг сайта по внутренним ссылкам, домен вводится в адресную строку.
List – парсим только предварительно собранный список URL-адресов. Указать последние можно разными способами:
- From a File – выгружаем URL-адреса из файла.
- Paste – выгружаем URL-адреса из буфера обмена.
- Enter Manually – вводим вручную в соответствующее поле.
- Download Sitemap – выгружаем их из карты сайта.
SERP Mode – режим не для сканирования: в нем можно загружать метаданные сайта, редактировать и тестировать.
Скорость парсинга
Еще одна основная настройка SEO Frog. При запуске парсинга внизу указывается средняя скорость и текущая. Если сайт не выдерживает большой нагрузки, то лучше в настройках задать другое значение.
Необходимо зайти в Configuration ➜ Speed и выставить более щадящие параметры.
Можно уменьшить кол-во потоков, а также максимальное количество обрабатываемых адресов в секунду.

Автор: Collaborator
Оглавление
- Новые функции Screaming Frog
- Как найти дублированный контент на сайте
- Как посмотреть процент совпадения контента
- Проверка орфографии и грамматики
- Улучшенные данные ссылок — положение ссылки, тип пути и цель
- Как посмотреть положение ссылки в Screaming Frog
- Проверки безопасности в Screaming Frog Spider: протоколы HTTP и HTTPS
- Как запустить полный парсинг сайта в Screaming Frog SEO
- Как провести сканирование всего сайта
- Как настроить Screaming Frog на проверку одной папки
- Как проверить субдомены и подкаталоги: настраиваем Screaming Frog под себя
- Как собрать все страницы на сайте
- Как получить список всех страниц в отдельном подкаталоге
- Как найти все субдомены на сайте с помощью Screaming Frog и проверить внешние ссылки
- Как сделать анализ интернет-магазина и других крупных сайтов при помощи Screaming Frog Spider
- Как проверить сайт, который хранится на старом сервере
- Как сделать анализ сайта, который требует cookie
- Может ли Screaming Frog проверить страницы, требующие аутентификации?
- Поиск внутренних и внешних ссылок в Screaming Frog
- Как получить информацию про все внутренние и внешние ссылки на сайте
- Как найти битые внутренние ссылки на страницу или на сайт
- Как использовать инструмент Screaming Frog SEO Spider для проверки исходящих ссылок
- Как найти ссылки с редиректом
- Использование SEO Spider при внутренней перелинковке
- Проверяем контент сайта с помощью Screaming Frog
- Как найти страницы с минимальным количество контента
- Как получить список ссылок на изображения на конкретной странице
- Проверка alt для изображений
- Как найти CSS файлы
- Как найти JavaScript файлы
- Как определить все jQuery плагины на сайте и на каких страницах они используются
- Как найти внутренние PDF файлы, на которые есть ссылка
- Как найти страницы с кнопкой «Поделиться» в соцсетях
- Как найти страницы, которые используют фреймы
- Как найти страницы со встроенным видео и аудио контентом
- Проверка мета-данных: как найти дубли title и descriptions
- Как найти страницы с длинными метаданными
- Как найти дубли title и descriptions
- Как найти дублированный контент на сайте?
- Как найти страницы с meta-директивами noindex, nofollow и др.
- Можно ли проверить файл robots.txt?
- Как найти или проверить микроразметку на сайте
- Создание и проверка Sitemap в Screaming Frog
- Как создать Sitemap XML
- Как создать Sitemap XML, загрузив URL
- Как проверить существующий Sitemap XML
- Другие технические проблемы, которые поможет решить Screaming Frog
- Почему конкретный раздел сайта не индексируется или не ранжируется
- Как проверить, был ли перенос сайта успешным
- Как найти страницы с низкой скоростью загрузки
- Как найти вредоносный софт или спам на сайте
- Проверка PPC и аналитика
- Как проверить список PPC URLов
- Очистка информации в Seo Frog Spider
- Как очистить мета данные для списка страниц
- Как очистить сайт от страниц, которые содержат определенную информацию
- Переименование URLов в настройках программы
- Как найти и заменить id сессий или другие параметры на проверенных страницах
- Как переименовать проверенные URLы
- Анализ ключевых слов конкурентов
- Как узнать самые важные страницы моих конкурентов
- Какие анкоры используют мои конкуренты во внутренних ссылках
- Как найти исходящие ссылки сайта и использовать для линкбилдинга
- Как получить список перспективных местоположений для ссылок
- Как найти битые ссылки для возможностей аутрича
- Как проверить обратные ссылки и посмотреть анкорный текст
- Как убедиться, что обратные ссылки были удалены
- Бонусный раунд
- Как редактировать мета-данные
- Как проанализировать сайт на JavaScript
Представляем перевод полного и обновленного гайда по использованию инструмента для SEO-аудита сайта Screaming frog SEO Spider. Ниже вы найдете полный список актуальных на 2021 год рекомендаций о том, как SEO и PPC-специалисты и digital-маркетологи могут использовать Screaming frog для оптимизации рабочего процесса.
Когда мы писали инструкцию, проанализировали, что чаще все пользователи ищут по данной программе:
- Как скачать Screaming Frog?
- Как пользоваться Screaming Frog SEO Spider?
- Как запустить полный парсинг сайта в Screaming Frog SEO?
- Как сделать технический аудит сайта при помощи Screaming Frog SEO?
- Как использовать инструмент Screaming Frog SEO Spider для проверки обратных ссылок?
На эти и многие другие вопросы дадим ответы в статье.
1 июля 2020 года Screaming Frog SEO Spider представил новую версию с кодовым названием «Карантин».
Чтобы найти дублрованный контент, нужно перейти во вкладку «Content», которая содержит фильтры для «Near Duplicates» и «Exact Duplicates».
Несмотря на отсутствие штрафов за дублирование контента, наличие похожих страниц может вызывать проблему неэффективности сканирования и индексации. Похожие страницы нужно свести к минимуму, поскольку высокое сходство — признак некачественных страниц.
Для «Near Duplicates» SEO Spider покажет вам наиболее близкий процент совпадения, а также неочевидные дубли для каждого URL. Фильтр «Exact Duplicates» использует ту же алгоритмическую проверку для идентификации идентичніх страниц, которые ранее назывались «Duplicate» во вкладке «URL».
В новой вкладке «Near Duplicates» используется алгоритм minhash, который позволяет вам настроить почти одинаковое пороговое значение, которое по умолчанию установлено на 90%. Это можно настроить через Config > Content > Duplicates.
Семантические элементы, такие как навигация и нижний колонтитул, автоматически исключаются из анализа содержимого, но вы можете детализировать его, исключив или включив элементы HTML, классы и идентификаторы. Это может помочь сосредоточить анализ на основной области контента, избегая известного шаблонного текста. Он также может быть использован для обеспечения более точного подсчета слов.
Рядом с дубликатами требуется заполнение анализа после сканирования, а более подробную информацию о дубликатах можно увидеть на новой нижней вкладке «Duplicate details». При этом отображаются все идентифицированные почти одинаковые URL-адреса и их совпадения.
Кликнув на «Near Duplicate address» во вкладке «Duplicate details», вы увидите неочевидный дублированный контент, обнаруженный среди страниц.
Близкий к дублирующемуся порог содержания и область контента, используемые в анализе, могут быть обновлены после сканирования.
Вкладка «Content» также включает в себя фильтр «Low Content Pages», который идентифицирует страницы, содержащие менее 200 слов, используя улучшенный подсчет. Это можно настроить в соответствии с вашими предпочтениями в Config > Spider > Preferences, поскольку не существует универсального критерия для минимального количества слов в SEO.
Как проверить орфографию и грамматику при помощи Screaming Frog? Новая вкладка «Content» содержит фильтры для «Spelling Errors» и «Grammar Errors» и отображает счетчики для каждой просканированной страницы.
Вы можете включить проверку орфографии и грамматики Config > Content > Spelling & Grammar.
Хотя это немного отличается от обычных SEO-ориентированных функций Screaming Frog, в основном роль разработчиков заключается в улучшении веб-сайтов для пользователей. Рекомендации Google по оценке качества поиска неоднократно описывают орфографические и грамматические ошибки как одну из характеристик некачественных страниц.
В правой части вкладки сведений также отображается визуальный текст со страницы и найденные ошибки.
На вкладке «Spelling & Grammar» на правой панели отображаются 100 обнаруженных уникальных ошибок и количество URL-адресов, на которые они влияют. Это может быть полезно для поиска ошибок в шаблонах, а также для построения вашего словаря или списка игнорируемых слов.
Новая функция проверки орфографии и грамматики Screaming Frog будет автоматически определять язык, используемый на странице через атрибут языка HTML, но также позволит вам вручную выбирать его при необходимости.
В настройках Screaming Frog SEO Spider можно обновить проверку орфографии и грамматики, чтобы отразить изменения в своем словаре, игнорировать список или правила грамматики без повторного сканирования URL-адресов.
Вы можете экспортировать все данные через меню Bulk Export > Content.
Теперь Screaming Frog SEO Spider записывает некоторые новые атрибуты для каждой ссылки.
Чтобы посмотреть положение каждой ссылки в сканировании, например, в навигации, в содержимом страницы, на боковой панели или в нижнем колонтитуле, посмотрите результаты сканирования. Классификация выполняется с использованием пути каждой ссылки (как XPath) и известных семантических подстрок, которые можно увидеть на вкладках «Inlinks» и «Outlinks».
Если ваш сайт использует семантические элементы HTML5 (или хорошо именованные несемантические элементы, такие как div id = «nav»), SEO Spider сможет автоматически определять различные части веб-страницы и ссылки внутри них.
Но не каждый веб-сайт построен таким образом, поэтому вы можете настроить классификацию позиций ссылок в Config > Custom > Link positions. Это позволяет вам использовать подстроку пути ссылки, чтобы классифицировать ее, как вы хотите.
Например, у нас есть ссылки мобильного меню за пределами элемента nav, которые определены как ссылки c контента. Это неверно, так как они являются дополнительной навигацией по мобильному телефону.
Имя класса «mobile-menu__dropdown» (которое находится в пути ссылки, как показано выше) можно использовать для определения правильной позиции ссылки с помощью функции «Links Positions». Ниже смотрите, как корректно настроить программу Screaming Frog Seo Spider.
Эти ссылки будут затем правильно отнесены к навигационным ссылкам.
Это может помочь определить входящие ссылки на страницу только из содержимого контента, например, игнорируя любые ссылки в основной навигации или нижний колонтитул для лучшего анализа внутренних ссылок.
Как узнать абсолютные и относительные ссылки
Screaming Frog позволяет узнать тип пути ссылки (абсолютный, относительный, протокольный или корневой). Его можно увидеть в ссылках, исходящих ссылках и во всех массовых экспортах.
Это может помочь идентифицировать ссылки, которые должны быть абсолютными, поскольку при некоторых обстоятельствах возникают проблемы с целостностью, безопасностью и производительностью. Вы можете отсортировать и выгрузить только абсолютные ссылки.
Целевой атрибут target ссылки
Кроме того, теперь вы можете посмотреть атрибут «target», чтобы обнаружить ссылки, которые используют «_blank» для открытия в новой вкладке.
Это полезно при анализе удобства использования, а также производительности и безопасности, что приводит нас к следующей функции.
Как поверить безопасность сайта или протоколы http, https? В настройках программы Screaming Frog Spider вкладка «Protocol» была переименована в «Security», и были введены более современные проверки и фильтры, связанные с безопасностью.
Несмотря на то, что SEO Spider уже смог идентифицировать HTTP-URL, смешанный контент и другие небезопасные элементы, отображение в фильтрах помогает легче их обнаружить.
Как найти смешанный контент с помощью Screaming Frog:
Вы можете быстро найти смешанный контент, проблемы с небезопасными формами, небезопасные ссылки на разные источники, относящиеся к протоколу ссылки на ресурсы, отсутствующие заголовки безопасности и многое другое.
Старый незащищенный отчет о содержимом также сохраняется, поскольку он проверяет все элементы (канонические, hreflang и т. д.) на наличие небезопасных элементов и полезен для миграций HTTPS.
Новые введенные проверки безопасности сосредоточены на наиболее распространенных проблемах, связанных с SEO, производительностью и безопасностью сети, но эта функциональность может быть расширена, чтобы охватить дополнительные проверки безопасности на основе отзывов пользователей.
Чтобы запустить полный парсинг сайта в Screaming Frog SEO, неплохо сперва оценить, какую информацию вы хотите получить, насколько большой сайт и какую часть сайта нужно проверить для полноты картины. В случае с большими сайтами лучше ограничить анализируемую зону до подсекции URLов, чтобы получить показательный образец данных. Это сохраняет размер файлов и экспортные данные более управляемыми. Дальше мы еще вернемся к этим деталям.
Для полного парсинга сайта со всеми поддоменами вам нужно будет немного поменять настройки перед началом. Это связано с тем, что по умолчанию Screaming Frog проверяет только поддомены, которые вы ввели. Другие дополнительные будут рассматриваться алгоритмом как внешние ссылки. Чтобы проверить дополнительные поддомены, вам нужно изменить настройки в меню Configuration. Выбрав Spider > Crawl all Subdomains, вы убедитесь, что алгоритм сканирует любые встречающиеся ссылки на поддомены вашего сайта.
Шаг 1 — настраиванием парсинг домена и поддоменов
Шаг 2 — настраиваем проверку всего сайта
Если вы начали сканирование с конкретной вложенной папки и все еще хотите, чтобы Screaming Frog проверил весь сайт, отметьте «Crawl Outside of Start Folder».
Совет Pro — исключаем сканирование картинок, CSS и Javascript
Чтобы в Screaming Frog отключить сканирование изображений, CSS и Javascript файлов, снимите галочки с ненужных элементов. Это позволит сохранить время и место на диске (уменьшить размер сканируемых файлов).
Чтобы в настройках Screaming Frog Seo Spider ограничить проверку единственной папкой, просто введите URL и нажмите старт без изменения каких-либо настроек по умолчанию. Если вы перезаписали начальные настройки, сбросьте конфигурации по умолчанию в меню File > Configuration > Clear Default Configuration. Смотрите инструкцию ниже.
Если вы хотите начать проверку в конкретной папке, но продолжить в оставшемся поддомене, выберите «Crawl outside of start folder» в меню Configuration перед вводом начального URL. Этот скрин поможет разобраться в настройках.
Чтобы в Screaming Frog ограничить проверку конкретным рядом субдоменов или подкаталогов, вы можете использовать RegEx для установки этих правил в Include или Exclude настройках в меню Configuration.
Исключение
В этом примере мы просканировали каждую страницу на seerinteractive.com, исключая страницу «About» в каждом субдомене.
Шаг 1 — прописываем правила исключения
Откройте Configuration > Exclude; используйте шаблонное выражение для идентификации URLов или параметры, которые вы хотите исключить.
Шаг 2 — тестируем, как будет работать исключение
Протестируйте выражение, чтобы убедиться в наличии страниц, которые должны быть исключенными, перед началом проверки.
Включение
В примере ниже мы хотели сделать сканирование командной вложенной папки на seerinteractive.com. Используйте вкладку «Test» для проверки нескольких URLов, чтобы убедиться в корректной настройке RegEx для дополнительного правила.
Это отличный способ проверки крупных сайтов. К тому же, Screaming Frog рекомендовали этот метод, если вам нужно разделить и проверить большой домен.
По умолчанию Screaming Frog проверяет все изображения, JavaScript, CSS и flash файлы.
Чтобы в Screaming Frog собрать все страницы сайта (только HTML), уберите галочку с «Check Images», «Check CSS», «Check JavaScript» и «Check SWF» в меню Configuration.
Когда вы отключите вышеуказанные опции, Screaming Frog Seo Spider соберет все страницы на сайте с внутренними ссылками на них.
Как только проверка закончится, выберите вкладку «Internal» и отфильтруйте результаты по «HTML». Нажмите «Export» и у вас будет полный список страниц в формате CSV. Посмотрите инструкцию, как пользоваться данной фукцией.
Совет Pro — сохраняйте настройки Screaming Frog
Screaming Frog позволят сохранить настройки, которые вы ипользуете для каждой проверки:
В дополнении к сбросу «Check CSS», «Check CSS», «Check JavaScript» и «Check SWF» вы также захотите сбросить «Check links outside folder» в настройках. Если вы отключите эти настройки и выполните сканирование, то дополнительно получите список всех страниц в начальной папке.
Существует несколько способов найти все субдомены на сайте.
Способ 1 — используйте Screaming Frog для распознавания всех субдоменов на указанном сайте.
Перейдите в Configuration > Spider и убедитесь, что опция «Crawl all Subdomains» выбрана. Это поможет проверить любой связанный субдомен во время сканирования. Заметьте, что субдомены, на которые нет ссылок, не найдутся.
Способ 2 — используйте Google, чтобы найти все проиндексированные поддомены.
Используя расширение Scraper Chrome и продвинутых операторов поиска, можно найти все индексируемые субдомены для заданного домена.
Шаг 1 — использование операторов site и inurl
Начните с использования поискового оператора site: в Google чтобы ограничить результаты для конкретного домена. Затем используйте поисковый оператор -inurl, чтобы сузить результаты поиска, удалив основной домен. После этого вы начнете видеть список проиндексированных Google субдоменов, которые не содержат основного домена.
Шаг 2 — используйте расширение Scraper
Используйте расширение Scraper для извлечения результатов в Google таблицу. Для этого кликните правой кнопкой по ссылке в SERP, выберите «Scrape similar» и экспортируйте в Google Doc.
Шаг 3 — уберите лишние данные
В Google Docs используйте следующую функцию для обрезки URL в субдомене:
=LEFT(A2,SEARCH(«/»,A2,9))
Этот гайд поможет убрать любые подкаталог, страницу или имя файла в конце сайта. Функция указывает таблице или Excel вернуть то, что стоит слева от косой черты. Начальный номер 9 существенный, поскольку мы просим начать поиск косой черты после 9 символа. Это учитывается для протокола https:// длинною в 8 символов.
Дедуплицируйте список и загрузите его в Screaming Frog в режиме списка.
Вы можете вставить список доменов вручную, использовать функцию или загрузить файл CSV.
Способ 3 — найдите субдомены в Screaming Frog
Введите корневой URL домена в инструментарий, который поможет найти сайты на том же IP адресе. В качестве альтернативы используйте специально предназначенные поисковые системы, например FindSubdomains. Создайте бесплатный аккаунт для входа и экспортируйте список субдоменов. Затем выгрузите список в Screaming Frog используя режим списка.
По завершению сканирования, вы сможете увидеть коды состояний, а также любые ссылки на домашние страницы субдоменов, тексты анкоров и дублированные title страниц и т. д.
Подходит ли Screaming Frog для парсинга крупных сайтов? Изначально Screaming Frog не был предназначен для проверки сотен и тысяч страниц, но благодаря некоторым апдейтам, мы приближаемся к этому.
Последняя версия Screaming Frog была обновлена, чтобы использовать хранилище базы данных для проверки. В версии 11.0 Screaming Frog позволил пользователям выбрать сохранение всех данных на диск в базе данных вместо того, чтобы хранить их в оперативной памяти. Это сделало возможным проверку крупных сайтов.
В версии 12.0 алгоритм автоматически сохранял результаты проверки в базу данных. Поэтому они остаются доступными через File > Crawls, на случай, если вы запаникуете и удивитесь, куда делась открытая команда.
Хотя сканирование базы данных помогает Screaming Frog лучше управлять большими проверками, это не единственный способ проверить большой сайт.
Что нужно для парсинга Screaming Frog Spider больших сайтов:
- Вы можете увеличить распределение памяти.
- Разбить проверку на подкаталоги или проверить только конкретные части сайта, используя настройки Include/Exclude.
- Вы можете не выбирать изображения, JavaScript, CSS и flash файлы. Отменив эти опции в настройках Screaming Frog Seo Spider, вы сохраните память для cканирования только HTML.
Совет Pro — приостанавливайте сканирование при необходимости
До недавних пор, Screaming Frog SEO Spider мог приостановить или уронить проверку крупного сайта. Сейчас, с хранением в базе данных по умолчанию вы можете восстановить проверку на том месте, где остановились. К тому же вы имеете доступ к очереди URLов на случай, если вы захотите исключить или добавить дополнительные параметры для проверки большого сайта.
В некоторых случаях старые сервера могут не обрабатывать определенное количество запросов по умолчанию в секунду. К слову, мы рекомендуем установить этот лимит, чтобы соблюдать этикет сервера. Лучше всего дать клиенту знать, когда вы планируете проверку сайта на случай защиты от неизвестных пользовательских агентов. В этом случае они могут внести ваш IP в белый список до того, как вы начнете сканировать сайт. В противной ситуации вы отправите слишком много запросов на сервер и случайно уроните сайт.
Для изменения скорости проверки, откройте Configuration > Speed и во всплывающем окне выберите максимальное количество потоков, которые должны выполняться одновременно. В этом меню вы также можете выбрать максимальное количество запросов URL в секунду.
Совет Pro — увеличивайте Response Timeout в настройках
Если результат проверки выдаст много ошибок сервера, перейдите в Configuration > Spider > Advanced в настройках и увеличьте значение «Response Timeout» и «5xx Response Retries», чтобы получить лучшие результаты.
Screaming Frog Seo Spider позволяет сканировать сайты, которые требуют cookies. Хотя поисковые роботы не принимают cookies, если вы сканируете сайт и вам нужно разрешить их, просто перейдите в Configuration > Spider > Advanced и выберите «Allow Cookies».
Да, в настройках Screaming Frog можно управлять аутентификацией. Когда алгоритм Screaming Frog сталкивается с защищенной паролем страницей, появляется всплывающее окно, в котором вы можете ввести требуемые логин и пароль.
Аутентификация на основе форм — это мощная функция, которая может требовать JavaScript для эффективной работы.
Обратите внимание, что аутентификация на основе форм должна использоваться нечасто и только продвинутыми пользователями. Алгоритм запрограммирован так, что он нажимает на каждую ссылку на странице. Так что это потенциально может отразиться на ссылках, которые создают посты или даже удаляют данные.
Для управления аутентификацией, перейдите в Configuration > Authentication.
Чтобы выключить запросы аутентификации перейдите в Configuration > Authentication и снимите отметку с «Standards Based Authentication».
Если вам не нужна информация про JavaScript, CSS и flash файлы, отключите эти опции в меню настроек для экономии времени обработки и памяти.
Как только алгоритм закончит сканирование используйте Bulk Export меню «All links» для экспорта CSV. Вы узнаете про расположение всех ссылок вместе с соответствующими текстами анкоров, директивами и т.д.
Все ссылки могут представлять собой большой отчет. Помните об этом при экспорте. Для больших сайтов экспорт может занять время.
Для быстрого подсчета количества ссылок на каждой странице откройте вкладку «Internal» и выполните фильтрацию по «Outlinks». Все, что окажется больше 100, может потребовать пересмотра.
Screaming Frog Seo Spider позволяет найти битые страницы. Как только алгоритм закончит проверку, отфильтруйте результаты во вкладке «Internal» по «Status Code». Все 404, 301 и страницы с другим статусом будут показаны.
Кликнув по любому отдельному URL в результате проверки, вы увидите изменение информации внизу программного окна. Нажав на вкладку «In Links» внизу окна, вы найдете список страниц, которые привязаны к выбранным URL, вместе с анкорным текстом и директивами, использованными на этих ссылках. Вы можете использовать это свойство для мониторинга страниц, на которых нужно обновить внутренние ссылки.
Для экспорта полного списка страниц с битыми или редиректными ссылками, перейдите в Bulk Export > Response Codes и выберите «Redirection (3xx) In Links», «Client Error (4xx) In Links» или «Server Error (5xx) In Links». Таким образом вы получите экспортированные данные в файле CSV.
Для эскпорта полного списка битых страниц откройте меню Bulk Export. Прокрутите до кодов ответов и посмотрите на следующие отчеты:
- no response inlinks
- redirection (3xx) inlinks
- Redirection (JavaScript) inlinks
- redirection (meta refresh) inlinks
- client error (4xx) inlinks
- server error (5xx) inlinks
Screaming Frog Seo Spider находит все битые ссылки на сайте. Просмотр этих отчетов должен дать представление о том, какие внутренние ссылки нужно обновить. Это даст гарантию того, что они указывают на каноническую версию URL и распределены эффективно.
Screaming Frog SEO Spider поволяет найти внешние ссылки с проверяемого сайта.
Убедитесь, что опция «Check External Links» отмечена в Configuration > Spider.
После того как алгоритм закончил проверку, перейдите во вкладку «External» в верхнем окне. Затем отфильтруйте данные по «Status Code» и вы увидите URLы со всеми кодами, кроме 200. Кликнув по конкретному URL в результате поиска и затем на вкладку «In Links» внизу окна, вы найдете список страниц, которые указывают выбранный URL. Вы можете использовать эту особенность, чтобы выявить страницы, на которых нужно обновить исходящие ссылки.
Для экспорта полного списка исходящих ссылок, перейдите в Bulk Export > External Links.
Для полного списка всех локаций и анкорных текстов исходящих ссылок, Bulk Export > All Outlinks. Этот отчет также содержит исходящие ссылки на ваш субдомен. Если вы хотите исключить ваш домен, опирайтесь на вышеуказанный отчет «External Links».
После того, как алгоритм закончио проверку, выберите вкладку «Response Codes» в основном интерфейсе и отсортируйте по Status Code. Поскольку Screaming Frog использует регулярные выражения для поиска, подтвердите следующие критерии для фильтра: 301|302|307. Это должно представить вам довольно объемный список всех ссылок, которые вернулись с редиректом определенного типа.
Также это позволит вам узнать, был ли контент навсегда перемещен, найден или перенаправлен или временно перенаправлен согласно настройкам HSTS (вероятнее всего это вызвано 307 редиректом в Screaming Frog). Отсортируйте по «Status Code» и вы сможете разбить результаты по типу. Нажмите на вкладку «In Links» внизу окна, чтобы увидеть все страницы, на которых есть редиректные ссылки.
Если вы экспортируете прямо из этой вкладки, вы увидите только данные, показанные вверху окна (оригинальный URL, статус кода и куда направлен редирект).
Для экспортирования полного списка страниц с редиректными ссылками перейдите в Bulk Export > Response Codes и выберите «Redirection (3xx) In Links». Вы получите CSV файл, который содержит месторасположение всех редиректных ссылок. Для отображения только внутреннего редиректа, отфильтруйте колонку «Destination» в CSV, чтобы она включала в себя только ваш домен.
Совет Pro
Используйте VLOOKUP между двумя экспортированными файлами выше, чтобы соединить колонки Source и Destination с расположением финального URL.
Например: =VLOOKUP([@Destination],’response_codes_redirection_(3xx).csv’!$A$3:$F$50,6,
FALSE)(Где ’response_codes_redirection_(3xx).csv’ это файл CSV, который содержит редиректные ссылки, а 50 — это количество строк в этом файле)
Внутренняя перелинковка может принести хороший ROI (окупаемость инвестиций), особенно когда у вас есть стратегия распределения PageRank, ранжирование по ключевым словам и содержащие ключевые слова анкоры.
Screaming Frog позволяет посмотреть несодержательные страницы — страницы с минимальным количеством контента (или без него). Читайте инструкцию, как это сделать.
После того, как алгоритм закончит проверку, откройте вкладку «Internal», отсортируйте по HTML и прокрутите вправо до колонки «Word Count». Отсортируйте колонку «Word count» от наименьшего до наибольшего, чтобы найти страницы с маленьким количеством контента. Вы можете перетянуть колонку «Word Count» влево, чтобы лучше понимать, какие страницы соотносятся с определенным количеством. Нажмите «Export» во вкладке «Internal», если вам удобнее работать с данными в формате CSV.
Советы Pro для сайтов E-commerce
Вышеуказанный метод подсчета слов определяет количество реального текста на странице. Но нет способов конкретизировать — это название продукта или оптимизированный по ключевым словам текстовый блок. Если xPath запросы не ваша сильная сторона, то расширения xPath Helper или Xpather Chrome проделают солидную работу по определению xPath вместо вас.
Если вы уже проверили весь сайт или вложенную папку, просто выберите страницу вверху окна, перейдите во вкладку «Image Info» внизу, чтобы увидеть все найденные на странице изображения. Они будут перечислены в колонке «To».
Совет Pro
Кликните правой кнопкой по любой записи внизу окна, чтобы скопировать или открыть URL.
Как вариант, вы также можете увидеть изображения на странице, сканируя только этот URL. Убедитесь, что установлена глубина сканирования «1». Когда страница просканирована, нажмите на вкладку «Images». Там будут все найденные алгоритмом изображения.
Screaming Frog Seo Spider проверяет атрибуты для изображений: alt. Как проверить альты?
Посмотрите настройки и убедитесь, что «Check Images» отмечено в Configuration > Spider. После окончания проверки откройте вкладку «Images» и отсортируйте по «Missing Alt Text» или «Alt text Over 100 Characters». Вы можете найти страницы с изображениями, перейдя во вкладку «Image Info» внизу окна. Эти страницы будут перечислены в колонке «From».
Если вам удобнее работать с CSV, откройте Bulk Export > All Images или Bulk Export > Images > Images Missing Alt Text Inlinks для просмотра полного списка изображений. Там же вы увидите их расположение, связанный с ними текст alt или проблемы с ним.
В меню Configuration > Spider выберите «Crawl» и «Store» CSS перед проверкой. После завершения отсортируйте результаты по «CSS» во вкладке «Internal».
В меню настроек выберите «Check JavaScript» перед проверкой. После завершения отсортируйте результаты по «JavaScript» во вкладке «Internal».
Проверьте настройки и убедитесь, что «Check JavaScript» выбрано в меню Configuration > Spider. После завершения проверки отсортируйте результаты во вкладке «Internal» по «JavaScript», а потом ищите «jquery». Таким образом вы получите список плагинов. При необходимости отсортируйте список по «Address» для облегчения просмотра. Затем посмотрите «InLinks» внизу окна или сделайте экспорт в CSV, чтобы найти страницы, где использованы файлы. Они будут отображаться в колонке «From».
Также через меню Bulk Export > All Links вы сможете экспортировать файл CSV и отфильтровать колонку «Destination» для показа URLов только с jQuery.
Совет Pro — как пользоваться Screaming Frog
Не все плагины jQuery вредят SEO. Если вы видите, что сайт использует jQuery, хорошо убедиться, что контент, который вы хотите индексировать, включен в источник страницы и обрабатывается во время загрузки страницы, а не после.
После завершения проверки отсортируйте результаты по «PDF» во вкладке «Internal».
Чтобы найти страницы, которые содержат кнопку «Поделиться», вам нужно настроить пользовательский фильтр перед запуском проверки. Для этого откройте Configuration > Custom. Оттуда введите любой фрагмент кода с источника страницы. В примере выше мы хотели найти страницы, которые содержат кнопку «Like» в Facebook. Для этого мы создали фильтр для facebook.com/plugins/like.php
Чтобы найти страницы, использующие фреймы, установите пользовательский фильтр для iframe через Configuration > Custom перед началом проверки.
Чтобы найти страницы с видео или аудио, установите пользовательский фильтр для фрагмента встроенного кода с Youtube или другого медиа-проигрывателя, который используется на сайте.
Чтобы найти длинные title и description, после завершения проверки откройте вкладку «Page Titles» и отсортируйте по «Over 60 Characters», чтобы увидеть длинные title страниц. Вы можете сделать то же самое во вкладках «Meta Description» и «URL».
Чтобы найти дублрующиеся метаданные title и description, после завершения проверки откройте вкладку «Page Titles», затем отсортируйте по «Duplicate». Вы можете сделать то же самое во вкладках «Meta Description» «URL».
Чтобы найти дублированный контент на сайта (дублирующиеся URL), После завершения проверки откройте вкладку «URL» и отсортируйте по «Underscores», «Uppercase» или «Non ASCII Characters», чтобы увидеть URLы, которые могут быть переписаны под более стандартную структуру. Отсортируйте по «Duplicate» и вы увидите все страницы с несколькими версиями URL. Отсортируйте по «Parameters» и увидите «URL», которые содержат параметры.
Если вы откроете вкладку «Internal», отсортируете по «HTML» и прокрутите до колонки «Hash» вправо, вы увидите уникальную серию букв и цифр для каждой страницы. Если вы кликните «Export», то тогда вы сможете использовать условное форматирование в Excel, чтобы подсветить дублированные значения в этой колонке. Таким образом вы увидите одинаковые страницы.
С помощью Screaming Frog Seo Spider вы можете найти страницы, закрытые от индексации. После завершения проверки перейдите во вкладку «Directives». Чтобы увидеть тип, прокрутите вправо и посмотрите, какая колонка заполнена. Также вы можете воспользоваться фильтром, чтобы найти любой из следующих тэгов:
- index
- noindex
- follow
- nofollow
- noarchive
- nosnippet
- noodp
- noydir
- noimageindex
- notranslate
- unavailable_after
- refresh
Эту информацию можно посмотреть также в правом сайдбаре.
Screaming Frog по умолчанию соответствует файлу robots.txt. Как приоритет, он будет следовать указанию, сделанному специально для пользовательского агента Screaming Frog. Если таких указаний нет, алгоритм следует указаниям Googlebot. Если нет и таких, то алгоритм выполнит глобальные указания для всех пользовательских агентов. Алгоритм будет следовать одному набору указаний, так что если есть набор установленных только для Screaming Frog правил, он будет выполнять только их. Если вы хотите скрыть определенные части сайта от алгоритма, используйте обычный синтаксис robots.txt «Screaming Frog SEO Spider». Если вы хотите игнорировать robots.txt, просто выберите эту опцию в меню настроек: Configuration > robots.txt > Settings.
Чтобы через Screaming Frog найти страницы с разметкой или микроданными, используйте пользовательский фильтр. Перейдите в Configuration > Custom > Search и введите желаемый фрагмент. А вот краткая инструкция.
Чтобы найти страницы с разметкой, добавьте следующий фрагмент кода в пользовательский фильтр: itemtype=http://schema.org
Чтобы найти особый вид разметки, уточните детали. Например, использование пользовательского фильтра выдаст вам все страницы с разметкой для ratings.
Если говорить о Screaming Frog 11.0, SEO алгоритм также предоставляет возможность проверки, извлечения и структурированных данных прямо из результатов поиска. Проверяйте любые JSON-LD, Microdata или RDF структурированные данные в соответствии с рекомендациями Scema.org и спецификациями Google в реальном времени в процессе проверки. Для доступа к инструментам проверки структурированных данных выберите опцию Configuration > Spider > Advanced > Structured Data.
Теперь вы увидите вкладку Structured Data в главном интерфейсе. Она позволит вам переключаться между страницами со структурированными данными, в которых эти данные пропущены. Также они могут содержать ошибки валидации и предупреждения.
Также вы можете массово экспортировать проблемы со структурированными данными со Screaming Frog , посетив Reports > Structured Data > Validation Errors&Warnings.
Чтобы с помощью Screaming Frog Spider создать файл sitemap.xml, после завершения сканирования сайта, перейдите в Sitemaps > Sitemap XML.
Как пользоваться данной опцией?
После открытия настроек Sitemap XML, вы можете включить и исключить страницы по коду ответа, дате изменения, приоритету, частоте изменений и т. д. По умолчанию Screaming Frog включает 2xx URL, но перепроверять дважды — это хорошее правило.
В идеале карта сайта должна содержать страницы со статусом 200, каноническую версию каждого URL без каких-либо повторяющихся факторов. Нажмите OK, чтобы сохранить изменения. Sitemap XML будет загружена на ваше устройство и позволит вам редактировать соглашение о наименовании на ваше усмотрение.
Также вы можете создать Sitemap XML, загрузив URLы из существующего файла или вставив их в Screaming Frog вручную.
Измените режим со Spider на List в Mode и нажмите Upload, чтобы выбрать любой из вариантов.
Нажмите кнопку Start и Screaming Frog проверит загруженные URLы. Как только он это сделает, вы можете совершить вышеуказанные действия.
Вы можете загрузить существующий Sitemap XML для проверки ошибок или расхождений.
Откройте меню «Mode» в Screaming Frog и выберите «List». Затем, нажмите «Upload» вверху экрана и выберите Download Sitemap или Download Sitemap Index, введите URL карты сайта и начните проверку. По завершению, вы сможете найти редиректы, 404 ошибки, дублированные URL и т. д.
Проверка недостающих страниц в Sitemap XML
Вы можете настроить параметры проверки для исследования и сравнения URLов в карте сайта с URL из поиска.
Перейдите в Configuration > Spider в навигации и вам будут доступны несколько опций для Sitemap XML — Auto discover XML sitemaps через файл robots.txt или введите ссылку на Sitemap XML в окне.
Примечание: если ваш файл robots.txt не содержит правильных целевых ссылок на все Sitemaps XML, которые вы хотите просканировать, введите их вручную.
Как только вы обновили настройки проверки карты сайта, откройте «Crawl Analysis», а затем нажмите «Configure» и убедитесь, что кнопка Sitemap отмечена. Если вы сначала захотите сделать сканирование сайат полностью, тогда вернитесь в «Crawl Analysis» и нажмите Start.
По завершению Crawl Analysis, вы сможете увидеть все несоответствия. К примеру, ссылки, которые были выявлены при полном сканировании, но пропущенные в карте сайта.
Пытаетесь выяснить, почему некоторые страницы не индексируются? Сперва убедитесь, что они случайно не попали в robots.txt или не помечены, как noindex. Выше писали, какие отчеты Screaming Frog Seo Spider нужно смотреть.
Следом проверьте, что алгоритмы могут добраться до страниц, проверив внутренние ссылки. Страницы без внутренней перелинковки упоминаются, как Orphaned Pages (страницы-сироты). Чтобы выявить такие страницы, выполните следующие шаги:
- перейдите в Configuration > Spider. Внизу будут несколько опций для sitemap XML. Выполните автопроверку карты сайта через robots.txt или введите ссылку на sitemap XML вручную.
Обратите внимание, что если robots.txt не содержит правильных целевых ссылок на все sitemaps XML, которые вы хотите сканировать, вам нужно ввести их вручную;
- перейдите в Configuration > API Access > Google Analytics. Используя API вы можете получить и посмотреть данные аналитики для конкретного аккаунта. Чтобы найти страницы-сироты из органического поиска, убедитесь в сегментации по «Organic Traffic»;
- также вы можете перейти во вкладку General > Crawl New URLs Discovered in Google Analytics, если хотите, чтобы они были включены в полную проверку сайта. Если этот параметр не включен, вы сможете просматривать только новые URLы из Google Analytics в отчете страниц-сирот;
- перейдите в Configuration > API Access > Google Search Console. Используя API вы можете получить и посмотреть данные аналитики Google Search Console для конкретного аккаунта. Чтобы найти страницы-сироты, вы можете искать получающие клики и показы URLы, которые не были включены в проверку. Совет: также вы можете перейти в General > Crawl New URLs Discovered in Google Search Console, если хотите, чтобы они были включены в полную проверку сайта. Если этот параметр не включен, вы сможете просматривать только новые URLы из Google Search Console в отчете страниц-сирот;
- просканируйте сайт полностью. После завершения, перейдите в Crawl Analysis > Start и подождите его завершения;
- посмотрите сиротские URLы в каждой вкладке или сделайте массовый экспорт URLов, перейдя в Reports > Orphan Pages.
Если вы не имеет доступа в Google Analytics или Search Console, вы можете экспортировать список внутренних URLов как файл CSV, используя фильтр «HTML» во вкладке «Internal».
Откройте файл CSV и на второй странице вставьте список URLов, которыt не проиндексированы или не очень хорошо ранжируются. Используйте VLOOKUP, чтобы увидеть найденные в процессе сканирования URLы на второй странице.
Вы можете использовать Screaming Frog для проверки, были ли старые URLы перенаправлены с использованием режима «List» для проверки статусов кода. Если старые ссылки возвращают ошибку 404, тогда вы поймете, какие URLы должны быть перенаправлены.
Screaming Frog поможет найти страницы с низкой коростью загрузки. После завершения сканирования, откройте вкладку «Response Code» и отсортируйте колонку «Response Time» по убыванию. Таким образом вы можете выявить страницы, которые загружаются медленно.
Сначала вам нужно выявить следы вредоносного софта или спама. Дальше перейдите в Custom > Search в меню настроек и введите фрагмент, который вы ищете.
Вы можете ввести до 10 фрагментов за одно сканирование. Дальше нажмите ОК и продолжите сканирование сайта или списка страниц.
После завершения сканирования выберите вкладку «Custom» вверху окна, чтобы увидеть все страницы, которые содержат заданный фрагмент. Если вы ввели больше одного пользовательского фильтра, вы можете увидеть каждый, изменив его в результатах.
Сохраните список в формате .txt или .csv, затем измените настройки «Mode» на «List.
Выберите файл для загрузки и нажмите Start или вставьте список в Screaming Frog вручную. Посмотрите код статуса каждой страницы во вкладке «Internal».
Итак, у вас есть куча URLов, но вам нужно больше информации о них? Установите режим на «List», затем загрузите список URLов в формате .txt или .csv. После проверки вы можете увидеть статусы кодов, исходящие ссылки, количество слов и мета-данные для каждой страниц в вашем списке.
Перейдите в меню настроек, нажмите Custom > Search или Extraction и введите искомый фрагмент.
Вы можете ввести до 10 разных фрагментов за поиск. Нажмите OK и перейдите к сканированию сайта или списка страниц. В примере ниже мы хотели найти все страницы, которые содержат «Please Call» в разделе цен, так что мы нашли и скопировали код HTML с исходного текста страницы.
По завершению поиска выберите вкладку «Custom» вверху окна и посмотрите все страницы с необходимым фрагментом. Если вы ввели более одного пользовательского фильтра, вы можете посмотреть каждый из них, изменив фильтр результатов.
Совет Pro
Если вы извлекаете данные с сайта клиента, вы можете сэкономить время, попросив клиента выгрузить данные непосредственно с базы данных. Этот способ подходит для сайтов, к которым у вас нет прямого доступа.
Чтобы определить URLы с идентификаторами сеанса или другими параметрами, просто проведите сканирование вашего сайта с настройками по умолчанию. По завершению проверки перейдите во вкладку «URL» и отсортируйте по «Parameters», чтобы посмотреть все ссылки с параметрами.
Для удаления параметров с отображения в проверенных URLах, перейдите в Configuration > URL Rewriting. Затем во вкладке «Remove Parameters» нажмите «Add», чтобы добавить параметры, которые вы хотите удалить из URLов и нажмите OK. Перезапустите проверку с этими настройками для перезаписи.
Если после сканирования сайта Screaming Frog Seo Spider нужно переименовать урлы, для перезаписи любого проверенного URLа, перейдите в Configuration > URL Rewriting. Затем во вкладке «Regex Replace» нажмите «Add», чтобы добавить Reg Ex для того, что вы хотите заменить.
Как только вы добавили все желаемые правила, вы можете протестировать их во вкладке «Test». Для этого введите тестовый URL в «URL before rewriting». «URL after rewriting» будет обновлен автоматически согласно вашим правилам.
Если вы хотите задать правило, чтобы все URLы возвращались в нижнем регистре, установите «Lowercase discovered URLs» во вкладке «Options». Это удалит любое дублирование по заглавным URLам в проверке.
Не забудьте перезапустить проверку с этими настройками для перезаписи.
В общем, конкуренты будут стараться распространить популярность ссылок и привлечь трафик на наиболее ценные страницы, ссылаясь на них изнутри. Любые конкуренты с SEO мышлением вероятнее всего будут ссылаться на важные страницы с блога компании. Найдите ценные страницы ваших конкурентов, сделав сканирование их сайта. Затем отсортируйте колонку «Inlinks» во вкладке «Internal» по убыванию, чтобы увидеть страницы с наибольшим количеством внутренних ссылок.
Чтобы просмотреть страницы, ссылки на которые есть в блоге вашего конкурента, отмените выбор «Check links outside folder» в Configuration > Spider и просканируйте папку блога. Затем, во вкладке «External» отсортируйте результаты, используя поиск по URL основного домена. Прокрутите вправо и отсортируйте список в колонке «Inlinks», чтобы увидеть страницы, на которые ссылались чаще всего.
Совет Pro
Перетащите колонку влево или вправо, чтобы улучшить отображение данных.
Screaming Frog Seo Spider позволяет проанализировать анкоры на своей сайте или анкоры конкурентов.
Перейдите в Bulk Export > All Anchor Text, чтобы экспортировать CSV, который содержит все тексты анкоров на сайте, где они используются и на что ссылаются.
Если вы удалили или создали список URL-адресов, которые необходимо проверить, вы можете загрузить и отсканировать их в режиме «List», чтобы получить больше информации о страницах. По завершению сканирования проверьте коды состояния во вкладке «Response Codes» и просмотрите исходящие ссылки, их типы, тексты анкоров и директивы nofollow во вкладке «Outlinks» в нижнем окне. Это расскажет вам на какие сайты ссылаются эти страницы. Чтобы просмотреть вкладку «Outlinks», убедитесь, что в верхнем окне выбран интересующий вас URL.
Конечно с помощью пользовательского фильтра вы захотите проверить, ссылаются на вас эти страницы или нет.
Вы также можете экспортировать полный список исходящих ссылок, перейдя в меню Bulk export > All outlinks. Это не только предоставит вам ссылки на внешние сайты, но также покажет все внутренние ссылки на отдельных страницах вашего списка.
Итак, вы нашли сайт, с которого хотите получить ссылку? Используйте Screaming Frog, чтобы найти неработающие ссылки на нужной странице или на сайте в целом, затем обратитесь к владельцу сайта, предложив свой ресурс в качестве замены для неработающей ссылки, где это возможно. Ну или просто предложите неработающую ссылку в качестве жеста доброй воли
Загрузите свой список обратных ссылок и запустите алгоритм в режиме Mode > List. Затем экспортируйте полный список исходящих ссылок, перейдя в Bulk Export > All Outlinks. Это предоставит вам URLы и анкорный/alt текст для всех ссылок на этих страницах. Затем вы можете использовать фильтр в колонке «Destination» в CSV, чтобы определить, ссылаются ли на ваш сайт и какой анкорный/alt текст включен.
Установите пользовательский фильтр, содержащий URL корневого домена, перейдя в Configuration > Custom > Search. Затем загрузите список обратных ссылок и запустите алгоритм в режиме Mode > List. После завершения сканирования, перейдите на вкладку «Custom», чтобы просмотреть все страницы, которые все еще ссылаются на вас.
Знаете ли вы, что при правом клике по любому URLу в верхнем окне результатов, вы можете выполнить любое из следующих действий?
- скопировать или открыть URL
- повторно сканировать или удалить URL
- экспортировать информацию об URL, во входящих и обратных ссылках или информации об изображениях для этой страницы
- проверить индексацию страницы в Google, Bing и Yahoo
- проверить обратные ссылки на страницу в Majestic, OSE, Ahrefs и Blekko
- посмотреть на кэшированную версию и дату кэша страницы
- посмотреть старые версии страницы
- проверить HTML-код страницы
- открыть файл robots.txt для домена, на котором находится страница
- найти другие домены на том же IP
Режим SERP позволяет вам просматривать фрагменты SERP на устройстве, чтобы визуализировать мета-данные в результатах поиска.
- Загрузите URL, titles и мета-описания в Screaming Frog, используя документ CSV или Excel.
Обратите внимание, что если вы уже провели сканирование своего сайта, вы можете экспортировать URLы, выбрав Reports > SERP Summary. Это легко отформатирует URLы и meta, которые вы хотите загрузить и отредактировать.
- Перейдите в Mode > SERP > Upload File.
- Отредактируйте мета-данные в Screaming Frog.
- Сделайте массовый экспорт мета-данных для отправки напрямую разработчикам.
Такие JavaScript фреймворки, как Angular, React и т.д. все чаще используются при создании сайтов. Google рекомендует использовать решение для рендеринга, поскольку Googlebot все еще пытается сканировать содержимое JavaScript. Если вы определили сайт с использованием JavaScript и хотите провести сканирование, следуйте инструкциям ниже:
- перейдите в Configuration > Spider > Rendering > JavaScript;
- измените настройки рендеринга в зависимости от того, что вы ищете. Вы можете настроить время ожидания, размер окна (мобильный, планшет, десктоп);
- нажмите ОК и начните сканирование.
В нижней части навигации щелкните вкладку «Rendered Page», чтобы увидеть, как страница отображается. Если она не отображается должным образом, проверьте наличие заблокированных ресурсов или увеличьте лимит времени ожидания в настройках конфигурации. Если ни один из вариантов не поможет решить это, возникнет более серьезная проблема.
Вы можете просмотреть и массово экспортировать любые заблокированные ресурсы, которые могут повлиять на сканирование и рендеринг вашего сайта, перейдя в Bulk Export > Response Codes.
Надеемся, этот гайд поможет вам разобраться в настройках Screaming Frog Seo Spider. В данной инструкции мы собрали основные возможност Screaming Frog: как сделать техический аудит, как найти дубли метаданных, как проверить исходящие ссылки, как проверить битые ссылки и редиректы, как с помощью Скриминг Фрога упросить линкбиндинг и другие нюансы работы с программой.
Оригинал статьи взят с сайта Collaborator