На уроке будет рассмотрен оператор Delete SQL, служащий для удаления записей таблиц, а также оператор Update sql, предназначенный для обновления данных. Будут разобраны конкретные примеры запросов
Содержание:
- Запросы sql на удаление
- Оператор Update sql
Запросы sql на удаление
Оператор Delete («удалить» — пер. с английского) удаляет записи из таблицы БД.
Синтаксис:
DELETE FROM [WHERE ];
Пример: БД Институт. Запрос на удаление урока за определенную дату (за 02.10.2016)
✍ Решение:
Исходные данные:

DELETE FROM lessons WHERE lessons.date =’2016-10-02′
Delete from lessons where lessons.date =’2016-10-02′
Результат:

sql delete 1. БД Институт. Выполните запрос на удаление курса с названием «Математика» (таблица courses)
Важно: Если предложение WHERE в запросе отсутствует, то удаляются все строки из таблицы
Пример: БД Компьютерный магазин. Требуется удалить те компьютеры из таблицы product, для которых нет соответствующих строк в таблице pc.
✍ Решение:
DELETE FROM `product` WHERE `Тип`=»Компьютер» AND `Номер` NOT IN (SELECT `Номер` FROM pc)
DELETE FROM `product` WHERE `Тип`=»Компьютер» and `Номер` NOT IN (select `Номер` from pc)
Запрос предназначен для обновления (изменения) существующих данных. Update в переводе с английского языка — обновить.
Пример: БД Институт. Увеличить зарплату всех учителей в 2 раза, а премию — в 10 раз
✍ Решение:
UPDATE teachers SET zarplata = zarplata * 2, premia = premia * 10
UPDATE teachers SET zarplata = zarplata * 2, premia = premia * 10
Исходные данные:

Результат:

sql update 1. БД Институт. Увеличить в полтора раза зарплату у учителей, фамилия которых начинается на букву И.
sql update 2. БД Компьютерный магазин. Изменить значение поля Память у компьютеров, память которых менее 1024, установить его в 1024.
Важно: При отсутствии предложения WHERE будут обновлены все строки таблицы
Задание. БД «Компьютерные курсы». В таблице Список обновить поле Курс, изменив его на значение 4 для третьих курсов
Источник: https://labs-org.ru/sql-6/
Топ-65 вопросов по SQL с собеседований, к которым вы должны подготовиться в 2019 году. Часть I

Перевод статьи подготовлен для студентов курса «MS SQL Server разработчик»
Реляционные базы данных являются одними из наиболее часто используемых баз данных по сей день, и поэтому навыки работы с SQL для большинства должностей являются обязательными.
В этой статье с вопросами по SQL с собеседований я познакомлю вас с наиболее часто задаваемыми вопросами по SQL (Structured Query Language — язык структурированных запросов).
Эта статья является идеальным руководством для изучения всех концепций, связанных с SQL, Oracle, MS SQL Server и базой данных MySQL.
Наша статья с вопросами по SQL — универсальный ресурс, с помощью которого вы можете ускорить подготовку к собеседованию.
Она состоит из набора из 65 самых распространенных вопросов, которые интервьюер может задать во время собеседования.
Оно обычно начинается с базовых вопросов по SQL, а затем переходит к более сложным на основе обсуждения и ваших ответов. Эти вопросы по SQL с собеседований помогут вам извлечь максимальную выгоду на различных уровнях понимания. Давайте начнем!
Вопрос 1. В чем разница между операторами DELETE и TRUNCATE?
№ Вопрос 2. Из каких подмножеств состоит SQL?
- DDL (Data Definition Language, язык описания данных) — позволяет выполнять различные операции с базой данных, такие как CREATE (создание), ALTER (изменение) и DROP (удаление объектов).
- DML (Data Manipulation Language, язык управления данными) — позволяет получать доступ к данным и манипулировать ими, например, вставлять, обновлять, удалять и извлекать данные из базы данных.
- DCL (Data Control Language, язык контролирования данных) — позволяет контролировать доступ к базе данных. Пример — GRANT (предоставить права), REVOKE (отозвать права).
База данных — структурированная коллекция данных. Система управления базами данных (СУБД) — программное обеспечение, которое взаимодействует с пользователем, приложениями и самой базой данных для сбора и анализа данных.
СУБД позволяет пользователю взаимодействовать с базой данных. Данные, хранящиеся в базе данных, могут быть изменены, извлечены и удалены. Они могут быть любых типов, таких как строки, числа, изображения и т. д.
Существует два типа СУБД:
- Реляционная система управления базами данных: данные хранятся в отношениях (таблицах). Пример — MySQL.
- Нереляционная система управления базами данных: не существует понятия отношений, кортежей и атрибутов. Пример — Mongo.
Вопрос 4. Что подразумевается под таблицей и полем в SQL?
Таблица — организованный набор данных в виде строк и столбцов. Поле — это столбцы в таблице. Например: Таблица: Student_Information Поле: Stu_Id, Stu_Name, Stu_Marks
Вопрос 5. Что такое соединения в SQL?
Для соединения строк из двух или более таблиц на основе связанного между ними столбца используется оператор JOIN. Он используется для объединения двух таблиц или получения данных оттуда. В SQL есть 4 типа соединения, а именно:
- Inner Join (Внутреннее соединение)
- Right Join (Правое соединение)
- Left Join (Левое соединение)
- Full Join (Полное соединение)
Вопрос 6. В чем разница между типом данных CHAR и VARCHAR в SQL?
И Char, и Varchar служат символьными типами данных, но varchar используется для строк символов переменной длины, тогда как Char используется для строк фиксированной длины. Например, char(10) может хранить только 10 символов и не сможет хранить строку любой другой длины, тогда как varchar(10) может хранить строку любой длины до 10, т.е. например 6, 8 или 2.
Вопрос 7. Что такое первичный ключ (Primary key)?

- Первичный ключ — столбец или набор столбцов, которые однозначно идентифицируют каждую строку в таблице.
- Однозначно идентифицирует одну строку в таблице
- Нулевые (Null) значения не допускаются
_Пример: в таблице Student StuID является первичным ключом.
Вопрос 8. Что такое ограничения (Constraints)?
Ограничения (constraints) используются для указания ограничения на тип данных таблицы. Они могут быть указаны при создании или изменении таблицы. Пример ограничений:
- NOT NULL
- CHECK
- DEFAULT
- UNIQUE
- PRIMARY KEY
- FOREIGN KEY
Вопрос 9. В чем разница между SQL и MySQL?
SQL — стандартный язык структурированных запросов (Structured Query Language) на основе английского языка, тогда как MySQL — система управления базами данных. SQL — язык реляционной базы данных, который используется для доступа и управления данными, MySQL — реляционная СУБД (система управления базами данных), также как и SQL Server, Informix и т. д.
Вопрос 10. Что такое уникальный ключ (Unique key)?
- Однозначно идентифицирует одну строку в таблице.
- Допустимо множество уникальных ключей в одной таблице.
- Допустимы NULL-значения (прим. перевод.: зависит от СУБД, в SQL Server значение NULL может быть добавлено только один раз в поле с UNIQUE KEY).
Вопрос 11. Что такое внешний ключ (Foreign key)?
- Внешний ключ поддерживает ссылочную целостность, обеспечивая связь между данными в двух таблицах.
- Внешний ключ в дочерней таблице ссылается на первичный ключ в родительской таблице.
- Ограничение внешнего ключа предотвращает действия, которые разрушают связи между дочерней и родительской таблицами.
Вопрос 12. Что подразумевается под целостностью данных?
Целостность данных определяет точность, а также согласованность данных, хранящихся в базе данных. Она также определяет ограничения целостности для обеспечения соблюдения бизнес-правил для данных, когда они вводятся в приложение или базу данных.
Вопрос 13. В чем разница между кластеризованным и некластеризованным индексами в SQL?
- Различия между кластеризованным и некластеризованным индексами в SQL: Кластерный индекс используется для простого и быстрого извлечения данных из базы данных, тогда как чтение из некластеризованного индекса происходит относительно медленнее.
- Кластеризованный индекс изменяет способ хранения записей в базе данных — он сортирует строки по столбцу, который установлен как кластеризованный индекс, тогда как в некластеризованном индексе он не меняет способ хранения, но создает отдельный объект внутри таблицы, который указывает на исходные строки таблицы при поиске.
- Одна таблица может иметь только один кластеризованный индекс, тогда как некластеризованных у нее может быть много.
Вопрос 14. Напишите SQL-запрос для отображения текущей даты
В SQL есть встроенная функция GetDate (), которая помогает возвращать текущий timestamp/дату.
Вопрос 15. Перечислите типы соединений
Существуют различные типы соединений, которые используются для извлечения данных между таблицами. Принципиально они делятся на четыре типа, а именно:

Inner join (Внутреннее соединение): в MySQL является наиболее распространенным типом. Оно используется для возврата всех строк из нескольких таблиц, для которых выполняется условие соединения.
Left Join (Левое соединение): в MySQL используется для возврата всех строк из левой (первой) таблицы и только совпадающих строк из правой (второй) таблицы, для которых выполняется условие соединения.
Right Join (Правое соединение): в MySQL используется для возврата всех строк из правой (второй) таблицы и только совпадающих строк из левой (первой) таблицы, для которых выполняется условие соединения.
Full Join (Полное соединение): возвращает все записи, для которых есть совпадение в любой из таблиц. Следовательно, он возвращает все строки из левой таблицы и все строки из правой таблицы.
Вопрос 16. Что вы подразумеваете под денормализацией?
Денормализация — техника, которая используется для преобразования из высших к низшим нормальным формам. Она помогает разработчикам баз данных повысить производительность всей инфраструктуры, поскольку вносит избыточность в таблицу. Она добавляет избыточные данные в таблицу, учитывая частые запросы к базе данных, которые объединяют данные из разных таблиц в одну таблицу.
Вопрос 17. Что такое сущности и отношения?
Сущности: человек, место или объект в реальном мире, данные о которых могут храниться в базе данных. В таблицах хранятся данные, которые представляют один тип сущности. Например — база данных банка имеет таблицу клиентов для хранения информации о клиентах. Таблица клиентов хранит эту информацию в виде набора атрибутов (столбцы в таблице) для каждого клиента.
Отношения: отношения или связи между сущностями, которые имеют какое-то отношение друг к другу. Например — имя клиента связано с номером учетной записи клиента и контактной информацией, которая может быть в той же таблице. Также могут быть отношения между отдельными таблицами (например, клиент к счетам).
Вопрос 18. Что такое индекс?
Индексы относятся к методу настройки производительности, позволяющему быстрее извлекать записи из таблицы. Индекс создает отдельную структуру для индексируемого поля и, следовательно, позволяет быстрее получать данные.
Вопрос 19. Опишите различные типы индексов
Есть три типа индексов, а именно:
- Уникальный индекс (Unique Index): этот индекс не позволяет полю иметь повторяющиеся значения, если столбец индексируется уникально. Если первичный ключ определен, уникальный индекс может быть применен автоматически.
- Кластеризованный индекс (Clustered Index): этот индекс меняет физический порядок таблицы и выполняет поиск на основе значений ключа. Каждая таблица может иметь только один кластеризованный индекс.
- Некластеризованный индекс (Non-Clustered Index): не изменяет физический порядок таблицы и поддерживает логический порядок данных. Каждая таблица может иметь много некластеризованных индексов.
Вопрос 20. Что такое нормализация и каковы ее преимущества?
Нормализация — процесс организации данных, цель которого избежать дублирования и избыточности. Некоторые из преимуществ:
- Лучшая организация базы данных
- Больше таблиц с небольшими строками
- Эффективный доступ к данным
- Большая гибкость для запросов
- Быстрый поиск информации
- Проще реализовать безопасность данных
- Позволяет легко модифицировать
- Сокращение избыточных и дублирующихся данных
- Более компактная база данных
- Обеспечивает согласованность данных после внесения изменений
Вопрос 21. В чем разница между командами DROP и TRUNCATE?
Команда DROP удаляет саму таблицу, и нельзя сделать Rollback команды, тогда как команда TRUNCATE удаляет все строки из таблицы (прим. перевод.: в SQL Server Rollback нормально отработает и откатит DROP).
Вопрос 22. Объясните различные типы нормализации
Существует много последовательных уровней нормализации. Это так называемые нормальные формы. Каждая последующая нормальная форма включает предыдущую. Первых трех нормальных форм обычно достаточно.
- Первая нормальная форма (1NF) — нет повторяющихся групп в строках
- Вторая нормальная форма (2NF) — каждое неключевое (поддерживающее) значение столбца зависит от всего первичного ключа
- Третья нормальная форма (3NF) — каждое неключевое значение зависит только от первичного ключа и не имеет зависимости от другого неключевого значения столбца
Вопрос 23. Что такое свойство ACID в базе данных?
ACID означает атомарность (Atomicity), согласованность (Consistency), изолированность (Isolation), долговечность (Durability). Он используется для обеспечения надежной обработки транзакций данных в системе базы данных.
Атомарность. Гарантирует, что транзакция будет полностью выполнена или потерпит неудачу, где транзакция представляет одну логическую операцию данных. Это означает, что при сбое одной части любой транзакции происходит сбой всей транзакции и состояние базы данных остается неизменным.
Согласованность. Гарантирует, что данные должны соответствовать всем правилам валидации. Проще говоря, вы можете сказать, что ваша транзакция никогда не оставит вашу базу данных в недопустимом состоянии.
Изолированность. Основной целью изолированности является контроль механизма параллельного изменения данных.
Долговечность. Долговечность подразумевает, что если транзакция была подтверждена (COMMIT), произошедшие в рамках транзакции изменения сохранятся независимо от того, что может встать у них на пути (например, потеря питания, сбой или ошибки любого рода).
Вопрос 24. Что вы подразумеваете под «триггером» в SQL?
Триггер в SQL — особый тип хранимых процедур, которые предназначены для автоматического выполнения в момент или после изменения данных. Это позволяет вам выполнить пакет кода, когда вставка, обновление или любой другой запрос выполняется к определенной таблице.
Вопрос 25. Какие операторы доступны в SQL?
В SQL доступно три типа оператора, а именно:
- Арифметические Операторы
- Логические Операторы
- Операторы сравнения
Вопрос 26. Совпадают ли значения NULL со значениями нуля или пробела?
Значение NULL вовсе не равно нулю или пробелу. Значение NULL представляет значение, которое недоступно, неизвестно, присвоено или неприменимо, тогда как ноль — это число, а пробел — символ.
Вопрос 27. В чем разница между перекрестным (cross join) и естественным (natural join) соединением?
Перекрестное соединение создает перекрестное или декартово произведение двух таблиц, тогда как естественное соединение основано на всех столбцах, имеющих одинаковое имя и типы данных в обеих таблицах.
Вопрос 28. Что такое подзапрос в SQL?
Подзапрос — это запрос внутри другого запроса, в котором определен запрос для извлечения данных или информации из базы данных.
В подзапросе внешний запрос называется основным запросом, тогда как внутренний запрос называется подзапросом. Подзапросы всегда выполняются первыми, а результат подзапроса передается в основной запрос.
Он может быть вложен в SELECT, UPDATE или любой другой запрос. Подзапрос также может использовать любые операторы сравнения, такие как >, < или =.
Вопрос 29. Какие бывают типы подзапросов?
Существует два типа подзапросов, а именно: коррелированные и некоррелированные.
- Коррелированный подзапрос: это запрос, который выбирает данные из таблицы со ссылкой на внешний запрос. Он не считается независимым запросом, поскольку ссылается на другую таблицу или столбец в таблице.
- Некоррелированный подзапрос: этот запрос является независимым запросом, в котором выходные данные подзапроса подставляются в основной запрос.
Вопрос 30. Перечислите способы получить количество записей в таблице?
Для подсчета количества записей в таблице вы можете использовать следующие команды: SELECT * FROM table1 SELECT COUNT(*) FROM table1 SELECT rows FROM sysindexes WHERE id = OBJECT_ID(table1) AND indid < 2
Ещё 35 вопросов с ответами опубликуем в следующей части… Следите за новостями!
Источник: https://habr.com/post/461067/
Оператор SQL DELETE для удаления данных из таблицы
Оператор SQL DELETE предназначен для удаления данных из таблицы. Он имеет следующий синтаксис:
DELETE FROM ИМЯ_ТАБЛИЦЫ WHERE УСЛОВИЕ
Если не указывать условие, из таблицы будут удалены все строки. Кроме того, следует помнить, что могут быть удалены лишь строки с первичными ключами, на которые не ссылаются внешние ключи в других таблицах (более подробно об ограничениях удаления — в уроке Реляционная модель данных).
Если вы хотите выполнить запросы к базе данных из этого урока на MS SQL Server, но эта СУБД не установлена на вашем компьютере, то ее можно установить, пользуясь инструкцией по этой ссылке.
А скрипт для создания базы данных «Портал объявлений 1», её таблицы и заполения таблицы данных — в файле по этой ссылке.
Пример 1. Итак, есть база портала объявлений. В ней есть таблица Ads, содержащая данные о объявлениях, поданных за неделю (более подробно — в уроке об агрегатных функциях SQL, пример 7). Таблица выглядит так:
| Id | Category | Part | Units | Money |
| 1 | Транспорт | Автомашины | 110 | 17600 |
| 2 | Недвижимость | Квартиры | 89 | 18690 |
| 3 | Недвижимость | Дачи | 57 | 11970 |
| 4 | Транспорт | Мотоциклы | 131 | 20960 |
| 5 | Стройматериалы | Доски | 68 | 7140 |
| 6 | Электротехника | Телевизоры | 127 | 8255 |
| 7 | Электротехника | Холодильники | 137 | 8905 |
| 8 | Стройматериалы | Регипс | 112 | 11760 |
| 9 | Досуг | Книги | 96 | 6240 |
| 10 | Недвижимость | Дома | 47 | 9870 |
| 11 | Досуг | Музыка | 117 | 7605 |
| 12 | Досуг | Игры | 41 | 2665 |
Требуется удалить из таблицы строку, имеющую идентификатор 4. Для этого пишем следующий запрос (на MS SQL Server — с предваряющей конструкцией USE adportal1;):
DELETE FROM ADS WHERE Id=4
- Пример 2. Можно удалить и несколько строк, если в условии применить оператор сравнения «больше» или «меньше» (на MS SQL Server — с предваряющей конструкцией USE adportal1;):
- DELETE FROM ADS WHERE Id>4
- В результате в таблице останутся лишь следующие строки:
| Id | Category | Part | Units | Money |
| 5 | Стройматериалы | Доски | 68 | 7140 |
| 6 | Электротехника | Телевизоры | 127 | 8255 |
| 7 | Электротехника | Холодильники | 137 | 8905 |
| 8 | Стройматериалы | Регипс | 112 | 11760 |
| 9 | Досуг | Книги | 96 | 6240 |
| 10 | Недвижимость | Дома | 47 | 9870 |
| 11 | Досуг | Музыка | 117 | 7605 |
| 12 | Досуг | Игры | 41 | 2665 |
Пример 3. Аналогично можно удалять строки с заданными значениями любого столбца. Удалим, например, строки об объявлениях, за которые выручено менее 10000 денежных единиц (запрос на MS SQL Server — с предваряющей конструкцией USE adportal1;):
DELETE FROM ADS WHERE Money
В результате в таблице останутся лишь следующие строки:
| Id | Category | Part | Units | Money |
| 1 | Транспорт | Автомашины | 110 | 17600 |
| 2 | Недвижимость | Квартиры | 89 | 18690 |
| 3 | Недвижимость | Дачи | 57 | 11970 |
| 4 | Транспорт | Мотоциклы | 131 | 20960 |
| 8 | Стройматериалы | Регипс | 112 | 11760 |
Для удаления всех строк из таблицы применяется оператор SQL DELETE без условий, заданных в секции WHERE и без любых других ограничей и условий, например, диапазона удаляемых строк. Таким образом, для удаления всех строк синтаксис оператора DELETE будет следующим (на MS SQL Server — с предваряющей конструкцией USE adportal1;):
DELETE FROM ИМЯ_ТАБЛИЦЫ
- Пример 4. Чтобы удалить все данные из таблицы ADS, достаточно написать следующий запрос:
- DELETE FROM ADS
- Если после выполнения этого запроса обратиться к таблице ADS при помощи оператора SELECT, применяемого для получения выборки данных, то будет выведено сообщение о том, что эта таблица не содержит данных.
Оператору DELETE без условий и ограничений аналогичен оператор TRUNCATE TABLE. Он также удаляет из таблицы все строки, но выполняется намного быстрее.
Пример 5. Запрос на удаление всех данных из таблицы ADS при помощи оператора TRUNCATE TABLE будет следующим (на MS SQL Server — с предваряющей конструкцией USE adportal1;):
TRUNCATE TABLE ADS
- Примеры запросов к базе данных «Портал объявлений-1» есть также в уроках об операторах INSERT, UPDATE, HAVING и UNION.
- Поделиться с друзьями
- Реляционные базы данных и язык SQL


Источник: https://function-x.ru/sql_delete.html
DELETE. Удаление записей в таблице базы данных MySQL
Если вам необходимо удалить одну, несколько или все записи в таблице базы данных, то с этим вам поможет команда DELETE.
Синтаксис запроса на удаление записи.
DELETE FROM table_name WHERE condition;
DELETE FROM table_name WHERE condition;
Будьте предельно внимательны при выполнении запросов на удаление записей! Если вы не укажите команду WHERE и последующее условие, то будут удалены все записи в таблице.
Удаление нескольких записей таблицы
Для примера удалим несколько записей из таблицы books, которая хранится в базе данных Bookstore.
Оповестим сервер MySQL о базе данных, для которой будут выполнятся запросы.
Далее выведем записи таблицы books с идентификаторами с 1 по 5.
mysql> SELECT id, title, author, price, discount FROM books WHERE id BETWEEN 1 AND 5; +—-+————————+——————————+———+———-+ | id | title | author | price | discount | +—-+————————+——————————+———+———-+ | 1 | Капитанская дочка | А.С.Пушкин | 151.20 | 0 | | 2 | Мертвые души | Н.В.Гоголь | 141.00 | 0 | | 3 | Анна Каренина | Л.Н.Толстой | 135.00 | 20 | | 4 | Бесы | Ф.М.Достоевский | 122.00 | 0 | | 5 | Нос | Н.В.Гоголь | 105.00 | 0 | +—-+————————+——————————+———+———-+ 5 rows in set (0.00 sec)
mysql>
Допустим необходимо удалить все записи с книгами за авторством Н.В.Гоголя. Запрос на удаление и его результат будет выглядеть следующим образом.
mysql> DELETE FROM books WHERE author=’Н.В.Гоголь’; Query OK, 2 rows affected (0.00 sec)
mysql> SELECT id, title, author, price, discount FROM books WHERE id BETWEEN 1 AND 5;
+—-+————————+——————————+———+———-+ | id | title | author | price | discount | +—-+————————+——————————+———+———-+ | 1 | Капитанская дочка | А.С.Пушкин | 151.20 | 0 | | 3 | Анна Каренина | Л.Н.Толстой | 135.00 | 20 | | 4 | Бесы | Ф.М.Достоевский | 122.00 | 0 | +—-+————————+——————————+———+———-+ 3 rows in set (0.00 sec)
mysql>
Удаление всех записей таблицы
Если вам нужно очистить всю таблицу от имеющихся в ней данных, то просто выполните команду DELETE без каких либо условий.
Следующая команда удалит все записи в таблице books.
Для удаления нескольких несвязанных записей, удобнее воспользоваться HTML-формой, где в конце каждой строки будет стоять поле для флага (checkbox), при установке которого, строка будет считаться выделенной для удаления.
Создадим файл index.php, в котором выведем первые 5 записей таблицы books и разместим в них код формы с полем для флага.
«; echo «
«; foreach ($result_array as $result_row) { echo «
«; echo «
«; echo «
«; echo «
«; echo «
«; echo «»; echo «
| » . $result_row[«id»] . « | » . $result_row[«title»] . « | » . $result_row[«author»] . « | » . $result_row[«price»] . « | » . $result_row[«discount»] . « |
idTitleAuthorPriceDiscountУдалить запись
«; echo «Ошибка при удалении записи в базе данных: » . $e->getMessage();
Откроем в браузере страницу index.php и увидим следующую таблицу с записями.
 Вывод записей из таблицы books с возможностью их удаления
Вывод записей из таблицы books с возможностью их удаления
Для того чтобы наша форма сработала, необходимо также создать файл delete.php, в котором будем обрабатывать полученные от формы идентификаторы записей, а также составим и выполним запрос на удаление выбранных записей.
$db_server = «localhost»;$db_password = «MySafePass4!»; // Открываем соединение, указываем адрес сервера, имя бд, имя пользователя и пароль $db = new PDO(«mysql:host=$db_server;dbname=$db_name», $db_user, $db_password); // Устанавливаем атрибут сообщений об ошибках (выбрасывать исключения) $db->setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION); // Создаем массив, в котором будем хранить идентификаторы записей $ids_to_delete = array(); // Переносим данные (отмеченные записи) из полей формы в массив foreach($_POST[‘delete_row’] as $selected){ $ids_to_delete[] = $selected; // Если пользователь не отметил ни одной записи для удаления, // то прерываем выполнение кода if(empty($ids_to_delete)){ echo «Вы не выделили ни одной записи для удаления!»; // Если есть хоть одно заполненное поле формы (запись выделена для удаления), if(sizeof($ids_to_delete > 0)){ // Запрос на удаление выделенных записей в таблице $sql = «DELETE FROM books WHERE id IN (» . implode(‘,’, array_map(‘intval’, $ids_to_delete)) . «)»; // Перед тем как выполнять запрос предлагаю убедится, что он составлен без ошибок. $statement = $db->prepare($sql); echo «Записи c id: » . implode(‘,’, array_map(‘intval’, $ids_to_delete)) . » успешно удалены!»; echo «Ошибка при удалении записи в базе данных: » . $e->getMessage();
Теперь после того как мы выбрали две записи на удаление, а файл delete.php успешно получил данные и выполнил составленный запрос, мы увидим таблицу, в которой записи с идентификаторами 4 и 5 будут отсутствовать, а на их место сдвинутся записи идущие далее.
 Результат работы файла delete.php (записи с id =4 и id=5 — удалены)
Результат работы файла delete.php (записи с id =4 и id=5 — удалены)
Заключение
В данной статье мы рассмотрели правила и возможности использования команды DELETE для удаления записей из таблицы базы данных, используя терминал. Также увидели, то как быстро можно удалить сразу несколько записей из таблицы с помощью PHP (PDO).
Источник: https://meliorem.ru/backend/mysql/delete-udalenie-zapisej-v-tablice-bazy-dannyx-mysql/
Transact-SQL — изменение и удаление данных
138
Работа с базами данных в .NET Framework — SQL Server 2012 — Изменение и удаление данных
Исходники баз данных
Инструкция UPDATE
Инструкция UPDATE используется для модифицирования строк таблицы. Эта инструкция имеет следующую общую форму:
UPDATE tab_name
{ SET column_1 = {expression | DEFAULT | NULL} [,…n]
[FROM tab_name1 [,…n]]
[WHERE condition] Соглашения по синтаксису
Строки таблицы tab_name выбираются для изменения в соответствии с условием в предложении WHERE.
Значения столбцов каждой модифицируемой строки изменяются с помощью предложения SET инструкции UPDATE, которое соответствующему столбцу присваивает выражение (обычно) или константу.
Если предложение WHERE отсутствует, то инструкция UPDATE модифицирует все строки таблицы. С помощью инструкции UPDATE данные можно модифицировать только в одной таблице.
В примере ниже инструкция UPDATE изменяет всего лишь одну строку таблицы Works_on, поскольку комбинация столбцов EmpId и ProjectNumber является первичным ключом этой таблицы и, следственно, она однозначна. В данном примере изменяется должность сотрудника, значение которого было ранее неизвестно или имело значение NULL:
USE SampleDb;
UPDATE Works_on
SET Job = ‘Менеджер’
WHERE EmpId = 9031 AND ProjectNumber = ‘p3’;
В примере ниже значения строкам таблицы присваиваются посредством выражения. Запрос пересчитывает бюджеты всех проектов с долларов на евро:
USE SampleDb;
UPDATE Project
SET Budget = Budget * 0.9;
В данном примере изменяются все строки таблицы Project, поскольку в запросе отсутствует предложение WHERE.
В примере ниже в предложении WHERE инструкции UPDATE используется вложенный запрос. Поскольку применяется оператор IN, то этот запрос может возвратить более одной строки:
USE SampleDb;
UPDATE Works_on
SET Job = NULL
WHERE EmpId IN (SELECT Id
FROM Employee
WHERE LastName = ‘Вершинина’);
Согласно этому запросу, для сотрудницы Вершининой Натальи во всех ее проектах в столбце ее должности присваивается значение NULL. Запрос в этом примере можно также выполнить посредством предложения FROM инструкции UPDATE.
В предложении FROM указываются имена таблиц, которые обрабатываются инструкцией UPDATE. Все эти таблицы должны быть в дальнейшем соединены. Применение предложения FROM показано в примере ниже.
Логически, этот пример идентичен предыдущему:
USE SampleDb;
UPDATE Works_on
SET Job = NULL
FROM Works_on, Employee
WHERE LastName = ‘Вершинина’
AND Works_on.EmpId = Employee.Id;
В примере ниже показано использование выражения CASE в инструкции UPDATE. (Подробное рассмотрение этого выражения описывалось ранее.) В данном примере нужно увеличить бюджет всех проектов на определенное число процентов (20, 10 или 5), в зависимости от исходной суммы бюджета: чем меньше бюджет, тем больше должно быть его процентное увеличение:
USE SampleDb; UPDATE Project SET Budget = CASE WHEN Budget > 0 AND Budget 100000 AND Budget < 150000 THEN Budget * 1.1 ELSE Budget * 1.05 END;
Инструкция DELETE удаляет строки из таблицы. Подобно инструкции INSERT, эта инструкция также имеет две различные формы:
DELETE FROM table_name
[WHERE predicate];
DELETE table_name
FROM table_name [,…n]
[WHERE condition]; Соглашения по синтаксису
Удаляются все строки, которые удовлетворяют условие в предложении WHERE.
Явно перечислять столбцы в инструкции DELETE не то чтобы нет необходимости, а даже не разрешается, поскольку эта инструкция оперирует строками, а не столбцами.
Использование первой формы инструкции DELETE показано в примере ниже, в котором происходит удаление из таблицы Works_on всех сотрудников с должностью ‘Менеджер’:
USE SampleDb;
DELETE FROM Works_on
WHERE Job = ‘Менеджер’;
Предложение WHERE инструкции DELETE может содержать вложенный запрос, как это показано в примере ниже:
USE SampleDb;
DELETE FROM Works_on
WHERE EmpId IN
(SELECT Id
FROM Employee
WHERE LastName = ‘Вершинина’);
DELETE FROM Employee
WHERE LastName = ‘Вершинина’;
Поскольку сотрудница Вершинина уволилась, из базы данных удаляются все записи, связанные с ней. Запрос из этого примера можно также выполнить с помощью предложения FROM, как это показано ниже. В данном случае семантика этого предложения такая же, как и предложения FROM в инструкции UPDATE.
USE SampleDb;
DELETE Works_on
FROM Works_on w, Employee e
WHERE w.EmpId = e.Id
AND LastName = ‘Вершинина’;
DELETE FROM Employee
WHERE LastName = ‘Вершинина’;
Использование предложения WHERE в инструкции DELETE не является обязательным. Если это предложение отсутствует, то из таблицы удаляются все строки:
USE SampleDb;
— Удаление всех строк таблицы
DELETE FROM Works_on;
Инструкции DELETE и DROP TABLE существенно отличаются друг от друга.
Инструкция DELETE удаляет (частично или полностью) содержимое таблицы, тогда как инструкция DROP TABLE удаляет как содержимое, так и схему таблицы.
Таким образом, после удаления всех строк посредством инструкции DELETE таблица продолжает существовать в базе данных, а после выполнения инструкции DROP TABLE таблица больше не существует.
Другие инструкции и предложения Transact-SQL для модификации таблиц
Сервер SQL Server поддерживает следующие дополнительные инструкции и предложения для модификации таблиц:
- инструкцию TRUNCATE TABLE;
- инструкцию MERGE;
- предложение OUTPUT.
Эти инструкции и предложение рассматриваются в последующих подразделах.
Инструкция TRUNCATE TABLE
Инструкция TRUNCATE TABLE является более быстрой версией инструкции DELETE без предложения WHERE.
Эта инструкция удаляет все строки таблицы более быстро, чем инструкция DELETE, поскольку она удаляет содержимое постранично, тогда как инструкция DELETE делает это построчно. Инструкция TRUNCATE TABLE является расширением Transact-SQL стандарта SQL.
Еще одним важным отличием этой инструкции является то, что она сбрасывает индекс столбца, для которого указано свойство автоинкремента IDENTITY.
Инструкция TRUNCATE TABLE имеет следующий синтаксис:
TRUNCATE TABLE table_name
Инструкция MERGE
Инструкция MERGE объединяет последовательность инструкций INSERT, UPDATE и DELETE в одну элементарную инструкцию, в зависимости от существования записи (строки). Иными словами, можно синхронизировать две разные таблицы, чтобы модифицировать содержимое таблицы назначения в зависимости от различий, обнаруженных в таблице-источнике.
Основной областью применения для инструкции MERGE является среда хранилищ данных, где таблицы необходимо периодически обновлять, чтобы отражать новые данные, прибывающие с систем оперативной обработки транзакций OLTP (On-Line Transaction Processing).
Эти данные могут содержать изменения существующих строк таблиц и/или новый строки, которые нужно вставить в таблицы. Если строка в новых данных соответствует записи, которая уже имеется в таблице, выполняется инструкция UPDATE или DELETE.
В противном случае выполняется инструкция INSERT.
Альтернативно, вместо инструкции MERGE можно использовать последовательность инструкций INSERT, UPDATE и DELETE, в которых для каждой строки решается, какую операцию выполнять: вставку, удаление или обновление. Но этот подход имеет значительный недостаток, связанный с производительностью: в нем требуется выполнять несколько проходов по данным, а данные обрабатываются по принципу «запись за записью».
Предложение OUTPUT
По умолчанию единым видимым результатом выполнения инструкции INSERT, UPDATE или DELETE является только сообщение о количестве модифицированных строк, например «3 rows DELETED» (удалены 3 строки) и система не сохраняет информацию о модифицированных данных. Если такой видимый результат не удовлетворяет вашим требованиям, то можно использовать предложение OUTPUT, которое выводит модифицированные, вставленные или удаленные строки.
Предложение OUTPUT также применимо с инструкцией MERGE, для которой оно выводит все модифицированные строки в виде таблицы.
Результаты выполненных операций соответствующих инструкций предложение OUTPUT выводит в таблицах inserted и deleted. Кроме этого, чтобы заполнить таблицы, в предложении OUTPUT требуется использовать выражение INTO. Поэтому для сохранения результата используется табличная переменная.
В примере ниже показано использование инструкции OUTPUT с инструкцией DELETE:
USE SampleDb;
DELETE FROM Works_on;
— В эту переменную будут сохраняться удаленные данные
DECLARE @deleteTable TABLE (Id INT, LastName NCHAR(20));
DELETE Employee
OUTPUT deleted.Id, deleted.LastName INTO @deleteTable
WHERE Id > 12000;
SELECT * FROM @deleteTable;
При условии, что содержимое таблицы находится в исходном состоянии, выполнение запроса в примере дает следующий результат:

В этом примере сначала объявляется табличная переменная @deleteTable с двумя столбцами: Id и LastName. В этой таблице будут сохранены удаленные строки.
Синтаксис инструкции DELETE расширен предложением OUTPUT: «OUTPUT deleted.Id, deleted.LastName INTO @deleteTable».
Посредством этого предложения система сохраняет удаленные строки в таблице deleted, содержимое которой потом копируется в переменную @deleteTable.
В примере ниже показано использование предложения OUTPUT в инструкции UPDATE:
USE SampleDb;
— Перед запуском этого примера, нужно
— будет восстановить исходные данные в базе
DECLARE @updateTable TABLE (Id INT, ProjectNumber NCHAR(20), oldJob NCHAR(15), newJob NCHAR(15));
UPDATE Works_on
SET Job = ‘Менеджер’
OUTPUT deleted.EmpId, deleted.ProjectNumber,
deleted.Job, inserted.Job INTO @updateTable
WHERE Job = ‘Консультант’;
SELECT Id, ProjectNumber,
oldJob ‘Старая работа’, newJob ‘Новая работа’
FROM @updateTable;
Результат выполнения этого запроса:

Источник: https://professorweb.ru/my/sql-server/2012/level2/2_16.php
Удаление записей из базы данных SQL

- Удаление записей
- Для удаления записей из таблицы применяется оператор DELETE:
- DELETE FROM имяТаблицы WHERE условие;
Данный оператор удаляет из указанной таблицы записи (а не отдельные значения столбцов), которые удовлетворяют указанному условию. Условие — это логическое выражение, различные конструкции которого были рассмотрены в предыдущих лабораторных занятиях.
- Следующий запрос удаляет записи из таблицы Customer, в которой значение столбца LName равно ‘Иванов’:
- DELETE FROM Customer
- WHERE LName = ‘Иванов’
- Если таблица содержатся сведения о нескольких клиентах с фамилией Иванов, то все они будут удалены.
В операторе WHERE может находиться подзапрос на выборку данных (оператор SELECT). Подзапросы в операторе DELETE работают точно так же, как и в операторе SELECT. Следующий запрос удаляет всех клиентов из города Москва, при этом уникальный идентификатор города возвращается с помощью подзапроса.
DELETE FROM Customer
WHERE IdCity IN (SELECT IdCity FROM City WHERE CityName = ‘Москва’)
Transact-SQL расширяет стандартный SQL, позволяя использовать в инструкции DELETE еще одно предложение FROM.
Это расширение, в котором задается соединение, может быть использовано вместо вложенного запроса в предложении WHERE для указания удаляемых строк.
Оно позволяет задавать данные из второго FROM и удалять соответствующие строки из таблицы в первом предложении FROM. В частности предыдущий запрос может быть переписан следующим образом
DELETE FROM Customer
FROM Customer k INNER JOIN
City c ON k.IdCity = c.IdCity AND c.CityName = ‘Москва’
Операция удаления записей из таблицы является опасной в том смысле, что связана с риском необратимых потерь данных в случае семантических (но не синтаксических) ошибок при формулировке SQL-выражения.
Чтобы избежать неприятностей, перед удалением записей рекомендуется сначала выполнить соответствующий запрос на выборку, чтобы просмотреть, какие записи будут удалены.
Так, например, перед выполнением рассмотренного ранее запроса на удаление не помешает выполнить соответствующий запрос на выборку.
SELECT *
FROM Customer k INNER JOIN
City c ON k.IdCity = c.IdCity AND c.CityName = ‘Москва’
Для удаления всех записей из таблицы достаточно использовать оператор DELETE без ключевого слова WHERE. При этом сама таблица со всеми определенными в ней столбцами сохраняется и готова для вставки новых записей. Например, следующий запрос удаляет записи обо всех товарах.
DELETE FROM Product
Задание для самостоятельной работы: Сформулируйте на языке SQL запрос на удаление всех заказов, не имеющих в составе ни одного товара (т. е. все пустые заказы).
Источник: http://www.ikasteko.ru/page/delete_udalenie_iz_bd_sql
Удаление существующего экземпляра — SQL Server
- 12/13/2019
- Время чтения: 4 мин
-
ОБЛАСТЬ ПРИМЕНЕНИЯ: SQL Server (только в Windows) База данных SQL Azure Azure Synapse Analytics (хранилище данных SQL) Parallel Data Warehouse APPLIES TO: SQL Server (Windows only) Azure SQL Database Azure Synapse Analytics (SQL DW) Parallel Data Warehouse
В данной статье описан процесс удаления изолированного экземпляра SQL ServerSQL Server.This article describes how to uninstall a stand-alone instance of SQL ServerSQL Server.
Шаги, перечисленные в этой статье, помогут подготовить систему для повторной установки SQL ServerSQL Server.
By following the steps in this article, you also prepare the system so that you can reinstall SQL ServerSQL Server.
- Удаление экземпляра SQL Server должен производить локальный администратор, имеющий разрешения на вход в систему в качестве службы.To uninstall SQL Server, you must be a local administrator with permissions to log on as a service.
- Если на компьютере установлен минимальный требуемый объем физической памяти, увеличьте размер файла подкачки вдвое больше объема физической памяти.If your computer has the minimum required amount of physical memory, increase the size of the page file to two times the amount of physical memory. Нехватка виртуальной памяти может привести к неполному удалению SQL Server.Insufficient virtual memory can result in an incomplete removal of SQL Server.
- В системе с несколькими экземплярами SQL Server служба браузера SQL Server удаляется только после удаления последнего экземпляра SQL Server.On a system with multiple instances of SQL Server, the SQL Server browser service is uninstalled only once the last instance of SQL Server is removed. Службу браузера SQL Server можно удалить вручную через Программы и компоненты на панели управления.The SQL Server Browser service can be removed manually from Programs and Features in the Control Panel.
- При удалении SQL ServerSQL Server удаляются файлы данных tempdb, добавленные во время процесса установки.Uninstalling SQL ServerSQL Server deletes tempdb data files that were added during the install process. Файлы с именем, удовлетворяющим шаблону tempdb_mssql_*.ndf, удаляются, если они существуют в каталоге системной базы данных.Files with tempdb_mssql_*.ndf name pattern are deleted if they exist in the system database directory.
Подготовка.Prepare
-
Резервное копирование данных.Back up your data. Либо создайте полные резервные копии всех баз данных, включая системные базы данных, либо вручную скопируйте MDF- и LDF-файлы в отдельное место.Either create full backups of all databases, including system databases, or manually copy the .mdf and .
ldf files to a separate location. База данных master содержит все сведения на уровне системы для сервера, такие как имена входа и схемы.The master database contains all system level information for the server, such as logins, and schemas.
База данных msdb содержит сведения о заданиях, такие как задания агента SQL Server, журнал резервного копирования и планы обслуживания.The msdb database contains job information such as SQL Server agent jobs, backup history, and maintenance plans. Дополнительные сведения о системных базах данных см.
в разделе Системные базы данных.For more information about system databases see System databases.
Необходимо сохранить следующие файлы баз данных.The files that you must save include the following database files:
master.mdfmaster.mdf mastlog.ldfmastlog.ldf model.mdfmodel.mdf modellog.ldfmodellog.ldf msdbdata.mdfmsdbdata.mdf msdblog.ldfmsdblog.ldf Mssqlsystemresource.mdfMssqlsystemresource.mdf Mssqlsustemresource.ldfMssqlsustemresource.ldf Tempdb.mdfTempdb.mdf Templog.ldfTemplog.ldf ReportServer[$InstanceName]ReportServer[$InstanceName] ReportServer[$InstanceName]TempDBReportServer[$InstanceName]TempDB Примечание
Базы данных ReportServer включены в службы SQL Server Reporting Services.The ReportServer databases are included with SQL Server Reporting Services.
-
Остановите все службы SQL ServerSQL Server.Stop all SQL ServerSQL Server services.
Перед удалением компонентов SQL ServerSQL Server рекомендуется остановить все службы SQL ServerSQL Server.We recommend that you stop all SQL ServerSQL Server services before you uninstall SQL ServerSQL Server components.
Наличие активных соединений может помешать удалению компонентов.Active connections can prevent successful uninstallation.
-
Выбор учетной записи с необходимыми разрешениями.Use an account that has the appropriate permissions. Выполните вход на сервер с учетной записью службы SQL ServerSQL Server или с учетной записью, обладающей аналогичным набором разрешений.
Log on to the server by using the SQL ServerSQL Server service account or by using an account that has equivalent permissions. Например, можно войти на сервер с учетной записью, входящей в локальную группу администраторов.
For example, you can log on to the server by using an account that is a member of the local Administrators group.
УдалениеUninstall
Чтобы удалить SQL Server из Windows 10, Windows Server 2016, Windows Server 2019 и более поздних версий, выполните следующие действия.To uninstall SQL Server from Windows 10, Windows Server 2016, Windows Server 2019, and greater, follow these steps:
-
Чтобы начать процесс удаления, перейдите к Параметры в меню «Пуск» и выберите Приложения.To begin the removal process navigate to Settings from the Start menu and then choose Apps.
-
Введите sql в поле поиска.Search for sql in the search box.
-
Выберите Microsoft SQL Server (версия) (разрядность) .Select Microsoft SQL Server (Version) (Bit). Например, Microsoft SQL Server 2017 (64-bit).For example, Microsoft SQL Server 2017 (64-bit).
-
Выберите Удалить.Select Uninstall.
-
Выберите Удалить во всплывающем диалоговом окне SQL Server, чтобы запустить мастер установки Microsoft SQL Server.Select Remove on the SQL Server dialog pop-up to launch the Microsoft SQL Server installation wizard.
-
На странице Выбор экземпляра воспользуйтесь раскрывающимся списком, чтобы указать удаляемый экземпляр SQL ServerSQL Server, или укажите параметр для удаления только общих компонентов и средств управления SQL ServerSQL Server.
On the Select Instance page, use the drop-down box to specify an instance of SQL ServerSQL Server to remove, or specify the option to remove only the SQL ServerSQL Server shared features and management tools. Чтобы продолжить работу, щелкните Далее.
To continue, select Next.
-
На странице Выбор компонентов укажите компоненты, которые нужно удалить из указанного экземпляра SQL ServerSQL Server.On the Select Features page, specify the features to remove from the specified instance of SQL ServerSQL Server.
-
На странице Все готово для удаления просмотрите список компонентов и функций, подлежащих удалению.On the Ready to Remove page, review the list of components and features that will be uninstalled. Нажмите кнопку Удалить , чтобы начать удалениеClick Remove to begin uninstalling
-
Обновите окно Приложения и компоненты, чтобы убедиться, что экземпляр SQL Server был успешно удален, и определите, какие компоненты SQL Server все еще остались.
Refresh the Apps and Features window to verify the SQL Server instance has been removed successfully, and determine which, if any, SQL Server components still exist. При необходимости удалите эти компоненты из этого окна.
Remove these components from this window as well, if you so choose.
Чтобы удалить SQL Server из Windows Server 2008, Windows Server 2012 и Windows 2012 R2, выполните следующие действия.To uninstall SQL Server from Windows Server 2008, Windows Server 2012 and Windows 2012 R2, follow these steps:
-
Чтобы начать процесс удаления, перейдите в панель управления, а затем выберите Программы и компоненты.To begin the removal process, navigate to the Control Panel and then select Programs and Features.
-
Щелкните правой кнопкой мыши Microsoft SQL Server (версия) (разрядность) и выберите Удалить.Right-click Microsoft SQL Server (Version) (Bit) and select Uninstall. Например, Microsoft SQL Server 2012 (64-bit).For example, Microsoft SQL Server 2012 (64-bit).
-
Выберите Удалить во всплывающем диалоговом окне SQL Server, чтобы запустить мастер установки Microsoft SQL Server.Select Remove on the SQL Server dialog pop-up to launch the Microsoft SQL Server installation wizard.
-
На странице Выбор экземпляра воспользуйтесь раскрывающимся списком, чтобы указать удаляемый экземпляр SQL ServerSQL Server, или укажите параметр для удаления только общих компонентов и средств управления SQL ServerSQL Server.
On the Select Instance page, use the drop-down box to specify an instance of SQL ServerSQL Server to remove, or specify the option to remove only the SQL ServerSQL Server shared features and management tools. Чтобы продолжить работу, щелкните Далее.
To continue, select Next.
-
На странице Выбор компонентов укажите компоненты, которые нужно удалить из указанного экземпляра SQL ServerSQL Server.On the Select Features page, specify the features to remove from the specified instance of SQL ServerSQL Server.
-
На странице Все готово для удаления просмотрите список компонентов и функций, подлежащих удалению.On the Ready to Remove page, review the list of components and features that will be uninstalled. Нажмите кнопку Удалить , чтобы начать удалениеClick Remove to begin uninstalling
-
Обновите окно Программы и компоненты, чтобы убедиться, что экземпляр SQL Server был успешно удален, и определите, какие компоненты SQL Server все еще остались.
Refresh the Programs and Features window to verify the SQL Server instance has been removed successfully, and determine which, if any, SQL Server components still exist. При необходимости удалите эти компоненты из этого окна.
Remove these components from this window as well, if you so choose.
В случае сбояin the event of failure
В случае сбоя процесса удаления изучите файлы журнала установки SQL Server, чтобы определить основную причину.If the removal process fails, review the SQL Server setup log files to determine the root cause.
Статья базы знаний Обнаружение проблем установки SQL Server в файлах журнала установки может помочь в расследовании.
The KB article How to identify SQL Server setup issues in the setup log files can assist in the investigation. Хотя она предназначена для SQL Server 2008, описываемая методология применима к каждой версии SQL Server.
Though it is for SQL Server 2008, the methodology described is applicable to every version of SQL Server.
См. также:See Also
Просмотр и чтение файлов журналов программы установки SQL ServerView and Read SQL Server Setup Log Files
Отправить отзыв о следующем:
Этот продукт
Вы также можете оставить отзыв непосредственно на GitHub .
Источник: https://docs.microsoft.com/ru-ru/sql/sql-server/install/uninstall-an-existing-instance-of-sql-server-setup?view=sql-server-2017
SQL
(Structured
Query
Language)
– структурированный язык запросов –
является инструментом, предназначенным
для выборки и обработки информации,
содержащейся в компьютерной базе данных.
SQL
является языком программирования,
применяемым для организации взаимодействия
пользователя с базой данных (рис.
44).
SQL
работает только с реляционными базами
данных и предоставляет пользователю
следующие функциональные возможности:
-
изменение
структуры представления данных; -
выборка
данных из базы данных; -
обработка
базы данных, т. е. добавление новых
данных, изменение, удаление имеющихся
данных; -
управление
доступом к базе данных; -
совместное
использование базы данных пользователями,
работающими параллельно; -
обеспечение
целостности базы данных.
SQL
– это не полноценный компьютерный язык
типа PASCAL,
C++,
JAVA.
Еще раз отметим, что SQL,
также как и QBE,
является непроцедурным языком. С помощью
SQL
описываются свойства и взаимосвязи
сущностей (объектов, переменных и т. п.
), но не алгоритмы решения задачи. Он не
содержит условных операторов, операторов
цикла, организации подпрограмм,
ввода-вывода и т. п. В связи с этим SQL
автономно не используется. Инструкции
SQL
встраиваются в программу, написанную
на традиционном языке программирования
и дают возможность получить доступ к
базам данных (встроенный
SQL).
Кроме того, из таких языков, С, C++,
JAVA
инструкции SQL
можно посылать СУБД в явном виде,
используя интерфейс вызовов функций. 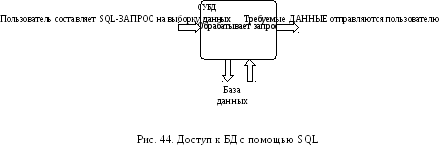
Язык
SQL
является многофункциональным языком.
Во-первых, SQL
используется в качестве языка интерактивных
запросов пользователей с целью выборки
данных и в качестве встроенного языка
программирования баз данных. Кроме
того, SQL
используется в качестве языка
администрирования БД для определения
структуры базы данных и управления
доступом к данным, находящимся на
сервере; в качестве языка создания
приложений клиент/сервер, доступа к
данным в среде Internet,
распределенных баз данных.
С
помощью SQL
можно динамически
изменять и расширять структуру базы
данных даже в то время, когда пользователи
работают с ее содержимым. Таким образом,
SQL
обеспечивает максимальную гибкость.
Статические
языки определения данных запрещают
доступ к БД во время изменения ее
структуры
Официальный
стандарт языка SQL
был опубликован ANSI
и ISO
в 1986 г. В дальнейшем,
он был расширен стандартами SQL-89 (1989 г.)
и SQL-92 (1992 г.). Действующая версия стандарта
SQL:1999 была принята ANSI и ISO в конце 1999 г. В
настоящее время ведется работа над
стандартом для SQL3, содержащим
объектно-ориентированные расширения.
Кроме
перечисленных выше версий языка SQL для
универсальных ЭВМ
существует множество версий типа
«клиент-сервер», а также версий SQL
для персональных компьютеров.
Основные инструкции языка sql
Основные
задачи, решаемые средствами языка SQL
– манипулирование различными объектами
базы данных (таблицами, индексами,
представлениями и т. д.) и манипулирование
данными, хранящимися в таблицах базы
данных. В связи с этим, язык SQL
принято делить на две части: язык
определения данных DDL
и язык манипулирования данными DML.
Основные инструкции языка SQL
представлены в табл.
10.
При
описании синтаксиса инструкций будем
использовать следующие правила:
-
каждая
инструкция начинается с команды
–
ключевого
слова, описывающего действие, выполняемое
инструкцией (например, CREATE
– создать, DELETE
– удалить и т. д.); -
после
команды следует одно или несколько
предложений,
описывающих данные, с которыми работает
инструкция, или содержащих дополнительную
информацию о действии, выполняемом
инструкцией. Каждое предложение
начинается с ключевого слова, например,
WHERE
(где), FROM
(откуда), INTO
(куда), HAVING
(имеющий); -
в
квадратные скобки «[…]»
заключены необязательные элементы; -
вертикальная
черта «|» , разделяющая два элемента,
указывает на то, что в инструкции
используется либо один элемент, либо
второй; -
в
фигурные скобки «{…}»заключаются
элементы, разделенные вертикальной
чертой; -
троеточие
означает, что далее в инструкции либо
следует выражение, либо повторяются
элементы, указанные перед тремя
точками.
Таблица
10
Инструкции
языка SQL
|
Вид |
Название |
Назначение |
|
DDL |
CREATE |
Добавление |
|
DROP |
Удаление |
|
|
ALTER |
Изменение |
|
|
CREATE |
Создание |
|
|
DROP |
Удаление |
|
|
CREATE |
Создание |
|
|
DROP |
Удаление |
|
|
GRAND |
Назначение |
|
|
REVOKE |
Удаление |
|
|
CREATE |
Добавление |
|
|
DROP |
Удаление |
|
|
DML |
SELECT |
Выборка |
|
UPDATE |
Обновление |
|
|
INSERT |
Вставка |
|
|
DELETE |
Удаление |
Рассмотрим
основные инструкции языка SQL.
Инструкция
создания
таблицы
имеет формат вида:
CREATE
TABLE
<имя таблицы>
(<имя
столбца> <тип данных> [NOT
NULL]
[,<имя
столбца> <тип данных> [NOT
NULL]]…
)
После
выполнения инструкции появляется новая
таблица, которой присваивается имя,
указанное в инструкции. Имя таблицы
(как и имена других объектов – столбцов
и пользователей) согласно стандарту
ANSI/ISO
должны содержать от 1 до 18 символов,
начинаться с буквы и не содержать
пробелов или специальных символов
пунктуации (на практике поддержка имен
в различных СУБД реализована по-разному).
Обязательными
операндами данной инструкции являются
имя создаваемой таблицы и имя хотя бы
одного столбца с указанием типа данных,
хранимых в этом столбце. SQL
поддерживает различные типы данных:
целые числа, числа с плавающей запятой,
строки символов, значения даты и времени
и др. В общем случае в современных СУБД
могут использоваться самые разнообразные
дополнительные типы данных, расширяющие
базовый набор SQL.
При
создании таблицы для отдельных столбцов
могут указываться некоторые дополнительные
правила контроля вводимых в них значений.
Конструкция – NOT
NULL
(не пустое) служит именно таким целям и
для столбца таблицы означает, что в этом
столбце должно быть непустое (определенное)
значение.
Пример
3.28. Создание
таблицы
Пусть
требуется определить таблицу ORDERS
и ее столбцы. Инструкция для определения
таблицы может иметь следующий вид:
CREATE
TABLE ORDERS
(ORDER_NUM
INTEGER NOT NULL, CUST_NUM INTEGER NOT NULL, PROD_ID INTEGER NOT
NULL, QTY INTEGER NOT NULL, DATE_ORDER DATE NOT NULL)
где
INTEGER
обозначает тип данных целое число, а
DATE – тип данных, обозначающих значения
даты.
В
процессе работы у пользователей возникает
необходимость добавить в таблицу
информацию. Инструкция
изменения
структуры таблицы
имеет формат вида:
ALTER
TABLE
<имя таблицы>
{ADD|ALTER|DROP}
<имя столбца> [<тип данных>]
[NOT
NULL]
[,{ADD|ALTER|DROP}
<имя столбца> [<тип данных>]
[NOT
NULL],..]
Изменение
структуры таблицы может состоять в
добавлении (ADD),
изменении (ALTER)
или удалении (DROP)
одного или нескольких столбцов таблицы.
Пример
3.29. Добавление
столбца таблицы
Добавим
в созданную ранее таблицу CUST
столбец CUST_PHN,
содержащий телефоны клиентов. Для этого
следует записать инструкцию вида:
ALTER
TABLE
CUST
ADD
CUST_PHN
CHAR
(10)
Пример
3.30. Удаление
столбца
Удалим
из таблицы PROD
столбец STORE.
(Примеры рассматриваются без учета
ограничений целостности).
ALTER
TABLE
PROD
DROP
STORE
Инструкция
удаления
таблицы имеет формат вида:
DROP
TABLE
<имя та6лицы>
Например,
для удаления таблицы с именем SALE
достаточно записать оператор вида:
DROP
TABLE
SALE
Одним
из структурных элементов физической
памяти является индекс.
Индекс – это средство, обеспечивающее
быстрый доступ к строкам таблицы на
основе значений одного или нескольких
столбцов. В индексе хранятся значения
данных и указатели на строки, где эти
данные встречаются. Данные в индексе
располагаются в убывающем или в
возрастающем порядке, чтобы СУБД могла
быстро найти требуемое значение. Затем
по указателю СУБД сможет быстро определить
строку, содержащую требуемое значение.
Инструкция
создания
индекса
имеет формат вида:
CREATE
[UNIQUE]
INDEX
<имя индекса> ОN <имя таблицы> (<имя
столбца> [ ASC|
DESC]
[,<имя
столбца> [ASC|
DESC],…
)
Оператор
позволяет создать индекс для одного
или нескольких столбцов заданной таблицы
с целью ускорения выполнение запросных
и поисковых операций с таблицей. Для
одной таблицы можно создать несколько
индексов.
Необязательная
опция UNIQUE
обеспечивает запрет задания совпадающих
значений для индекса. По существу,
создание индекса с указанием признака
UNIQUE
означает определение ключа в созданной
ранее таблице.
При
создании индекса можно задать порядок
автоматической сортировки значений в
столбцах – в порядке возрастания ASC
(по умолчанию), или в порядке убывания
DESC.
Для разных столбцов можно задавать
различный порядок сортировки.
Пример
3.31. Создание
индекса
Пусть
из таблице CUST
часто извлекаются данные по названию
фирм-клиентов. Можно создать индекс
main_index
для сортировки названий фирм-клиентов
в алфавитном порядке по возрастанию.
Оператор
создания
индекса
может
иметь
вид:
CREATE
INDEX main_index ON CUST
(CUST_NAME)
Инструкция
удаления
индекса
имеет формат вида:
DROP
INDEX<имя
индекса>
Эта
инструкция позволяет удалять созданный
ранее индекс с соответствующим именем.
Так, например, для уничтожения индекса
main_index
к таблице CUST
достаточно записать инструкцию DROP
INDEX
main_index.
Кроме
таблиц и индексов существуют другие
объекты базы данных, например,
представления. Представление является
«виртуальной» таблицей, содержащей
набор столбцов одной или нескольких
таблиц. Однако, в отличие от таблицы,
представление как совокупность значений
в базе данных реально не существует.
Представление определяется как запрос
на выборку данных, которому присвоили
имя и сохранили в базе данных. Представление
позволяет пользователю увидеть результаты
сохраненного запроса.
Инструкция
создания
представления
имеет формат вида:
CREATE
VIEW<имя
представления>
[(<имя
столбца> [,<имя столбца> ]…)]
AS
<оператор SELECT>
При
необходимости можно задать имя для
каждого столбца создаваемого представления.
Список имен столбцов должен содержать
столько элементов, сколько столбцов
содержится в запросе. Если список имен
в инструкции отсутствует, то каждый
столбец представления получает имя
соответствующего столбца запроса.
Пример
3.32. Создание
представления
Необходимо
создать представление c
именем CUSTINF
таблицы
CUST,
включающее только названия клиентов и
их номера.
CREATE
VIEW CUSTINF
AS
SELECT CUST_NUM, CUST_NAME
FROM
CUST
Создать
представление ORDER_CUS,
показывающее заказы сделанные клиентом
3105.
CREATE
VIEW ORDER_CUS
AS
SELECT
FROM
ORDERS
WHERE
CUST_NUM=3105
Инструкция
удаления
представления
имеет формат
вида:
DROP
VIEW
<имя представления>
Оператор
позволяет удалить созданное ранее
представление. Заметим, что при этом
таблицы, участвующие в запросе, удалению
не подлежат. Удаление представления
ORDER_CUS
производится инструкцией вида:
DROP
VIEW
ORDER_CUS
Представления
широко применяются для ограничения
доступа пользователей ко всей информации
в таблицах базы данных.
Пример
3.33. Использование
инструкции GRAND
и REVOKE
Можно
определить права доступа к таблицам
базы данных с помощью инструкций GRAND
и REVOKE.
Например, инструкция
GRAND
INSERT
ON
CUST
TO
PETROV
разрешает
сотруднику Петрову ввод данных в таблицу
CUST.
Следующая
инструкция отменяет привилегии сотрудника
Иванова на изменение данных о клиентах
и чтение информации о них
REVOKE
UPDATE, SELECT
ON
CUST
TO
IVANOV
Запросы
являются фундаментом SQL.
Многие разработчики используют SQL
исключительно в качестве инструмента
для создания запросов. Поэтому важнейшей
инструкцией является инструкция
SELECT,
которая используется для построения
SQL-запросов:
SELECT
[ALL | DISTINCT]<список
данных>
FROM
<список таблиц>
[WHERE
<условие отбора>]
[GROUP
BY
<имя столбца> [,<имя столбца>]… ]
[HAVING
<условие поиска>]
[ORDER
BY
<спецификация> [,<спецификация>]…]
Оператор
SELECT
позволяет производить выборку и
вычисления над данными из одной или
нескольких таблиц. В предложении
SELECT
указывается список возвращаемых
столбцов, разделенных запятыми. Для
каждого элемента из списка в ответной
таблице будет создан один столбец.
Ответная таблица может иметь (ALL),
или не иметь (DISTINCT)
повторяющиеся строки. По умолчанию в
ответную таблицу включаются все строки,
в том числе и повторяющиеся. Список
данных может содержать выражения над
столбцами, показывающие, что наряду с
выборкой данных выполняются вычисления,
результаты которого попадают в новый
(создаваемый) столбец ответной таблицы
В
отборе данных участвуют записи одной
или нескольких таблиц, перечисленных
в списке предложения FROM.
Такие таблицы называют исходными
таблицами запроса.
При
использовании в списках данных имен
столбцов нескольких таблиц для указания
принадлежности столбца некоторой
таблице применяют конструкцию вида:
<имя таблицы>.<имя столбца>.
Предложение
WHERE
задает условия, которым должны
удовлетворять строки в результирующей
таблице. Вслед за ключевым словом WHERE
указывается логическое выражение
<условие
отбора>.
Его элементами могут быть имена столбцов,
операции сравнения, арифметические
операции, логические операции (И, ИЛИ,
НЕТ), скобки, специальные функции LIKE
и т.д.
Предложение
GROUP
BY
содержит список столбцов, которые
используются для группировки строк.
Группой
называются строки с совпадающими
значениями в столбцах, перечисленных
за ключевыми словами GROUP
BY.
Для сгруппированных данных можно
использовать статистические функции:
AVG
(среднее значение в группе), МАХ
(максимальное значение в группе), MIN
(минимальное значение в группе), SUM
(сумма
значений в группе), COUNT
(число значений в группе).
Вслед
за предложением HAVING
указывается логическое выражение
<условия поиска>, определяющее, какие
из отобранных и сгруппированных строк
будут отображаться в результирующем
наборе данных. Правила записи аналогичны
правилам формирования <условия отбора>
предложения WHERE.
Предложение
ORDER
BY
задает порядок сортировки результирующего
множества строк. Обычно каждая
<спецификация> аналогична соответствующей
конструкции оператора CREATE
INDEX
и представляет собой конструкцию вида:
<имя столбца> [ ASC
| DESC].
Пример
3.34. Выбор
строк
Пусть
требуется вывести названия товаров и
их цену. Инструкцию выбора можно записать
следующим образом:
SELECT
PROD_NAME, PRICE
FROM
PROD
Пример
3.35. Выбор с
условием
Вывести
названия товаров, цена которых больше
100$. Инструкцию SELECT
для этого запроса можно
записать
так:
SELECT
PROD_NAME
FROM
PROD
WHERE
PRICE>100
Пример
3. 36. Выбор с
сортировкой
Строки
результатов запроса, как и строки таблицы
базы данных, не имеют определенного
порядка. Включив в инструкцию SELECT
предложение ORDER BY, можно отсортировать
результаты запроса.
Пусть
требуется вывести название клиентов и
годовой объем заказов. Последний столбец
отсортировать по возрастанию. По
умолчанию данные сортируются по
возрастанию.
SELECT
CUST_NAME, CUST_SUM
FROM
CUST
ORDER
BY CUST_SUM
Пример
3.37. Получение
итоговых данных
Каков
средний объем заказов?
Этот
запрос обеспечивает вычисление среднего
объема заказов, используя данные из
таблицы CUST
SELECT
AVG (CUST_SUM)
FROM
CUST
Пример
3.38. Вычисляемые
столбцы
Например,
требуется вычислить стоимость остатков
товара, хранящихся на складе. Данные
вывести по каждому товару. Значения
вычисляемых столбцов определяются на
основе выражения, указанного в списке
возвращаемых столбцов.
SELECT
PROD_NAME, PRICE, STORE, (PRICE* STORE)
FROM
PROD
Пусть
требуется увеличить цену каждого товара
на 5%. Запрос можно сформулировать
следующим образом:
SELECT
PROD_NAME, PRICE, (PRICE*1.05)
FROM
PROD
Во
многих СУБД реализованы дополнительные
арифметические операции, операции над
строками, встроенные функции для работы
со значениями даты и времени.
Например,
требуется вывести номер заказа, месяц
и год его поставки. Запрос
выглядит
следующим
образом:
SELECT
ORDER_NUM, MONTH (DATE_ORDER), YEAR (DATE_ORDER)
FROM
ORDERS
Пример
3.39. Выбор
всех столбцов
Иногда
требуется получить содержимое всех
столбцов таблицы. С учетом этого в SQL
разрешается использовать вместо списка
возвращаемых столбцов символ «*».
SELECT
*
FROM
ORDERS
Пример
3.40. Повторяющиеся
строки
Результаты
запроса могут содержать повторяющиеся
строки. Например, требуется вывести
номера клиентов, сделавших заказы, из
таблицы ORDERS.
Клиенты 3101, 3105, 3103 сделали более, чем по
одному заказу, поэтому строки с их
номерами будут повторяться. Для исключения
повторяющихся строк используется
предикат DISTINCT.
SELECT
DISTINCT
CUST_NUM
FROM
ORDERS
Пример
3.41. Выбор с
группированием
Пусть
требуется найти минимальное и максимальное
заказанное количество для каждого из
видов товаров. Оператор SELECT
для этого запроса имеет вид:
SELECT
PROD_ID,
MIN
(QTY
), MAX
(QTY
)
FROM
ORDERS
GROUP
BY PROD_ID
Запрос
выполняется следующим образом: заказы
делятся на группы, по одной группе на
каждый товар. Затем для каждой группы
вычисляется максимальное и минимальное
значения столбца QTY
по всем строкам, входящим в группу, и
генерируется одна итоговая строка
результатов.
Пример
3.42. Условия
отбора групп
Предложение
HAVING
можно использовать для отбора групп
строк, участвующих в запросе. Пусть
требуется найти максимальное заказанное
количество каждого товара. Общее
количество заказанного товара не должно
превышать 20.
SELECT
PROD_ID, MAX (QTY )
FROM
ORDERS
GROUP
BY PROD_ID
HAVING
SUM
(QTY
)<=20
При
реализации данного запроса, вначале
заказы разделяются на группы по видам
товаров. Затем исключаются те группы,
в которых общее количество заказанного
товара превышает 20. И после этого в
оставшихся группах определяется
максимальное заказанное количество
каждого товара.
Пример
3.43.
Многотабличные запросы
На
практике, многие запросы считывают
информацию сразу из нескольких таблиц
базы данных. Например, необходимо вывести
список всех заказов, а также название
клиента, сделавшего заказ. Инструкция
SELECT
должна содержать условие отбора, которое
определяет связь между столбцами таблиц
ORDERS
и CUST.
SELECT
ORDER_NUM, CUST_NAME, PROD_ID, QTY, DATE_ORDER
FROM
ORDERS, CUST
WHERE
CUST.CUST_NUM=ORDERS.CUST_NUM
Приведенный
запрос отличается от предыдущих,
во-первых, тем, что предложение FROM
содержит не
одну, а две таблицы. Во-вторых, в условии
отбора WHERE
CUST.CUST_NUM=ORDERS.CUST_NUM
сравниваются столбцы из двух различных
таблиц. Эти столбцы называются связанными.
В
данном примере, столбцы, используемые
из разных таблиц, имеют одинаковые
имена. В этом случае необходимо указывать
полные имена столбцов, которые однозначно
определяют их местонахождение.
Инструкция
на изменения
строк имеет
формат вида:
UPDATE
<имя таблицы>
SET
<имя столбца> = {<выражение> | NULL}
[,SET
<имя столбца> = {<выражение> |
NULL}…
]
[WHERE
<условие>]
Инструкция
UPDATE
обновляет значения в определенных
предложением SET
столбцах таблицы для тех строк, которые
удовлетворяют условию, заданному
предложением WHERE.
Новые
значения столбцов могут быть пустыми
(NULL),
либо вычисляться в соответствии с
арифметическим выражением.
Пример
3.44. Изменение
строк
Пусть
необходимо увеличить на 15% цену только
тех товаров, которые стоят меньше 100$.
Запрос, сформулированный с помощью
оператора UPDATE,
может выглядеть так:
UPDATE
PROD
SET
PRICE=( PRICE*1.15)
WHERE
PRICE
<=100
Инструкция
для вставки
новых строк
имеет форматы двух видов:
INSERT
INTO
<имя таблицы> [(<список столбцов>)]
VALUES
(<список значений>)
и
INSERT
INTO
<имя таблицы> [(<список столбцов>)]
<предложение
SELECT>
В
первом формате оператор INSERT
предназначен для одной строки с заданными
значениями в столбцах. Порядок перечисления
имен столбцов должен соответствовать
порядку значений, перечисленных в списке
предложения VALUES.
Если <список столбцов> опущен, то в
<списке значений> должны быть
перечислены все значения в порядке
столбцов структуры таблицы.
Во
втором формате оператор INSERT
предназначен для ввода в заданную
таблицу новых
строк, отобранных из другой таблицы с
помощью предложения SELECT.
Пример
3.45.
Ввести
в таблицу CUST
строку, содержащую сведения о новом
клиенте. Для этого можно записать
инструкцию такого вида:
INSERT
INTO
CUST
Вступление и DDL – Data Definition Language (язык описания данных)
Часть первая — habrahabr.ru/post/255361
DML – Data Manipulation Language (язык манипулирования данными)
В первой части мы уже немного затронули язык DML, применяя почти весь набор его команд, за исключением команды MERGE.
Рассказывать про DML я буду по своей последовательности выработанной на личном опыте. По ходу, так же постараюсь рассказать про «скользкие» места, на которые стоит акцентировать внимание, эти «скользкие» места, схожи во многих диалектах языка SQL.
Т.к. учебник посвящается широкому кругу читателей (не только программистам), то и объяснение, порой будет соответствующее, т.е. долгое и нудное. Это мое видение материала, которое в основном получено на практике в результате профессиональной деятельности.
Основная цель данного учебника, шаг за шагом, выработать полное понимание сути языка SQL и научить правильно применять его конструкции. Профессионалам в этой области, может тоже будет интересно пролистать данный материал, может и они смогут вынести для себя что-то новое, а может просто, будет полезно почитать в целях освежить память. Надеюсь, что всем будет интересно.
Т.к. DML в диалекте БД MS SQL очень сильно связан с синтаксисом конструкции SELECT, то я начну рассказывать о DML именно с нее. На мой взгляд конструкция SELECT является самой главной конструкцией языка DML, т.к. за счет нее или ее частей осуществляется выборка необходимых данных из БД.
Язык DML содержит следующие конструкции:
- SELECT – выборка данных
- INSERT – вставка новых данных
- UPDATE – обновление данных
- DELETE – удаление данных
- MERGE – слияние данных
В данной части, мы рассмотрим, только базовый синтаксис команды SELECT, который выглядит следующим образом:
SELECT [DISTINCT] список_столбцов или *
FROM источник
WHERE фильтр
ORDER BY выражение_сортировки
Тема оператора SELECT очень обширная, поэтому в данной части я и остановлюсь только на его базовых конструкциях. Я считаю, что, не зная хорошо базы, нельзя приступать к изучению более сложных конструкций, т.к. дальше все будет крутиться вокруг этой базовой конструкции (подзапросы, объединения и т.д.).
Также в рамках этой части, я еще расскажу о предложении TOP. Это предложение я намерено не указал в базовом синтаксисе, т.к. оно реализуется по-разному в разных диалектах языка SQL.
Если язык DDL больше статичен, т.е. при помощи него создаются жесткие структуры (таблицы, связи и т.п.), то язык DML носит динамический характер, здесь правильные результаты вы можете получить разными путями.
Обучение так же будет продолжаться в режиме Step by Step, т.е. при чтении нужно сразу же своими руками пытаться выполнить пример. После делаете анализ полученного результата и пытаетесь понять его интуитивно. Если что-то остается непонятным, например, значение какой-нибудь функции, то обращайтесь за помощью в интернет.
Примеры будут показываться на БД Test, которая была создана при помощи DDL+DML в первой части.
Для тех, кто не создавал БД в первой части (т.к. не всех может интересовать язык DDL), может воспользоваться следующим скриптом:
Скрипт создания БД Test
-- создание БД
CREATE DATABASE Test
GO
-- сделать БД Test текущей
USE Test
GO
-- создаем таблицы справочники
CREATE TABLE Positions(
ID int IDENTITY(1,1) NOT NULL CONSTRAINT PK_Positions PRIMARY KEY,
Name nvarchar(30) NOT NULL
)
CREATE TABLE Departments(
ID int IDENTITY(1,1) NOT NULL CONSTRAINT PK_Departments PRIMARY KEY,
Name nvarchar(30) NOT NULL
)
GO
-- заполняем таблицы справочники данными
SET IDENTITY_INSERT Positions ON
INSERT Positions(ID,Name)VALUES
(1,N'Бухгалтер'),
(2,N'Директор'),
(3,N'Программист'),
(4,N'Старший программист')
SET IDENTITY_INSERT Positions OFF
GO
SET IDENTITY_INSERT Departments ON
INSERT Departments(ID,Name)VALUES
(1,N'Администрация'),
(2,N'Бухгалтерия'),
(3,N'ИТ')
SET IDENTITY_INSERT Departments OFF
GO
-- создаем таблицу с сотрудниками
CREATE TABLE Employees(
ID int NOT NULL,
Name nvarchar(30),
Birthday date,
Email nvarchar(30),
PositionID int,
DepartmentID int,
HireDate date NOT NULL CONSTRAINT DF_Employees_HireDate DEFAULT SYSDATETIME(),
ManagerID int,
CONSTRAINT PK_Employees PRIMARY KEY (ID),
CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID),
CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID),
CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID),
CONSTRAINT UQ_Employees_Email UNIQUE(Email),
CONSTRAINT CK_Employees_ID CHECK(ID BETWEEN 1000 AND 1999),
INDEX IDX_Employees_Name(Name)
)
GO
-- заполняем ее данными
INSERT Employees (ID,Name,Birthday,Email,PositionID,DepartmentID,ManagerID)VALUES
(1000,N'Иванов И.И.','19550219','i.ivanov@test.tt',2,1,NULL),
(1001,N'Петров П.П.','19831203','p.petrov@test.tt',3,3,1003),
(1002,N'Сидоров С.С.','19760607','s.sidorov@test.tt',1,2,1000),
(1003,N'Андреев А.А.','19820417','a.andreev@test.tt',4,3,1000)
Все, теперь мы готовы приступить к изучению языка DML.
SELECT – оператор выборки данных
Первым делом, для активного редактора запроса, сделаем текущей БД Test, выбрав ее в выпадающем списке или же командой «USE Test».
Начнем с самой элементарной формы SELECT:
SELECT *
FROM Employees
В данном запросе мы просим вернуть все столбцы (на это указывает «*») из таблицы Employees – можно прочесть это как «ВЫБЕРИ все_поля ИЗ таблицы_сотрудники». В случае наличия кластерного индекса, возвращенные данные, скорее всего будут отсортированы по нему, в данном случае по колонке ID (но это не суть важно, т.к. в большинстве случаев сортировку мы будем указывать в явном виде сами при помощи ORDER BY …):
| ID | Name | Birthday | PositionID | DepartmentID | HireDate | ManagerID | |
|---|---|---|---|---|---|---|---|
| 1000 | Иванов И.И. | 1955-02-19 | i.ivanov@test.tt | 2 | 1 | 2015-04-08 | NULL |
| 1001 | Петров П.П. | 1983-12-03 | p.petrov@test.tt | 3 | 3 | 2015-04-08 | 1003 |
| 1002 | Сидоров С.С. | 1976-06-07 | s.sidorov@test.tt | 1 | 2 | 2015-04-08 | 1000 |
| 1003 | Андреев А.А. | 1982-04-17 | a.andreev@test.tt | 4 | 3 | 2015-04-08 | 1000 |
Вообще стоит сказать, что в диалекте MS SQL самая простая форма запроса SELECT может не содержать блока FROM, в этом случае вы можете использовать ее, для получения каких-то значений:
SELECT
5550/100*15,
SYSDATETIME(), -- получение системной даты БД
SIN(0)+COS(0)
| (No column name) | (No column name) | (No column name) |
|---|---|---|
| 825 | 2015-04-11 12:12:36.0406743 | 1 |
Обратите внимание, что выражение (5550/100*15) дало результат 825, хотя если мы посчитаем на калькуляторе получится значение (832.5). Результат 825 получился по той причине, что в нашем выражении все числа целые, поэтому и результат целое число, т.е. (5550/100) дает нам 55, а не (55.5).
Запомните следующее, что в MS SQL работает следующая логика:
- Целое / Целое = Целое (т.е. в данном случае происходит целочисленное деление)
- Вещественное / Целое = Вещественное
- Целое / Вещественное = Вещественное
Т.е. результат преобразуется к большему типу, поэтому в 2-х последних случаях мы получаем вещественное число (рассуждайте как в математике – диапазон вещественных чисел больше диапазона целых, поэтому и результат преобразуется к нему):
SELECT
123/10, -- 12
123./10, -- 12.3
123/10. -- 12.3
Здесь (123.) = (123.0), просто в данном случае 0 можно отбросить и оставить только точку.
При других арифметических операциях действует та же самая логика, просто в случае деления этот нюанс более актуален.
Поэтому обращайте внимание на тип данных числовых столбцов. В том случае если он целый, а результат вам нужно получить вещественный, то используйте преобразование, либо просто ставьте точку после числа указанного в виде константы (123.).
Для преобразования полей можно использовать функцию CAST или CONVERT. Для примера воспользуемся полем ID, оно у нас типа int:
SELECT
ID,
ID/100, -- здесь произойдет целочисленное деление
CAST(ID AS float)/100, -- используем функцию CAST для преобразования в тип float
CONVERT(float,ID)/100, -- используем функцию CONVERT для преобразования в тип float
ID/100. -- используем преобразование за счет указания что знаменатель вещественное число
FROM Employees
| ID | (No column name) | (No column name) | (No column name) | (No column name) |
|---|---|---|---|---|
| 1000 | 10 | 10 | 10 | 10.000000 |
| 1001 | 10 | 10.01 | 10.01 | 10.010000 |
| 1002 | 10 | 10.02 | 10.02 | 10.020000 |
| 1003 | 10 | 10.03 | 10.03 | 10.030000 |
На заметку. В БД ORACLE синтаксис без блока FROM недопустим, там для этой цели используется системная таблица DUAL, которая содержит одну строку:
SELECT 5550/100*15, -- а в ORACLE результат будет равен 832.5 sysdate, sin(0)+cos(0) FROM DUAL
Примечание. Имя таблицы во многих РБД может предваряться именем схемы:
SELECT * FROM dbo.Employees -- dbo – имя схемыСхема – это логическая единица БД, которая имеет свое наименование и позволяет сгруппировать внутри себя объекты БД такие как таблицы, представления и т.д.
Определение схемы в разных БД может отличатся, где-то схема непосредственно связанна с пользователем БД, т.е. в данном случае можно сказать, что схема и пользователь – это синонимы и все создаваемые в схеме объекты по сути являются объектами данного пользователя. В MS SQL схема – это независимая логическая единица, которая может быть создана сама по себе (см. CREATE SCHEMA).
По умолчанию в базе MS SQL создается одна схема с именем dbo (Database Owner) и все создаваемые объекты по умолчанию создаются именно в данной схеме. Соответственно, если мы в запросе указываем просто имя таблицы, то она будет искаться в схеме dbo текущей БД. Если мы хотим создать объект в конкретной схеме, мы должны будем так же предварить имя объекта именем схемы, например, «CREATE TABLE имя_схемы.имя_таблицы(…)».
В случае MS SQL имя схемы может еще предваряться именем БД, в которой находится данная схема:
SELECT * FROM Test.dbo.Employees -- имя_базы.имя_схемы.таблицаТакое уточнение бывает полезным, например, если:
- в одном запросе мы обращаемся к объектам расположенных в разных схемах или базах данных
- требуется сделать перенос данных из одной схемы или БД в другую
- находясь в одной БД, требуется запросить данные из другой БД
- и т.п.
Схема – очень удобное средство, которое полезно использовать при разработке архитектуры БД, а особенно крупных БД.
Так же не забываем, что в тексте запроса мы можем использовать как однострочные «— …», так и многострочные «/* … */» комментарии. Если запрос большой и сложный, то комментарии могут очень помочь, вам или кому-то другому, через некоторое время, вспомнить или разобраться в его структуре.
Если столбцов в таблице очень много, а особенно, если в таблице еще очень много строк, плюс к тому если мы делаем запросы к БД по сети, то предпочтительней будет выборка с непосредственным перечислением необходимых вам полей через запятую:
SELECT ID,Name
FROM Employees
Т.е. здесь мы говорим, что нам из таблицы нужно вернуть только поля ID и Name. Результат будет следующим (кстати оптимизатор здесь решил воспользоваться индексом, созданным по полю Name):
| ID | Name |
|---|---|
| 1003 | Андреев А.А. |
| 1000 | Иванов И.И. |
| 1001 | Петров П.П. |
| 1002 | Сидоров С.С. |
На заметку. Порой бывает полезным посмотреть на то как осуществляется выборка данных, например, чтобы выяснить какие индексы используются. Это можно сделать если нажать кнопку «Display Estimated Execution Plan – Показать расчетный план» или установить «Include Actual Execution Plan – Включить в результат актуальный план выполнения запроса» (в данном случае мы сможем увидеть уже реальный план, соответственно, только после выполнения запроса):
Анализ плана выполнения очень полезен при оптимизации запроса, он позволяет выяснить каких индексов не хватает или же какие индексы вообще не используются и их можно удалить.
Если вы только начали осваивать DML, то сейчас для вас это не так важно, просто возьмите на заметку и можете спокойно забыть об этом (может это вам никогда и не пригодится) – наша первоначальная цель изучить основы языка DML и научится правильно применять их, а оптимизация это уже отдельное искусство. Порой важнее, чтобы на руках просто был правильно написанный запрос, который возвращает правильные результат с предметной точки зрения, а его оптимизацией уже занимаются отдельные люди. Для начала вам нужно научиться просто правильно писать запросы, используя любые средства для достижения цели. Главная цель которую вы сейчас должны достичь – чтобы ваш запрос возвращал правильные результаты.
Задание псевдонимов для таблиц
При перечислении колонок их можно предварять именем таблицы, находящейся в блоке FROM:
SELECT Employees.ID,Employees.Name
FROM Employees
Но такой синтаксис обычно использовать неудобно, т.к. имя таблицы может быть длинным. Для этих целей обычно задаются и применяются более короткие имена – псевдонимы (alias):
SELECT emp.ID,emp.Name
FROM Employees AS emp
или
SELECT emp.ID,emp.Name
FROM Employees emp -- ключевое слово AS можно отпустить (я предпочитаю такой вариант)
Здесь emp – псевдоним для таблицы Employees, который можно будет использоваться в контексте данного оператора SELECT. Т.е. можно сказать, что в контексте этого оператора SELECT мы задаем таблице новое имя.
Конечно, в данном случае результаты запросов будут точно такими же как и для «SELECT ID,Name FROM Employees». Для чего это нужно будет понятно дальше (даже не в этой части), пока просто запоминаем, что имя колонки можно предварять (уточнять) либо непосредственно именем таблицы, либо при помощи псевдонима. Здесь можно использовать одно из двух, т.е. если вы задали псевдоним, то и пользоваться нужно будет им, а использовать имя таблицы уже нельзя.
На заметку. В ORACLE допустим только вариант задания псевдонима таблицы без ключевого слова AS.
DISTINCT – отброс строк дубликатов
Ключевое слово DISTINCT используется для того чтобы отбросить из результата запроса строки дубликаты. Грубо говоря представьте, что сначала выполняется запрос без опции DISTINCT, а затем из результата выбрасываются все дубликаты. Продемонстрируем это для большей наглядности на примере:
-- создадим для демонстрации временную таблицу
CREATE TABLE #Trash(
ID int NOT NULL PRIMARY KEY,
Col1 varchar(10),
Col2 varchar(10),
Col3 varchar(10)
)
-- наполним данную таблицу всяким мусором
INSERT #Trash(ID,Col1,Col2,Col3)VALUES
(1,'A','A','A'), (2,'A','B','C'), (3,'C','A','B'), (4,'A','A','B'),
(5,'B','B','B'), (6,'A','A','B'), (7,'A','A','A'), (8,'C','A','B'),
(9,'C','A','B'), (10,'A','A','B'), (11,'A',NULL,'B'), (12,'A',NULL,'B')
-- посмотрим что возвращает запрос без опции DISTINCT
SELECT Col1,Col2,Col3
FROM #Trash
-- посмотрим что возвращает запрос с опцией DISTINCT
SELECT DISTINCT Col1,Col2,Col3
FROM #Trash
-- удалим временную таблицу
DROP TABLE #Trash
Наглядно это будет выглядеть следующим образом (все дубликаты помечены одним цветом):

Теперь давайте рассмотрим где это можно применить, на более практичном примере – вернем из таблицы Employees только уникальные идентификаторы отделов (т.е. узнаем ID отделов в которых числятся сотрудники):
SELECT DISTINCT DepartmentID
FROM Employees
| DepartmentID |
|---|
| 1 |
| 2 |
| 3 |
Здесь мы получили три строки, т.к. 2 сотрудника у нас числятся в одном отделе (ИТ).
Теперь узнаем в каких отделах, какие должности фигурируют:
SELECT DISTINCT DepartmentID,PositionID
FROM Employees
| DepartmentID | PositionID |
|---|---|
| 1 | 2 |
| 2 | 1 |
| 3 | 3 |
| 3 | 4 |
Здесь мы получили 4 строчки, т.к. повторяющихся комбинаций (DepartmentID, PositionID) в нашей таблице нет.
Ненадолго вернемся к DDL
Так как данных для демонстрационных примеров начинает не хватать, а рассказать хочется более обширно и понятно, то давайте чуть расширим нашу таблицу Employess. К тому же немного вспомним DDL, как говорится «повторение – мать учения», и плюс снова немного забежим вперед и применим оператор UPDATE:
-- создаем новые колонки
ALTER TABLE Employees ADD
LastName nvarchar(30), -- фамилия
FirstName nvarchar(30), -- имя
MiddleName nvarchar(30), -- отчество
Salary float, -- и конечно же ЗП в каких-то УЕ
BonusPercent float -- процент для вычисления бонуса от оклада
GO
-- наполняем их данными (некоторые данные намерено пропущены)
UPDATE Employees
SET
LastName=N'Иванов',FirstName=N'Иван',MiddleName=N'Иванович',
Salary=5000,BonusPercent= 50
WHERE ID=1000 -- Иванов И.И.
UPDATE Employees
SET
LastName=N'Петров',FirstName=N'Петр',MiddleName=N'Петрович',
Salary=1500,BonusPercent= 15
WHERE ID=1001 -- Петров П.П.
UPDATE Employees
SET
LastName=N'Сидоров',FirstName=N'Сидор',MiddleName=NULL,
Salary=2500,BonusPercent=NULL
WHERE ID=1002 -- Сидоров С.С.
UPDATE Employees
SET
LastName=N'Андреев',FirstName=N'Андрей',MiddleName=NULL,
Salary=2000,BonusPercent= 30
WHERE ID=1003 -- Андреев А.А.
Убедимся, что данные обновились успешно:
SELECT *
FROM Employees
| ID | Name | … | LastName | FirstName | MiddleName | Salary | BonusPercent |
|---|---|---|---|---|---|---|---|
| 1000 | Иванов И.И. | Иванов | Иван | Иванович | 5000 | 50 | |
| 1001 | Петров П.П. | Петров | Петр | Петрович | 1500 | 15 | |
| 1002 | Сидоров С.С. | Сидоров | Сидор | NULL | 2500 | NULL | |
| 1003 | Андреев А.А. | Андреев | Андрей | NULL | 2000 | 30 |
Задание псевдонимов для столбцов запроса
Думаю, здесь будет проще показать, чем написать:
SELECT
-- даем имя вычисляемому столбцу
LastName+' '+FirstName+' '+MiddleName AS ФИО,
-- использование двойных кавычек, т.к. используется пробел
HireDate AS "Дата приема",
-- использование квадратных скобок, т.к. используется пробел
Birthday AS [Дата рождения],
-- слово AS не обязательно
Salary ZP
FROM Employees
| ФИО | Дата приема | Дата рождения | ZP |
|---|---|---|---|
| Иванов Иван Иванович | 2015-04-08 | 1955-02-19 | 5000 |
| Петров Петр Петрович | 2015-04-08 | 1983-12-03 | 1500 |
| NULL | 2015-04-08 | 1976-06-07 | 2500 |
| NULL | 2015-04-08 | 1982-04-17 | 2000 |
Как видим заданные нами псевдонимы столбцов, отразились в заголовке результирующей таблицы. Собственно, это и есть основное предназначение псевдонимов столбцов.
Обратите внимание, т.к. у последних 2-х сотрудников не указано отчество (NULL значение), то результат выражения «LastName+’ ‘+FirstName+’ ‘+MiddleName» так же вернул нам NULL.
Для соединения (сложения, конкатенации) строк в MS SQL используется символ «+».
Запомним, что все выражения в которых участвует NULL (например, деление на NULL, сложение с NULL) будут возвращать NULL.
На заметку.
В случае ORACLE для объединения строк используется оператор «||» и конкатенация будет выглядеть как «LastName||’ ‘||FirstName||’ ‘||MiddleName». Для ORACLE стоит отметить, что у него для строковых типов есть исключение, для них NULL и пустая строка » это одно и тоже, поэтому в ORACLE такое выражение вернет для последних 2-х сотрудников «Сидоров Сидор » и «Андреев Андрей ». На момент версии ORACLE 12c, насколько я знаю, опции которая изменяет такое поведение нет (если не прав, прошу поправить меня). Здесь мне сложно судить хорошо это или плохо, т.к. в одних случаях удобнее поведение NULL-строки как в MS SQL, а в других как в ORACLE.В ORACLE тоже допустимы все перечисленные выше псевдонимы столбцов, кроме […].
Для того чтобы не городить конструкцию с использованием функции ISNULL, в MS SQL мы можем применить функцию CONCAT. Рассмотрим и сравним 3 варианта:
SELECT
LastName+' '+FirstName+' '+MiddleName FullName1,
-- 2 варианта для замены NULL пустыми строками '' (получаем поведение как и в ORACLE)
ISNULL(LastName,'')+' '+ISNULL(FirstName,'')+' '+ISNULL(MiddleName,'') FullName2,
CONCAT(LastName,' ',FirstName,' ',MiddleName) FullName3
FROM Employees
| FullName1 | FullName2 | FullName3 |
|---|---|---|
| Иванов Иван Иванович | Иванов Иван Иванович | Иванов Иван Иванович |
| Петров Петр Петрович | Петров Петр Петрович | Петров Петр Петрович |
| NULL | Сидоров Сидор | Сидоров Сидор |
| NULL | Андреев Андрей | Андреев Андрей |
В MS SQL псевдонимы еще можно задавать при помощи знака равенства:
SELECT
'Дата приема'=HireDate, -- помимо "…" и […] можно использовать '…'
[Дата рождения]=Birthday,
ZP=Salary
FROM Employees
Использовать для задания псевдонима ключевое слово AS или же знак равенства, наверное, больше дело вкуса. Но при разборе чужих запросов, данные знания могут пригодиться.
Напоследок скажу, что для псевдонимов имена лучше задавать, используя только символы латиницы и цифры, избегая применения ‘…’, «…» и […], то есть использовать те же правила, что мы использовали при наименовании таблиц. Дальше, в примерах я буду использовать только такие наименования и никаких ‘…’, «…» и […].
Основные арифметические операторы SQL
| Оператор | Действие |
|---|---|
| + | Сложение (x+y) или унарный плюс (+x) |
| — | Вычитание (x-y) или унарный минус (-x) |
| * | Умножение (x*y) |
| / | Деление (x/y) |
| % | Остаток от деления (x%y). Для примера 15%10 даст 5 |
Приоритет выполнения арифметических операторов такой же, как и в математике. Если необходимо, то порядок применения операторов можно изменить используя круглые скобки — (a+b)*(x/(y-z)).
И еще раз повторюсь, что любая операция с NULL дает NULL, например: 10+NULL, NULL*15/3, 100/NULL – все это даст в результате NULL. Т.е. говоря просто неопределенное значение не может дать определенный результат. Учитывайте это при составлении запроса и при необходимости делайте обработку NULL значений функциями ISNULL, COALESCE:
SELECT
ID,Name,
Salary/100*BonusPercent AS Result1, -- без обработки NULL значений
Salary/100*ISNULL(BonusPercent,0) AS Result2, -- используем функцию ISNULL
Salary/100*COALESCE(BonusPercent,0) AS Result3 -- используем функцию COALESCE
FROM Employees
| ID | Name | Result1 | Result2 | Result3 |
|---|---|---|---|---|
| 1000 | Иванов И.И. | 2500 | 2500 | 2500 |
| 1001 | Петров П.П. | 225 | 225 | 225 |
| 1002 | Сидоров С.С. | NULL | 0 | 0 |
| 1003 | Андреев А.А. | 600 | 600 | 600 |
| 1004 | Николаев Н.Н. | NULL | 0 | 0 |
| 1005 | Александров А.А. | NULL | 0 | 0 |
Немного расскажу о функции COALESCE:
COALESCE (expr1, expr2, ..., exprn) - Возвращает первое не NULL значение из списка значений.
Пример:
SELECT COALESCE(f1, f1*f2, f2*f3) val -- в данном случае вернется третье значение
FROM (SELECT null f1, 2 f2, 3 f3) q
В основном, я сосредоточусь на рассказе конструкций языка DML и по большей части не буду рассказывать о функциях, которые будут встречаться в примерах. Если вам непонятно, что делает та или иная функция поищите ее описание в интернет, можете даже поискать информацию сразу по группе функций, например, задав в поиске Google «MS SQL строковые функции», «MS SQL математические функции» или же «MS SQL функции обработки NULL». Информации по функциям очень много, и вы ее сможете без труда найти. Для примера, в библиотеке MSDN, можно узнать больше о функции COALESCE:
Вырезка из MSDN Сравнение COALESCE и CASE
Выражение COALESCE — синтаксический ярлык для выражения CASE. Это означает, что код COALESCE(expression1,…n) переписывается оптимизатором запросов как следующее выражение CASE:
CASE WHEN (expression1 IS NOT NULL) THEN expression1 WHEN (expression2 IS NOT NULL) THEN expression2 ... ELSE expressionN END
Для примера рассмотрим, как можно воспользоваться остатком от деления (%). Данный оператор очень полезен, когда требуется разбить записи на группы. Например, вытащим всех сотрудников, у которых четные табельные номера (ID), т.е. те ID, которые делятся на 2:
SELECT ID,Name
FROM Employees
WHERE ID%2=0 -- остаток от деления на 2 равен 0
| ID | Name |
|---|---|
| 1000 | Иванов И.И. |
| 1004 | Николаев Н.Н. |
| 1002 | Сидоров С.С. |
ORDER BY – сортировка результата запроса
Предложение ORDER BY используется для сортировки результата запроса.
SELECT
LastName,
FirstName,
Salary
FROM Employees
ORDER BY LastName,FirstName -- упорядочить результат по 2-м столбцам – по Фамилии, и после по Имени
| LastName | FirstName | Salary |
|---|---|---|
| Андреев | Андрей | 2000 |
| Иванов | Иван | 5000 |
| Петров | Петр | 1500 |
| Сидоров | Сидор | 2500 |
После имя поля в предложении ORDER BY можно задать опцию DESC, которая служит для сортировки этого поля в порядке убывания:
SELECT LastName,FirstName,Salary
FROM Employees
ORDER BY -- упорядочить в порядке
Salary DESC, -- 1. убывания Заработной Платы
LastName, -- 2. по Фамилии
FirstName -- 3. по Имени
| LastName | FirstName | Salary |
|---|---|---|
| Иванов | Иван | 5000 |
| Сидоров | Сидор | 2500 |
| Андреев | Андрей | 2000 |
| Петров | Петр | 1500 |
Для заметки. Для сортировки по возрастанию есть ключевое слово ASC, но так как сортировка по возрастанию применяется по умолчанию, то про эту опцию можно забыть (я не помню случая, чтобы я когда-то использовал эту опцию).
Стоит отметить, что в предложении ORDER BY можно использовать и поля, которые не перечислены в предложении SELECT (кроме случая, когда используется DISTINCT, об этом случае я расскажу ниже). Для примера забегу немного вперед используя опцию TOP и покажу, как например, можно отобрать 3-х сотрудников у которых самая высокая ЗП, с учетом что саму ЗП в целях конфиденциальности я показывать не должен:
SELECT TOP 3 -- вернуть только 3 первые записи из всего результата
ID,LastName,FirstName
FROM Employees
ORDER BY Salary DESC -- сортируем результат по убыванию Заработной Платы
| ID | LastName | FirstName |
|---|---|---|
| 1000 | Иванов | Иван |
| 1002 | Сидоров | Сидор |
Конечно здесь есть случай, что у нескольких сотрудников может быть одинаковая ЗП и тут сложно сказать каких именно трех сотрудников вернет данный запрос, это уже нужно решать с постановщиком задачи. Допустим, после обсуждения с постановщиком данной задачи, вы согласовали и решили использовать следующий вариант – сделать дополнительную сортировку по полю даты рождения (т.е. молодым у нас дорога), а если и дата рождения у нескольких сотрудников может совпасть (ведь такое тоже не исключено), то можно сделать третью сортировку по убыванию значений ID (в последнюю очередь под выборку попадут те, у кого ID окажется максимальным – например, те кто был принят последним, допустим табельные номера у нас выдаются последовательно):
SELECT TOP 3 -- вернуть только 3 первые записи из всего результата
ID,LastName,FirstName
FROM Employees
ORDER BY
Salary DESC, -- 1. сортируем результат по убыванию Заработной Платы
Birthday, -- 2. потом по Дате рождения
ID DESC -- 3. и для полной однозначности результата добавляем сортировку по ID
Т.е. вы должны стараться чтобы результат запроса был предсказуемым, чтобы вы могли в случае разбора полетов объяснить почему в «черный список» попали именно эти люди, т.е. все было выбрано честно, по утверждённым правилам.
Сортировать можно так же используя разные выражения в предложении ORDER BY:
SELECT LastName,FirstName
FROM Employees
ORDER BY CONCAT(LastName,' ',FirstName) -- используем выражение
Так же в ORDER BY можно использовать псевдонимы заданные для колонок:
SELECT CONCAT(LastName,' ',FirstName) fi
FROM Employees
ORDER BY fi -- используем псевдоним
Стоит отметить что в случае использования предложения DISTINCT, в предложении ORDER BY могут использоваться только колонки, перечисленные в блоке SELECT. Т.е. после применения операции DISTINCT мы получаем новый набор данных, с новым набором колонок. По этой причине, следующий пример не отработает:
SELECT DISTINCT
LastName,FirstName,Salary
FROM Employees
ORDER BY ID -- ID отсутствует в итоговом наборе, который мы получили при помощи DISTINCT
Т.е. предложение ORDER BY применяется уже к итоговому набору, перед выдачей результата пользователю.
Примечание 1. Так же в предложении ORDER BY можно использовать номера столбцов, перечисленных в SELECT:
SELECT LastName,FirstName,Salary FROM Employees ORDER BY -- упорядочить в порядке 3 DESC, -- 1. убывания Заработной Платы 1, -- 2. по Фамилии 2 -- 3. по ИмениДля начинающих выглядит удобно и заманчиво, но лучше забыть и никогда не использовать такой вариант сортировки.
Если в данном случае (когда поля явно перечислены), такой вариант еще допустим, то для случая с использованием «*» такой вариант лучше никогда не применять. Почему – потому что, если кто-то, например, поменяет в таблице порядок столбцов, или удалит столбцы (и это нормальная ситуация), ваш запрос может так же работать, но уже неправильно, т.к. сортировка уже может идти по другим столбцам, и это коварно тем что данная ошибка может обнаружиться очень нескоро.
В случае, если бы столбы были явно перечислены, то в вышеуказанной ситуации, запрос либо бы продолжал работать, но также правильно (т.к. все явно определено), либо бы он просто выдал ошибку, что данного столбца не существует.
Так что можете смело забыть, о сортировке по номерам столбцов.
Примечание 2.
В MS SQL при сортировке по возрастанию NULL значения будут отображаться первыми.SELECT BonusPercent FROM Employees ORDER BY BonusPercentСоответственно при использовании DESC они будут в конце
SELECT BonusPercent FROM Employees ORDER BY BonusPercent DESCЕсли необходимо поменять логику сортировки NULL значений, то используйте выражения, например:
SELECT BonusPercent FROM Employees ORDER BY ISNULL(BonusPercent,100)В ORACLE для этой цели предусмотрены 2 опции NULLS FIRST и NULLS LAST (применяется по умолчанию). Например:
SELECT BonusPercent FROM Employees ORDER BY BonusPercent DESC NULLS LASTОбращайте на это внимание при переходе на ту или иную БД.
TOP – возврат указанного числа записей
Вырезка из MSDN. TOP – ограничивает число строк, возвращаемых в результирующем наборе запроса до заданного числа или процентного значения. Если предложение TOP используется совместно с предложением ORDER BY, то результирующий набор ограничен первыми N строками отсортированного результата. В противном случае возвращаются первые N строк в неопределенном порядке.
Обычно данное выражение используется с предложением ORDER BY и мы уже смотрели примеры, когда нужно было вернуть N-первых строк из результирующего набора.
Без ORDER BY обычно данное предложение применяется, когда нужно просто посмотреть на неизвестную нам таблицу, в которой может быть очень много записей, в этом случае мы можем, для примера, попросить вернуть нам только первые 10 строк, но для наглядности мы скажем только 2:
SELECT TOP 2
*
FROM Employees
Так же можно указать слово PERCENT, для того чтобы вернулось соответствуй процент строк из результирующего набора:
SELECT TOP 25 PERCENT
*
FROM Employees
На моей практике чаше применяется именно выборка по количеству строк.
Так же с TOP можно использовать опцию WITH TIES, которая поможет вернуть все строки в случае неоднозначной сортировки, т.е. это предложение вернет все строки, которые равны по составу строкам, которые попадают в выборку TOP N, в итоге строк может быть выбрано больше чем N. Давайте для демонстрации добавим еще одного «Программиста» с окладом 1500:
INSERT Employees(ID,Name,Email,PositionID,DepartmentID,ManagerID,Salary)
VALUES(1004,N'Николаев Н.Н.','n.nikolayev@test.tt',3,3,1003,1500)
и введем еще одного сотрудника без указания должности и отдела с окладом 2000:
INSERT Employees(ID,Name,Email,PositionID,DepartmentID,ManagerID,Salary)
VALUES(1005,N'Александров А.А.','a.alexandrov@test.tt',NULL,NULL,1000,2000)
Теперь давайте выберем при помощи опции WITH TIES всех сотрудников, у которых оклад совпадает с окладами 3-х сотрудников, с самым маленьким окладом (надеюсь дальше будет понятно, к чему я клоню):
SELECT TOP 3 WITH TIES
ID,Name,Salary
FROM Employees
ORDER BY Salary
Здесь хоть и указано TOP 3, но запрос вернул 4 записи, т.к. значение Salary которое вернуло TOP 3 (1500 и 2000) оказалось у 4-х сотрудников. Наглядно это работает примерно следующим образом:

На заметку.
В разных БД TOP реализуется разными способами, в MySQL для этого есть предложение LIMIT, в котором дополнительно можно задать начальное смещение.В ORACLE 12c, тоже ввели свой аналог совмещающий функциональность TOP и LIMIT – ищите по словам «ORACLE OFFSET FETCH». До версии 12c для этой цели обычно использовался псевдостолбец ROWNUM.
А что же будет если применить одновременно предложения DISTINCT и TOP? На такие вопросы легко ответить, проводя эксперименты. В общем, не бойтесь и не ленитесь экспериментировать, т.к. большая часть познается именно на практике. Порядок слов в операторе SELECT следующий, первым идет DISTINCT, а после него идет TOP, т.е. если рассуждать логически и читать слева-направо, то первым применится отброс дубликатов, а потом уже по этому набору будет сделан TOP. Что-ж проверим и убедимся, что так и есть:
SELECT DISTINCT TOP 2
Salary
FROM Employees
ORDER BY Salary
| Salary |
|---|
| 1500 |
| 2000 |
Т.е. в результате мы получили 2 самые маленькие зарплаты из всех. Конечно может быть случай что ЗП для каких-то сотрудников может быть не указанной (NULL), т.к. схема нам это позволяет. Поэтому в зависимости от задачи принимаем решение либо обработать NULL значения в предложении ORDER BY, либо просто отбросить все записи, у которых Salary равна NULL, а для этого переходим к изучению предложения WHERE.
WHERE – условие выборки строк
Данное предложение служит для фильтрации записей по заданному условию. Например, выберем всех сотрудников работающих в «ИТ» отделе (его ID=3):
SELECT ID,LastName,FirstName,Salary
FROM Employees
WHERE DepartmentID=3 -- ИТ
ORDER BY LastName,FirstName
| ID | LastName | FirstName | Salary |
|---|---|---|---|
| 1004 | NULL | NULL | 1500 |
| 1003 | Андреев | Андрей | 2000 |
| 1001 | Петров | Петр | 1500 |
Предложение WHERE пишется до команды ORDER BY.
Порядок применения команд к исходному набору Employees следующий:
- WHERE – если указано, то первым делом из всего набора Employees идет отбор только удовлетворяющих условию записей
- DISTINCT – если указано, то отбрасываются все дубликаты
- ORDER BY – если указано, то делается сортировка результата
- TOP – если указано, то из отсортированного результата возвращается только указанное число записей
Рассмотрим для наглядности пример:
SELECT DISTINCT TOP 1
Salary
FROM Employees
WHERE DepartmentID=3
ORDER BY Salary
Наглядно это будет выглядеть следующим образом:

Стоит отметить, что проверка на NULL делается не знаком равенства, а при помощи операторов IS NULL и IS NOT NULL. Просто запомните, что на NULL при помощи оператора «=» (знак равенства) сравнивать нельзя, т.к. результат выражения будет так же равен NULL.
Например, выберем всех сотрудников, у которых не указан отдел (т.е. DepartmentID IS NULL):
SELECT ID,Name
FROM Employees
WHERE DepartmentID IS NULL
| ID | Name |
|---|---|
| 1005 | Александров А.А. |
Теперь для примера посчитаем бонус для всех сотрудников у которых указано значение BonusPercent (т.е. BonusPercent IS NOT NULL):
SELECT ID,Name,Salary/100*BonusPercent AS Bonus
FROM Employees
WHERE BonusPercent IS NOT NULL
Да, кстати, если подумать, то значение BonusPercent может равняться нулю (0), а так же значение может быть внесено со знаком минус, ведь мы не накладывали на данное поле никаких ограничений.
Хорошо, рассказав о проблеме, нам пока сказали считать, что если (BonusPercent<=0 или BonusPercent IS NULL), то это означает что у сотрудника так же нет бонуса. Для начала, как нам сказали, так и сделаем, реализуем это при помощи логического оператора OR и NOT:
SELECT ID,Name,Salary/100*BonusPercent AS Bonus
FROM Employees
WHERE NOT(BonusPercent<=0 OR BonusPercent IS NULL)
Т.е. здесь мы начали изучать булевы операторы. Выражение в скобках «(BonusPercent<=0 OR BonusPercent IS NULL)» проверяет на то что у сотрудника нет бонуса, а NOT инвертирует это значение, т.е. говорит «верни всех сотрудников которые не сотрудники у которых нет бонуса».
Так же данное выражение можно переписать и сразу сказав сразу «верни всех сотрудников, у которых есть бонус» выразив это выражением (BonusPercent>0 и BonusPercent IS NOT NULL):
SELECT ID,Name,Salary/100*BonusPercent AS Bonus
FROM Employees
WHERE BonusPercent>0 AND BonusPercent IS NOT NULL
Также в блоке WHERE можно делать проверку разного рода выражений с применением арифметических операторов и функций. Например, аналогичную проверку можно сделать, использовав выражение с функцией ISNULL:
SELECT ID,Name,Salary/100*BonusPercent AS Bonus
FROM Employees
WHERE ISNULL(BonusPercent,0)>0
Булевы операторы и простые операторы сравнения
Да, без математики здесь не обойтись, поэтому сделаем небольшой экскурс по булевым и простым операторам сравнения.
Булевых операторов в языке SQL всего 3 – AND, OR и NOT:
| AND | логическое И. Ставится между двумя условиями (условие1 AND условие2). Чтобы выражение вернуло True, нужно, чтобы истинными были оба условия |
|---|---|
| OR | логическое ИЛИ. Ставится между двумя условиями (условие1 OR условие2). Чтобы выражение вернуло True, достаточно, чтобы истинным было только одно условие |
| NOT | инвертирует условие/логическое_выражение. Накладывается на другое выражение (NOT логическое_выражение) и возвращает True, если логическое_выражение = False и возвращает False, если логическое_выражение = True |
Для каждого булева оператора можно привести таблицы истинности где дополнительно показано какой будет результат, когда условия могут быть равны NULL:

Есть следующие простые операторы сравнения, которые используются для формирования условий:
| Условие | Значение |
|---|---|
| = | Равно |
| < | Меньше |
| > | Больше |
| <= | Меньше или равно |
| >= | Больше или равно |
| <> != |
Не равно |
Плюс имеются 2 оператора для проверки значения/выражения на NULL:
| IS NULL | Проверка на равенство NULL |
|---|---|
| IS NOT NULL | Проверка на неравенство NULL |
Приоритет: 1) Все операторы сравнения; 2) NOT; 3) AND; 4) OR.
При построении сложных логических выражений используются круглые скобки:
((условие1 AND условие2) OR NOT(условие3 AND условие4 AND условие5)) OR (…)
Так же при помощи использования круглых скобок, можно изменить стандартную последовательность вычислений.
Здесь я постарался дать представление о булевой алгебре в достаточном для работы объеме. Как видите, чтобы писать условия посложнее без логики уже не обойтись, но ее здесь немного (AND, OR и NOT) и придумывали ее люди, так что все достаточно логично.
Идем к завершению второй части
Как видите даже про базовый синтаксис оператора SELECT можно говорить очень долго, но, чтобы остаться в рамках статьи, напоследок я покажу дополнительные логических операторы – BETWEEN, IN и LIKE.
BETWEEN – проверка на вхождение в диапазон
Этот оператор имеет следующий вид:
проверяемое_значение [NOT] BETWEEN начальное_ значение AND конечное_ значение
В роли значений могут выступать выражения.
Разберем на примере:
SELECT ID,Name,Salary
FROM Employees
WHERE Salary BETWEEN 2000 AND 3000 -- у кого ЗП в диапазоне 2000-3000
| ID | Name | Salary |
|---|---|---|
| 1002 | Сидоров С.С. | 2500 |
| 1003 | Андреев А.А. | 2000 |
| 1005 | Александров А.А. | 2000 |
Собственно, BETWEEN это упрощенная запись вида:
SELECT ID,Name,Salary
FROM Employees
WHERE Salary>=2000 AND Salary<=3000 -- все у кого ЗП в диапозоне 2000-3000
Перед словом BETWEEN может использоваться слово NOT, которое будет осуществлять проверку значения на не вхождение в указанный диапазон:
SELECT ID,Name,Salary
FROM Employees
WHERE Salary NOT BETWEEN 2000 AND 3000 -- аналогично выражению NOT(Salary>=2000 AND Salary<=3000)
Соответственно, в случае использования BETWEEN, IN, LIKE вы можете так же объединять их с другими условиями при помощи AND и OR:
SELECT ID,Name,Salary
FROM Employees
WHERE Salary BETWEEN 2000 AND 3000 -- у кого ЗП в диапазоне 2000-3000
AND DepartmentID=3 -- учитывать сотрудников только отдела 3
IN – проверка на вхождение в перечень значений
Этот оператор имеет следующий вид:
проверяемое_значение [NOT] IN (значение1, значение2, …)
Думаю, проще показать на примере:
SELECT ID,Name,Salary
FROM Employees
WHERE PositionID IN(3,4) -- у кого должность равна 3 или 4
| ID | Name | Salary |
|---|---|---|
| 1001 | Петров П.П. | 1500 |
| 1003 | Андреев А.А. | 2000 |
| 1004 | Николаев Н.Н. | 1500 |
Т.е. по сути это аналогично следующему выражению:
SELECT ID,Name,Salary
FROM Employees
WHERE PositionID=3 OR PositionID=4 -- у кого должность равна 3 или 4
В случае NOT это будет аналогично (получим всех кроме тех, кто из отдела 3 и 4):
SELECT ID,Name,Salary
FROM Employees
WHERE PositionID NOT IN(3,4) -- аналогично выражению NOT(PositionID=3 OR PositionID=4)
Так же запрос с NOT IN можно выразить и через AND:
SELECT ID,Name,Salary
FROM Employees
WHERE PositionID<>3 AND PositionID<>4 -- равносильно PositionID NOT IN(3,4)
Учтите, что искать NULL значения при помощи конструкции IN не получится, т.к. проверка NULL=NULL вернет так же NULL, а не True:
SELECT ID,Name,DepartmentID
FROM Employees
WHERE DepartmentID IN(1,2,NULL) -- NULL записи не войдут в результат
В этом случае разбивайте проверку на несколько условий:
SELECT ID,Name,DepartmentID
FROM Employees
WHERE DepartmentID IN(1,2) -- 1 или 2
OR DepartmentID IS NULL -- или NULL
Или же можно написать что-то вроде:
SELECT ID,Name,DepartmentID
FROM Employees
WHERE ISNULL(DepartmentID,-1) IN(1,2,-1) -- если вы уверены, что в нет и не будет департамента с ID=-1
Думаю, первый вариант, в данном случае будет более правильным и надежным. Ну ладно, это всего лишь пример, для демонстрации того какие еще конструкции можно строить.
Так же стоит упомянуть еще более коварную ошибку, связанную с NULL, которую можно допустить при использовании конструкции NOT IN. Для примера, давайте попробуем выбрать всех сотрудников, кроме тех, у которых отдел равен 1 или у которых отдел вообще не указан, т.е. равен NULL. В качестве решения напрашивается вариант:
SELECT ID,Name,DepartmentID
FROM Employees
WHERE DepartmentID NOT IN(1,NULL)
Но выполнив запрос, мы не получим ни одной строки, хотя мы ожидали увидеть следующее:
| ID | Name | DepartmentID |
|---|---|---|
| 1001 | Петров П.П. | 3 |
| 1002 | Сидоров С.С. | 2 |
| 1003 | Андреев А.А. | 3 |
| 1004 | Николаев Н.Н. | 3 |
Опять же шутку здесь сыграло NULL указанное в списке значений.
Разберем почему в данном случае возникла логическая ошибка. Разложим запрос при помощи AND:
SELECT ID,Name,DepartmentID
FROM Employees
WHERE DepartmentID<>1
AND DepartmentID<>NULL -- проблема из-за этой проверки на NULL - это условие всегда вернет NULL
Правое условие (DepartmentID<>NULL) нам всегда здесь даст неопределенность, т.е. NULL. Теперь вспомним таблицу истинности для оператора AND, где (TRUE AND NULL) дает NULL. Т.е. при выполнении левого условия (DepartmentID<>1) из-за неопределенного правого условия в результате мы получим неопределенное значение всего выражения (DepartmentID<>1 AND DepartmentID<>NULL), поэтому строка не войдет в результат.
Переписать условие правильно можно следующим образом:
SELECT ID,Name,DepartmentID
FROM Employees
WHERE DepartmentID NOT IN(1) -- или в данном случае просто DepartmentID<>1
AND DepartmentID IS NOT NULL -- и отдельно проверяем на NOT NULL
IN еще можно использовать с подзапросами, но к такой форме мы вернемся, уже в последующих частях данного учебника.
LIKE – проверка строки по шаблону
Про данный оператор я расскажу только в самом простом виде, который является стандартом и поддерживается большинством диалектов языка SQL. Даже в таком виде при помощи него можно решить много задач, которые требуют выполнить проверку по содержимому строки.
Этот оператор имеет следующий вид:
проверяемая_строка [NOT] LIKE строка_шаблон [ESCAPE отменяющий_символ]
В «строке_шаблон» могут применятся следующие специальные символы:
- Знак подчеркивания «_» — говорит, что на его месте может стоять любой единичный символ
- Знак процента «%» — говорит, что на его месте может стоять сколько угодно символов, в том числе и ни одного
Рассмотрим примеры с символом «%» (на практике, кстати он чаще применяется):
SELECT ID,Name
FROM Employees
WHERE Name LIKE 'Пет%' -- у кого имя начинается с букв "Пет"
SELECT ID,LastName
FROM Employees
WHERE LastName LIKE '%ов' -- у кого фамилия оканчивается на "ов"
SELECT ID,LastName
FROM Employees
WHERE LastName LIKE '%ре%' -- у кого фамилия содержит сочетание "ре"
Рассмотрим примеры с символом «_»:
SELECT ID,LastName
FROM Employees
WHERE LastName LIKE '_етров' -- у кого фамилия состоит из любого первого символа и последующих букв "етров"
SELECT ID,LastName
FROM Employees
WHERE LastName LIKE '____ов' -- у кого фамилия состоит из четырех любых символов и последующих букв "ов"
При помощи ESCAPE можно задать отменяющий символ, который отменяет проверяющее действие специальных символов «_» и «%». Данное предложение используется, когда в строке нужно непосредственно проверить наличие знака процента или знака подчеркивания.
Для демонстрации ESCAPE давайте занесем в одну запись мусор:
UPDATE Employees
SET
FirstName='Это_мусор, содержащий %'
WHERE ID=1005
И посмотрим, что вернут следующие запросы:
SELECT *
FROM Employees
WHERE FirstName LIKE '%!%%' ESCAPE '!' -- строка содержит знак "%"
SELECT *
FROM Employees
WHERE FirstName LIKE '%!_%' ESCAPE '!' -- строка содержит знак "_"
В случае, если требуется проверить строку на полное совпадение, то вместо LIKE лучше использовать просто знак «=»:
SELECT *
FROM Employees
WHERE FirstName='Петр'
На заметку.
В MS SQL в шаблоне оператора LIKE так же можно задать поиск по регулярным выражениям, почитайте о нем в интернете, в том случае, если вам станет недостаточно стандартных возможностей данного оператора.В ORACLE для поиска по регулярным выражениям применяется функция REGEXP_LIKE.
Немного о строках
В случае проверки строки на наличие Unicode символов, нужно будет ставить перед кавычками символ N, т.е. N’…’. Но так как у нас в таблице все символьные поля в формате Unicode (тип nvarchar), то для этих полей можно всегда использовать такой формат. Пример:
SELECT ID,Name
FROM Employees
WHERE Name LIKE N'Пет%'
SELECT ID,LastName
FROM Employees
WHERE LastName=N'Петров'
Если делать правильно, при сравнении с полем типа varchar (ASCII) нужно стараться использовать проверки с использованием ‘…’, а при сравнении поля с типом nvarchar (Unicode) нужно стараться использовать проверки с использованием N’…’. Это делается для того, чтобы избежать в процессе выполнения запроса неявных преобразований типов. То же самое правило используем при вставке (INSERT) значений в поле или их обновлении (UPDATE).
При сравнении строк стоит учесть момент, что в зависимости от настройки БД (collation), сравнение строк может быть, как регистро-независимым (когда ‘Петров’=’ПЕТРОВ’), так и регистро-зависимым (когда ‘Петров'<>’ПЕТРОВ’).
В случае регистро-зависимой настройки, если требуется сделать поиск без учета регистра, то можно, например, сделать предварительное преобразование правого и левого выражения в один регистр – верхний или нижний:
SELECT ID,Name
FROM Employees
WHERE UPPER(Name) LIKE UPPER(N'Пет%') -- или LOWER(Name) LIKE LOWER(N'Пет%')
SELECT ID,LastName
FROM Employees
WHERE UPPER(LastName)=UPPER(N'Петров') -- или LOWER(LastName)=LOWER(N'Петров')
Немного о датах
При проверке на дату, вы можете использовать, как и со строками одинарные кавычки ‘…’.
Вне зависимости от региональных настроек в MS SQL можно использовать следующий синтаксис дат ‘YYYYMMDD’ (год, месяц, день слитно без пробелов). Такой формат даты MS SQL поймет всегда:
SELECT ID,Name,Birthday
FROM Employees
WHERE Birthday BETWEEN '19800101' AND '19891231' -- сотрудники 80-х годов
ORDER BY Birthday
В некоторых случаях, дату удобнее задавать при помощи функции DATEFROMPARTS:
SELECT ID,Name,Birthday
FROM Employees
WHERE Birthday BETWEEN DATEFROMPARTS(1980,1,1) AND DATEFROMPARTS(1989,12,31)
ORDER BY Birthday
Так же есть аналогичная функция DATETIMEFROMPARTS, которая служит для задания Даты и Времени (для типа datetime).
Еще вы можете использовать функцию CONVERT, если требуется преобразовать строку в значение типа date или datetime:
SELECT
CONVERT(date,'12.03.2015',104),
CONVERT(datetime,'2014-11-30 17:20:15',120)
Значения 104 и 120, указывают какой формат даты используется в строке. Описание всех допустимых форматов вы можете найти в библиотеке MSDN задав в поиске «MS SQL CONVERT».
Функций для работы с датами в MS SQL очень много, ищите «ms sql функции для работы с датами».
Примечание. Во всех диалектах языка SQL свой набор функций по работе с датами и применяется свой подход по работе с ними.
Немного о числах и их преобразованиях
Информация этого раздела наверно больше будет полезна ИТ-специалистам. Если вы таковым не являетесь, а ваша цель просто научится писать запросы для получения из БД необходимой вам информации, то такие тонкости вам возможно и не понадобятся, но в любом случае можете бегло пройтись по тексту и взять что-то на заметку, т.к. если вы взялись за изучение SQL, то вы уже приобщаетесь к ИТ.
В отличие от функции преобразования CAST, в функции CONVERT можно задать третий параметр, который отвечает за стиль преобразования (формат). Для разных типов данных может использоваться свой набор стилей, которые могут повлиять на возвращаемый результат. Использование стилей мы уже затрагивали при рассмотрении преобразования строки функцией CONVERT в типы date и datetime.
Подробней про функции CAST, CONVERT и стили можно почитать в MSDN – «Функции CAST и CONVERT (Transact-SQL)»: msdn.microsoft.com/ru-ru/library/ms187928.aspx
Для упрощения примеров здесь будут использованы инструкции языка Transact-SQL – DECLARE и SET.
Конечно, в случае преобразования целого числа в вещественное (которое я привел вначале данного урока, в целях демонстрации разницы между целочисленным и вещественным делением), знание нюансов преобразования не так критично, т.к. там мы делали преобразование целого числа в вещественное (диапазон которого намного больше диапазона целых):
DECLARE @min_int int SET @min_int=-2147483648
DECLARE @max_int int SET @max_int=2147483647
SELECT
-- (-2147483648)
@min_int,CAST(@min_int AS float),CONVERT(float,@min_int),
-- 2147483647
@max_int,CAST(@max_int AS float),CONVERT(float,@max_int),
-- numeric(16,6)
@min_int/1., -- (-2147483648.000000)
@max_int/1. -- 2147483647.000000
Возможно не стоило указывать способ неявного преобразования, получаемого делением на (1.), т.к. желательно стараться делать явные преобразования, для большего контроля типа получаемого результата. Хотя, в случае, если мы хотим получить результат типа numeric, с указанным количеством цифр после запятой, то мы можем в MS SQL применить трюк с умножением целого значения на (1., 1.0, 1.00 и т.д):
DECLARE @int int SET @int=123
SELECT
@int*1., -- numeric(12, 0) - 0 знаков после запятой
@int*1.0, -- numeric(13, 1) - 1 знак
@int*1.00, -- numeric(14, 2) - 2 знака
-- хотя порой лучше сделать явное преобразование
CAST(@int AS numeric(20, 0)), -- 123
CAST(@int AS numeric(20, 1)), -- 123.0
CAST(@int AS numeric(20, 2)) -- 123.00
В некоторых случаях детали преобразования могут быть действительно важны, т.к. они влияют на правильность полученного результата, например, в случае, когда делается преобразование числового значения в строку (varchar). Рассмотрим примеры по преобразованию значений типа money и float в varchar:
-- поведение при преобразовании money в varchar
DECLARE @money money
SET @money = 1025.123456789 -- произойдет неявное преобразование в 1025.1235, т.к. тип money хранит только 4 цифры после запятой
SELECT
@money, -- 1025.1235
-- по умолчанию CAST и CONVERT ведут себя одинаково (т.е. грубо говоря применяется стиль 0)
CAST(@money as varchar(20)), -- 1025.12
CONVERT(varchar(20), @money), -- 1025.12
CONVERT(varchar(20), @money, 0), -- 1025.12 (стиль 0 - без разделителя тысячных и 2 цифры после запятой (формат по умолчанию))
CONVERT(varchar(20), @money, 1), -- 1,025.12 (стиль 1 - используется разделитель тысячных и 2 цифры после запятой)
CONVERT(varchar(20), @money, 2) -- 1025.1235 (стиль 2 - без разделителя и 4 цифры после запятой)
-- поведение при преобразовании float в varchar
DECLARE @float1 float SET @float1 = 1025.123456789
DECLARE @float2 float SET @float2 = 1231025.123456789
SELECT
@float1, -- 1025.123456789
@float2, -- 1231025.12345679
-- по умолчанию CAST и CONVERT ведут себя одинаково (т.е. грубо говоря применяется стиль 0)
-- стиль 0 - Не более 6 разрядов. По необходимости используется экспоненциальное представление чисел
-- при преобразовании в varchar здесь творятся действительно страшные вещи
CAST(@float1 as varchar(20)), -- 1025.12
CONVERT(varchar(20), @float1), -- 1025.12
CONVERT(varchar(20), @float1, 0), -- 1025.12
CAST(@float2 as varchar(20)), -- 1.23103e+006
CONVERT(varchar(20), @float2), -- 1.23103e+006
CONVERT(varchar(20), @float2, 0), -- 1.23103e+006
-- стиль 1 - Всегда 8 разрядов. Всегда используется экспоненциальное представление чисел.
-- этот стиль для float тоже не очень точен
CONVERT(varchar(20), @float1, 1), -- 1.0251235e+003
CONVERT(varchar(20), @float2, 1), -- 1.2310251e+006
-- стиль 2 - Всегда 16 разрядов. Всегда используется экспоненциальное представление чисел.
-- здесь с точностью уже получше
CONVERT(varchar(30), @float1, 2), -- 1.025123456789000e+003 - OK
CONVERT(varchar(30), @float2, 2) -- 1.231025123456789e+006 - OK
Как видно из примера, плавающие типы float, real в некоторых случаях действительно могут создать большую погрешность, особенно при перегонке в строку и обратно (такое может быть при разного рода интеграциях, когда данные, например, передаются в текстовых файлах из одной системы в другую).
Если нужно явно контролировать точность до определенного знака, более 4-х, то для хранения данных, порой лучше использовать тип decimal/numeric. Если хватает 4-х знаков, то можно использовать и тип money – он примерно соотвествует numeric(20,4).
-- decimal и numeric
DECLARE @money money SET @money = 1025.123456789 -- 1025.1235
DECLARE @float1 float SET @float1 = 1025.123456789
DECLARE @float2 float SET @float2 = 1231025.123456789
DECLARE @numeric numeric(28,9) SET @numeric = 1025.123456789
SELECT
CAST(@numeric as varchar(20)), -- 1025.12345679
CONVERT(varchar(20), @numeric), -- 1025.12345679
CAST(@money as numeric(28,9)), -- 1025.123500000
CAST(@float1 as numeric(28,9)), -- 1025.123456789
CAST(@float2 as numeric(28,9)) -- 1231025.123456789
Примечание.
С версии MS SQL 2008, можно использовать вместо конструкции:DECLARE @money money SET @money = 1025.123456789Более короткий синтаксис инициализации переменных:
DECLARE @money money = 1025.123456789
Заключение второй части
В этой части, я постарался вспомнить и отразить наиболее важные моменты, касающиеся базового синтаксиса. Базовая конструкция – это костяк, без которого нельзя приступать к изучению более сложных конструкций языка SQL.
Надеюсь, данный материал поможет людям, делающим первые шаги в изучении языка SQL.
Удачи в изучении и применении на практике данного языка.
Часть третья — habrahabr.ru/post/255825
 Поиск
Поиск- Помощь
- Участники
 Регистрация
Регистрация- Вход
- Начало
Начало » Использование СУБД » Microsoft SQL Server » Создание таблицы в Microsoft SQL Server Management Studio
|
Показать: Сегодняшние сообщения :: Голосования :: Навигатор по сообщениям Отправить по e-mail |
|
|
|||||||||||
|
|||||||||||
|
|||||||||||
|
|||||||||||
|

| Предыдущая тема: | Репликация SQL 2008 на SQL 2000 |
| Следующая тема: | вывод таблицы с пустыми полями |
Переход к форуму:
-=] Вернуться вверх [=-
[ Сформировать XML ] [ ![]() ] [
] [  ]
]
Текущее время: Mon Jul 17 06:57:44 MSK 2023
Общее время, затраченное на создание страницы: 0.01861 секунд
замечания
Это набор примеров, подчеркивающих базовое использование SQL Server.
Версии
| Версия | Дата выхода |
|---|---|
| SQL Server 2016 | 2016-06-01 |
| SQL Server 2014 | 2014-03-18 |
| SQL Server 2012 | 2011-10-11 |
| SQL Server 2008 R2 | 2010-04-01 |
| SQL Server 2008 | 2008-08-06 |
| SQL Server 2005 | 2005-11-01 |
| SQL Server 2000 | 2000-11-01 |
INSERT / SELECT / UPDATE / DELETE: основы языка манипулирования данными
D ata M anipulation L anguage (короткий для DML) включает такие операции, как INSERT , UPDATE и DELETE :
-- Create a table HelloWorld
CREATE TABLE HelloWorld (
Id INT IDENTITY,
Description VARCHAR(1000)
)
-- DML Operation INSERT, inserting a row into the table
INSERT INTO HelloWorld (Description) VALUES ('Hello World')
-- DML Operation SELECT, displaying the table
SELECT * FROM HelloWorld
-- Select a specific column from table
SELECT Description FROM HelloWorld
-- Display number of records in the table
SELECT Count(*) FROM HelloWorld
-- DML Operation UPDATE, updating a specific row in the table
UPDATE HelloWorld SET Description = 'Hello, World!' WHERE Id = 1
-- Selecting rows from the table (see how the Description has changed after the update?)
SELECT * FROM HelloWorld
-- DML Operation - DELETE, deleting a row from the table
DELETE FROM HelloWorld WHERE Id = 1
-- Selecting the table. See table content after DELETE operation
SELECT * FROM HelloWorld
В этом скрипте мы создаем таблицу для демонстрации некоторых основных запросов.
В следующих примерах показано, как запрашивать таблицы:
USE Northwind;
GO
SELECT TOP 10 * FROM Customers
ORDER BY CompanyName
выберет первые 10 записей таблицы Customer , упорядоченные столбцом CompanyName из базы данных Northwind (которая является одной из примерных баз данных Microsoft, ее можно загрузить отсюда ):

Обратите внимание, что Use Northwind; изменяет базу данных по умолчанию для всех последующих запросов. Вы все равно можете ссылаться на базу данных, используя полный синтаксис в форме [Database]. [Схема]. [Таблица]:
SELECT TOP 10 * FROM Northwind.dbo.Customers
ORDER BY CompanyName
SELECT TOP 10 * FROM Pubs.dbo.Authors
ORDER BY City
Это полезно, если вы запрашиваете данные из разных баз данных. Обратите внимание, что dbo , заданный «in between», называется схемой и должен быть указан при использовании полного синтаксиса. Вы можете думать о нем как о папке в своей базе данных. dbo — это схема по умолчанию. Схема по умолчанию может быть опущена. Все остальные пользовательские схемы должны быть указаны.
Если таблица базы данных содержит столбцы, имена которых называются зарезервированными словами, например Date , вам нужно заключить имя столбца в скобки, например:
-- descending order
SELECT TOP 10 [Date] FROM dbo.MyLogTable
ORDER BY [Date] DESC
То же самое относится, если имя столбца содержит пробелы в имени (что не рекомендуется). Альтернативный синтаксис заключается в использовании двойных кавычек вместо квадратных скобок, например:
-- descending order
SELECT top 10 "Date" from dbo.MyLogTable
order by "Date" desc
эквивалентен, но не так часто используется. Обратите внимание на разницу между двойными кавычками и одинарными кавычками: одинарные кавычки используются для строк, т. Е.
-- descending order
SELECT top 10 "Date" from dbo.MyLogTable
where UserId='johndoe'
order by "Date" desc
является допустимым синтаксисом. Обратите внимание, что T-SQL имеет префикс N для типов данных NChar и NVarchar, например
SELECT TOP 10 * FROM Northwind.dbo.Customers
WHERE CompanyName LIKE N'AL%'
ORDER BY CompanyName
возвращает все компании, имеющие название компании, начиная с AL ( % — это дикая карта, используйте ее так же, как вы бы использовали звездочку в командной строке DOS, например DIR AL* ). Для LIKE существует несколько подстановочных знаков, посмотрите здесь, чтобы узнать подробности.
присоединяется
Соединения полезны, если вы хотите запрашивать поля, которые не существуют в одной таблице, но в нескольких таблицах. Например: вы хотите запросить все столбцы из таблицы Region в базе данных Northwind . Но вы заметили, что вам нужен также RegionDescription , который хранится в другой таблице Region . Тем не менее, существует общий ключ RgionID который можно использовать для объединения этой информации в один запрос следующим образом ( Top 5 просто возвращает первые 5 строк, опустите его, чтобы получить все строки):
SELECT TOP 5 Territories.*,
Regions.RegionDescription
FROM Territories
INNER JOIN Region
ON Territories.RegionID=Region.RegionID
ORDER BY TerritoryDescription
будут показаны все столбцы из Territories и столбец RegionDescription из Region . Результат упорядочен по TerritoryDescription .
Псевдонимы таблиц
Когда ваш запрос требует ссылки на две или более таблицы, вы можете счесть полезным использовать псевдоним таблицы. Табличные псевдонимы — это сокращенные ссылки на таблицы, которые можно использовать вместо полного имени таблицы, и могут уменьшить типизацию и редактирование. Синтаксис для использования псевдонима:
<TableName> [as] <alias>
Где as необязательное ключевое слово. Например, предыдущий запрос можно переписать как:
SELECT TOP 5 t.*,
r.RegionDescription
FROM Territories t
INNER JOIN Region r
ON t.RegionID = r.RegionID
ORDER BY TerritoryDescription
Псевдонимы должны быть уникальными для всех таблиц в запросе, даже если вы используете одну и ту же таблицу дважды. Например, если в таблице Employee указано поле SupervisorId, вы можете использовать этот запрос для возврата сотрудника и его имени руководителя:
SELECT e.*,
s.Name as SupervisorName -- Rename the field for output
FROM Employee e
INNER JOIN Employee s
ON e.SupervisorId = s.EmployeeId
WHERE e.EmployeeId = 111
Союзы
Как мы видели ранее, объединение добавляет столбцы из разных источников таблицы. Но что, если вы хотите объединить строки из разных источников? В этом случае вы можете использовать UNION. Предположим, вы планируете вечеринку и хотите пригласить не только сотрудников, но и клиентов. Затем вы можете запустить этот запрос, чтобы сделать это:
SELECT FirstName+' '+LastName as ContactName, Address, City FROM Employees
UNION
SELECT ContactName, Address, City FROM Customers
Он будет возвращать имена, адреса и города от сотрудников и клиентов в одной таблице. Обратите внимание, что дублирующиеся строки (если они должны быть какие-либо) автоматически удаляются (если вы этого не хотите, используйте вместо этого UNION ALL ). Номер столбца, имена столбцов, порядок и тип данных должны соответствовать всем операторам выбора, которые являются частью объединения, поэтому первый SELECT объединяет FirstName и LastName от Employee в ContactName .
Переменные таблицы
Это может быть полезно, если вам нужно иметь дело с временными данными (особенно в хранимой процедуре), использовать табличные переменные: разница между «реальной» таблицей и табличной переменной заключается в том, что она существует только в памяти для временной обработки.
Пример:
DECLARE @Region TABLE
(
RegionID int,
RegionDescription NChar(50)
)
создает таблицу в памяти. В этом случае префикс @ является обязательным, поскольку он является переменной. Вы можете выполнить все операции DML, упомянутые выше, для вставки, удаления и выбора строк, например
INSERT INTO @Region values(3,'Northern')
INSERT INTO @Region values(4,'Southern')
Но, как правило, вы заполняете его на основе реальной таблицы, например
INSERT INTO @Region
SELECT * FROM dbo.Region WHERE RegionID>2;
который будет считывать отфильтрованные значения из реальной таблицы dbo.Region и вставлять их в таблицу памяти @Region где ее можно использовать для дальнейшей обработки. Например, вы можете использовать его в
SELECT * FROM Territories t
JOIN @Region r on t.RegionID=r.RegionID
которая в этом случае вернет все Northern и Southern территории. Более подробную информацию можно найти здесь . Временные таблицы обсуждаются здесь , если вам интересно узнать больше об этой теме.
ПРИМЕЧАНИЕ. Microsoft рекомендует использовать переменные таблицы, если количество строк данных в переменной таблицы меньше 100. Если вы будете работать с большими объемами данных, вместо этого используйте временную таблицу или таблицу temp.
РАСПЕЧАТАТЬ
Отображение сообщения на выходной консоли. Используя SQL Server Management Studio, это будет отображаться на вкладке сообщений, а не на вкладке результатов:
PRINT 'Hello World!';
ВЫБРАТЬ все строки и столбцы из таблицы
Синтаксис:
SELECT *
FROM table_name
Использование оператора asterisk * служит ярлыком для выбора всех столбцов в таблице. Все строки также будут выбраны, потому что этот SELECT не имеет предложения WHERE , чтобы указать любые критерии фильтрации.
Это также будет работать так же, если вы добавили псевдоним в таблицу, например e в этом случае:
SELECT *
FROM Employees AS e
Или, если вы хотите выбрать все из конкретной таблицы, вы можете использовать псевдоним + «. *»:
SELECT e.*, d.DepartmentName
FROM Employees AS e
INNER JOIN Department AS d
ON e.DepartmentID = d.DepartmentID
К объектам базы данных также можно получить доступ с использованием полных имен:
SELECT * FROM [server_name].[database_name].[schema_name].[table_name]
Это не обязательно рекомендуется, так как изменение имени сервера и / или базы данных приведет к тому, что запросы с использованием полностью квалифицированных имен перестанут выполняться из-за неправильных имен объектов.
Обратите внимание, что поля before table_name могут быть опущены во многих случаях, если запросы выполняются на одном сервере, базе данных и схеме соответственно. Однако для базы данных часто существует несколько схем, и в этих случаях имя схемы не должно быть опущено, когда это возможно.
Предупреждение. Использование SELECT * в производственном коде или хранимых процедурах может привести к проблемам позже (при добавлении новых столбцов в таблицу или перестановке столбцов в таблице), особенно если ваш код делает простые предположения о порядке столбцов, или количество возвращенных столбцов. Поэтому безопаснее всегда явно указывать имена столбцов в операторах SELECT для производственного кода.
SELECT col1, col2, col3
FROM table_name
Выберите строки, соответствующие условию
Как правило, синтаксис:
SELECT <column names>
FROM <table name>
WHERE <condition>
Например:
SELECT FirstName, Age
FROM Users
WHERE LastName = 'Smith'
Условия могут быть сложными:
SELECT FirstName, Age
FROM Users
WHERE LastName = 'Smith' AND (City = 'New York' OR City = 'Los Angeles')
UPDATE Specific Row
UPDATE HelloWorlds
SET HelloWorld = 'HELLO WORLD!!!'
WHERE Id = 5
Вышеупомянутый код обновляет значение поля «HelloWorld» с «HELLO WORLD !!!» для записи, где «Id = 5» в таблице HelloWorlds.
Примечание. В операторе обновления рекомендуется использовать предложение «где», чтобы избежать обновления всей таблицы, пока и до тех пор, пока ваше требование не будет отличаться.
ОБНОВЛЕНИЕ ВСЕХ строк
Простая форма обновления увеличивает все значения в заданном поле таблицы. Для этого нам нужно определить поле и значение приращения
Ниже приведен пример, который увеличивает поле « Score на 1 (во всех строках):
UPDATE Scores
SET score = score + 1
Это может быть опасно, так как вы можете повредить свои данные, если вы случайно внесете UPDATE для определенной строки со строками UPDATE для всех в таблице.
Комментарии в коде
Transact-SQL поддерживает две формы написания комментариев. Комментарии игнорируются движком базы данных и предназначены для чтения людьми.
Комментарии предшествуют -- и игнорируются до тех пор, пока не встретится новая строка:
-- This is a comment
SELECT *
FROM MyTable -- This is another comment
WHERE Id = 1;
Комментарии к слайду начинаются с /* и заканчиваются на */ . Весь текст между этими разделителями рассматривается как блок комментариев.
/* This is
a multi-line
comment block. */
SELECT Id = 1, [Message] = 'First row'
UNION ALL
SELECT 2, 'Second row'
/* This is a one liner */
SELECT 'More';
Замечания звезд Slash имеют то преимущество, что комментарий может использоваться, если SQL Statement теряет новые строковые символы. Это может произойти при захвате SQL во время устранения неполадок.
Комментарии к Slash star могут быть вложенными, а начало /* внутри комментария слэш-символом должно заканчиваться на */ чтобы быть действительным. Следующий код приведет к ошибке
/*
SELECT *
FROM CommentTable
WHERE Comment = '/*'
*/
Слэш-звезда, хотя внутри цитаты считается началом комментария. Следовательно, его нужно закончить с помощью другой закрывающей звезды. Правильный путь
/*
SELECT *
FROM CommentTable
WHERE Comment = '/*'
*/ */
Получить базовую информацию о сервере
SELECT @@VERSION
Возвращает версию MS SQL Server, запущенную на экземпляре.
SELECT @@SERVERNAME
Возвращает имя экземпляра MS SQL Server.
SELECT @@SERVICENAME
Возвращает имя службы Windows. MS SQL Server работает как.
SELECT serverproperty('ComputerNamePhysicalNetBIOS');
Возвращает физическое имя машины, на которой работает SQL Server. Полезно для идентификации узла в отказоустойчивом кластере.
SELECT * FROM fn_virtualservernodes();
В отказоустойчивом кластере возвращается каждый узел, на котором может работать SQL Server. Он не возвращает ничего, если не кластер.
Использование транзакций для безопасного изменения данных
Всякий раз, когда вы меняете данные, в команде Data Manipulation Language (DML) вы можете обернуть свои изменения в транзакции. DML включает UPDATE , TRUNCATE , INSERT и DELETE . Один из способов, которым вы можете убедиться, что вы меняете правильные данные, — это использовать транзакцию.
Изменения DML будут блокировать затронутые строки. Когда вы начинаете транзакцию, вы должны завершить транзакцию, или все объекты, которые будут изменены в DML, останутся заблокированными тем, кто начал транзакцию. Вы можете завершить транзакцию с помощью ROLLBACK или COMMIT . ROLLBACK возвращает все транзакции в исходное состояние. COMMIT помещает данные в конечное состояние, где вы не можете отменить свои изменения без другого оператора DML.
Пример:
--Create a test table
USE [your database]
GO
CREATE TABLE test_transaction (column_1 varchar(10))
GO
INSERT INTO
dbo.test_transaction
( column_1 )
VALUES
( 'a' )
BEGIN TRANSACTION --This is the beginning of your transaction
UPDATE dbo.test_transaction
SET column_1 = 'B'
OUTPUT INSERTED.*
WHERE column_1 = 'A'
ROLLBACK TRANSACTION --Rollback will undo your changes
--Alternatively, use COMMIT to save your results
SELECT * FROM dbo.test_transaction --View the table after your changes have been run
DROP TABLE dbo.test_transaction
Заметки:
- Это упрощенный пример, который не включает обработку ошибок. Но любая операция базы данных может выйти из строя и, следовательно, вызвать исключение. Вот пример того, как может выглядеть такая необходимая обработка ошибок. Вы никогда не должны использовать транзакции без обработчика ошибок , иначе вы можете оставить транзакцию в неизвестном состоянии.
- В зависимости от уровня изоляции транзакции помещают блокировки на запрашиваемые или измененные данные. Вам необходимо убедиться, что транзакции не работают в течение длительного времени, поскольку они будут блокировать записи в базе данных и могут привести к взаимоблокировкам с другими параллельными транзакциями. Держите операции, заключенные в транзакции как можно короче, и минимизируйте влияние количества данных, которые вы блокируете.
УДАЛИТЬ ВСЕ строки
DELETE
FROM Helloworlds
Это приведет к удалению всех данных из таблицы. После запуска этого кода таблица не будет содержать строк. В отличие от DROP TABLE , это сохраняет таблицу и ее структуру, и вы можете продолжать вставлять новые строки в эту таблицу.
Другой способ удалить все строки в таблице — усечь его, как показано ниже:
TRUNCATE TABLE HelloWords
Разница с операцией DELETE несколько:
- Операция Truncate не сохраняется в файле журнала транзакций
- Если существует поле
IDENTITY, это будет сброшено - TRUNCATE может применяться на всей таблице, а не на части (вместо этого с помощью команды
DELETEвы можете связать предложениеWHERE)
Ограничения TRUNCATE
- Невозможно TRUNCATE таблицы, если есть ссылка
FOREIGN KEY - Если в таблице участвуют
INDEXED VIEW - Если таблица публикуется с использованием
TRANSACTIONAL REPLICATIONилиMERGE REPLICATION - Он не будет запускать любой TRIGGER, определенный в таблице
[так в оригинале]
TRUNCATE TABLE
TRUNCATE TABLE Helloworlds
Этот код удалит все данные из таблицы Helloworlds. Таблица усечений почти аналогична Delete from Table . Разница в том, что вы не можете использовать where clauses с Truncate. Таблица усечения считается лучше, чем удаление, поскольку она использует меньше пространства журналов транзакций.
Обратите внимание, что если столбец идентификатора существует, он сбрасывается до начального начального значения (например, автоматически увеличиваемый ID будет перезапущен с 1). Это может привести к несогласованности, если столбцы идентификации используются в качестве внешнего ключа в другой таблице.
Создать новую таблицу и вставить записи из старой таблицы
SELECT * INTO NewTable FROM OldTable
Создает новую таблицу со структурой старой таблицы и вставляет все строки в новую таблицу.
Некоторые ограничения
- Вы не можете указать в качестве новой таблицы переменную таблицы или таблицы.
- Вы не можете использовать SELECT … INTO для создания секционированной таблицы, даже если исходная таблица разделена. SELECT … INTO не использует схему раздела исходной таблицы; вместо этого новая таблица создается в файловой группе по умолчанию. Чтобы вставлять строки в секционированную таблицу, вы должны сначала создать секционированную таблицу, а затем использовать инструкцию INSERT INTO … SELECT FROM.
- Индексы, ограничения и триггеры, определенные в исходной таблице, не переносятся в новую таблицу и не могут быть указаны в инструкции SELECT … INTO. Если эти объекты необходимы, их можно создать после выполнения инструкции SELECT … INTO.
- Указание предложения ORDER BY не гарантирует, что строки будут вставлены в указанном порядке. Когда разреженный столбец включен в список выбора, свойство разреженного столбца не переносится в столбец в новой таблице. Если это свойство требуется в новой таблице, измените определение столбца после выполнения инструкции SELECT … INTO, чтобы включить это свойство.
- Когда вычисленный столбец включен в список выбора, соответствующий столбец в новой таблице не является вычисленным столбцом. Значения в новом столбце — это значения, которые были вычислены в момент выполнения SELECT … INTO.
[ sic ]
Получение таблицы Row Count
Следующий пример может быть использован , чтобы найти общее количество строк для конкретной таблицы в базе данных , если table_name заменяется таблицами , которую вы хотите запросить:
SELECT COUNT(*) AS [TotalRowCount] FROM table_name;
Также можно получить подсчет строк для всех таблиц, присоединившись к разделу таблицы, основываясь на таблицах HEAP (index_id = 0) или кластерном индексе кластера (index_id = 1), используя следующий скрипт:
SELECT [Tables].name AS [TableName],
SUM( [Partitions].[rows] ) AS [TotalRowCount]
FROM sys.tables AS [Tables]
JOIN sys.partitions AS [Partitions]
ON [Tables].[object_id] = [Partitions].[object_id]
AND [Partitions].index_id IN ( 0, 1 )
--WHERE [Tables].name = N'table name' /* uncomment to look for a specific table */
GROUP BY [Tables].name;
Это возможно, так как каждая таблица по существу является отдельной таблицей разделов, если к ней не добавляются дополнительные разделы. Этот скрипт также имеет преимущество не вмешиваться в операции чтения / записи в строки таблиц.